前言
上一篇【.Net Core微服務入門全紀錄(二)——Consul-服務註冊與發現(上)】已經成功將我們的服務註冊到Consul中,接下來就該客戶端通過Consul去做服務發現了。
服務發現
-
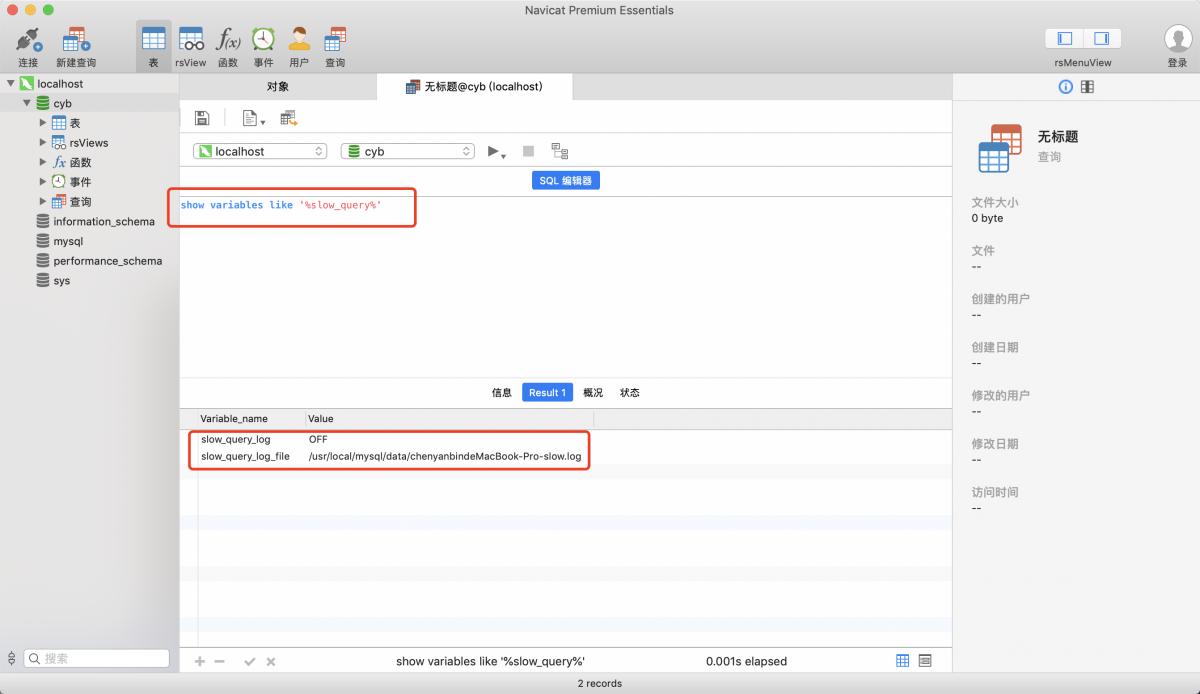
同樣Nuget安裝一下Consul:
-
改造一下業務系統的代碼:
ServiceHelper.cs:
public class ServiceHelper : IServiceHelper
{
private readonly IConfiguration _configuration;
public ServiceHelper(IConfiguration configuration)
{
_configuration = configuration;
}
public async Task<string> GetOrder()
{
//string[] serviceUrls = { "http://localhost:9060", "http://localhost:9061", "http://localhost:9062" };//訂單服務的地址,可以放在配置文件或者數據庫等等...
var consulClient = new ConsulClient(c =>
{
//consul地址
c.Address = new Uri(_configuration["ConsulSetting:ConsulAddress"]);
});
//consulClient.Catalog.Services().Result.Response;
//consulClient.Agent.Services().Result.Response;
var services = consulClient.Health.Service("OrderService", null, true, null).Result.Response;//健康的服務
string[] serviceUrls = services.Select(p => $"http://{p.Service.Address + ":" + p.Service.Port}").ToArray();//訂單服務地址列表
if (!serviceUrls.Any())
{
return await Task.FromResult("【訂單服務】服務列表為空");
}
//每次隨機訪問一個服務實例
var Client = new RestClient(serviceUrls[new Random().Next(0, serviceUrls.Length)]);
var request = new RestRequest("/orders", Method.GET);
var response = await Client.ExecuteAsync(request);
return response.Content;
}
public async Task<string> GetProduct()
{
//string[] serviceUrls = { "http://localhost:9050", "http://localhost:9051", "http://localhost:9052" };//產品服務的地址,可以放在配置文件或者數據庫等等...
var consulClient = new ConsulClient(c =>
{
//consul地址
c.Address = new Uri(_configuration["ConsulSetting:ConsulAddress"]);
});
//consulClient.Catalog.Services().Result.Response;
//consulClient.Agent.Services().Result.Response;
var services = consulClient.Health.Service("ProductService", null, true, null).Result.Response;//健康的服務
string[] serviceUrls = services.Select(p => $"http://{p.Service.Address + ":" + p.Service.Port}").ToArray();//產品服務地址列表
if (!serviceUrls.Any())
{
return await Task.FromResult("【產品服務】服務列表為空");
}
//每次隨機訪問一個服務實例
var Client = new RestClient(serviceUrls[new Random().Next(0, serviceUrls.Length)]);
var request = new RestRequest("/products", Method.GET);
var response = await Client.ExecuteAsync(request);
return response.Content;
}
}
appsettings.json:
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft": "Warning",
"Microsoft.Hosting.Lifetime": "Information"
}
},
"AllowedHosts": "*",
"ConsulSetting": {
"ConsulAddress": "http://localhost:8500"
}
}
OK,以上代碼就完成了服務列表的獲取。
瀏覽器測試一下:
隨便停止2個服務:
繼續訪問:
這時候停止的服務地址就獲取不到了,客戶端依然正常運行。
這時候解決了服務的發現,新的問題又來了…
- 客戶端每次要調用服務,都先去Consul獲取一下地址,這不僅浪費資源,還增加了請求的響應時間,這顯然讓人無法接受。
那麼怎麼保證不要每次請求都去Consul獲取地址,同時又要拿到可用的地址列表呢?
