本系列文章:
讀源碼,我們可以從第一行讀起
你知道Spring是怎麼解析配置類的嗎?
配置類為什麼要添加@Configuration註解?
談談Spring中的對象跟Bean,你知道Spring怎麼創建對象的嗎?
推薦閱讀:
Spring官網閱讀 | 總結篇
Spring雜談
本系列文章將會帶你一行行的將Spring的源碼吃透,推薦閱讀的文章是閱讀源碼的基礎!
前言
在前面的文章中已經知道了Spring是如何將一個對象創建出來的,那麼緊接着,Spring就需要將這個對象變成一個真正的Bean了,這個過程主要分為兩步
- 屬性注入
- 初始化
在這兩個過程中,Bean的後置處理器會穿插執行,其中有些後置處理器是為了幫助完成屬性注入或者初始化的,而有些後置處理器是Spring提供給程序員進行擴展的,當然,這二者並不衝突。整個Spring創建對象並將對象變成Bean的過程就是我們經常提到了Spring中Bean的生命周期。當然,本系列源碼分析的文章不會再對生命周期的概念做過多闡述了,如果大家有這方面的需求的話可以參考我之前的文章,或者關注我的公眾號:程序員DMZ
Spring官網閱讀(九)Spring中Bean的生命周期(上)
Spring官網閱讀(十)Spring中Bean的生命周期(下)
源碼分析
閑話不再多說,我們正式進入源碼分析階段,本文重點要分析的方法就是org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean,其源碼如下:
doCreateBean
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 創建對象的過程在上篇文章中我們已經介紹過了,這裏不再贅述
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 獲取到創建的這個對象
final Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Allow post-processors to modify the merged bean definition.
// 按照官方的註釋來說,這個地方是Spring提供的一個擴展點,對程序員而言,我們可以通過一個實現了MergedBeanDefinitionPostProcessor的後置處理器來修改bd中的屬性,從而影響到後續的Bean的生命周期
// 不過官方自己實現的後置處理器並沒有去修改bd,而是調用了applyMergedBeanDefinitionPostProcessors方法
// 這個方法名直譯過來就是-應用合併后的bd,也就是說它這裏只是對bd做了進一步的使用而沒有真正的修改
synchronized (mbd.postProcessingLock) {
// bd只允許被處理一次
if (!mbd.postProcessed) {
try {
// 應用合併后的bd
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
// 標註這個bd已經被MergedBeanDefinitionPostProcessor的後置處理器處理過
// 那麼在第二次創建Bean的時候,不會再次調用applyMergedBeanDefinitionPostProcessors
mbd.postProcessed = true;
}
}
// 這裡是用來出來循環依賴的,關於循環以來,在介