Consul提供的解決方案:——Blocking Queries (阻塞的請求)。詳情請見官網:https://www.consul.io/api-docs/features/blocking
Blocking Queries
這是什麼意思呢,簡單來說就是當客戶端請求Consul獲取地址列表時,需要攜帶一個版本號信息,Consul會比較這個客戶端版本號是否和Consul服務端的版本號一致,如果一致,則Consul會阻塞這個請求,直到Consul中的服務列表發生變化,或者到達阻塞時間上限;如果版本號不一致,則立即返回。這個阻塞時間默認是5分鐘,支持自定義。
那麼我們另外啟動一個線程去干這件事情,就不會影響每次的用戶請求了。這樣既保證了客戶端服務列表的準確性,又節約了客戶端請求服務列表的次數。
- 繼續改造代碼:
IServiceHelper增加一個獲取服務列表的接口方法:
public interface IServiceHelper
{
/// <summary>
/// 獲取產品數據
/// </summary>
/// <returns></returns>
Task<string> GetProduct();
/// <summary>
/// 獲取訂單數據
/// </summary>
/// <returns></returns>
Task<string> GetOrder();
/// <summary>
/// 獲取服務列表
/// </summary>
void GetServices();
}
ServiceHelper實現接口:
public class ServiceHelper : IServiceHelper
{
private readonly IConfiguration _configuration;
private readonly ConsulClient _consulClient;
private ConcurrentBag<string> _orderServiceUrls;
private ConcurrentBag<string> _productServiceUrls;
public ServiceHelper(IConfiguration configuration)
{
_configuration = configuration;
_consulClient = new ConsulClient(c =>
{
//consul地址
c.Address = new Uri(_configuration["ConsulSetting:ConsulAddress"]);
});
}
public async Task<string> GetOrder()
{
if (_productServiceUrls == null)
return await Task.FromResult("【訂單服務】正在初始化服務列表...");
//每次隨機訪問一個服務實例
var Client = new RestClient(_orderServiceUrls.ElementAt(new Random().Next(0, _orderServiceUrls.Count())));
var request = new RestRequest("/orders", Method.GET);
var response = await Client.ExecuteAsync(request);
return response.Content;
}
public async Task<string> GetProduct()
{
if(_productServiceUrls == null)
return await Task.FromResult("【產品服務】正在初始化服務列表...");
//每次隨機訪問一個服務實例
var Client = new RestClient(_productServiceUrls.ElementAt(new Random().Next(0, _productServiceUrls.Count())));
var request = new RestRequest("/products", Method.GET);
var response = await Client.ExecuteAsync(request);
return response.Content;
}
public void GetServices()
{
var serviceNames = new string[] { "OrderService", "ProductService" };
Array.ForEach(serviceNames, p =>
{
Task.Run(() =>
{
//WaitTime默認為5分鐘
var queryOptions = new QueryOptions { WaitTime = TimeSpan.FromMinutes(10) };
while (true)
{
GetServices(queryOptions, p);
}
});
});
}
private void GetServices(QueryOptions queryOptions, string serviceName)
{
var res = _consulClient.Health.Service(serviceName, null, true, queryOptions).Result;
//控制台打印一下獲取服務列表的響應時間等信息
Console.WriteLine($"{DateTime.Now}獲取{serviceName}:queryOptions.WaitIndex:{queryOptions.WaitIndex} LastIndex:{res.LastIndex}");
//版本號不一致 說明服務列表發生了變化
if (queryOptions.WaitIndex != res.LastIndex)
{
queryOptions.WaitIndex = res.LastIndex;
//服務地址列表
var serviceUrls = res.Response.Select(p => $"http://{p.Service.Address + ":" + p.Service.Port}").ToArray();
if (serviceName == "OrderService")
_orderServiceUrls = new ConcurrentBag<string>(serviceUrls);
else if (serviceName == "ProductService")
_productServiceUrls = new ConcurrentBag<string>(serviceUrls);
}
}
}
Startup的Configure方法中調用一下獲取服務列表:
public void Configure(IApplicationBuilder app, IWebHostEnvironment env, IServiceHelper serviceHelper)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
else
{
app.UseExceptionHandler("/Home/Error");
}
app.UseStaticFiles();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllerRoute(
name: "default",
pattern: "{controller=Home}/{action=Index}/{id?}");
});
//程序啟動時 獲取服務列表
serviceHelper.GetServices();
}
代碼完成,運行測試:
現在不用每次先請求服務列表了,是不是流暢多了?
看一下控制台打印:
這時候如果服務列表沒有發生變化的話,獲取服務列表的請求會一直阻塞到我們設置的10分鐘。
隨便停止2個服務:
這時候可以看到,數據被立馬返回了。
繼續訪問客戶端網站,同樣流暢。
(gif圖傳的有點問題。。。)
至此,我們就通過Consul完成了服務的註冊與發現。
接下來又引發新的思考。。。
- 每個客戶端系統都去維護這一堆服務地址,合理嗎?
- 服務的ip端口直接暴露給所有客戶端,安全嗎?
- 這種模式下怎麼做到客戶端的統一管理呢?
…
代碼放在:https://github.com/xiajingren/NetCoreMicroserviceDemo
未完待續…
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益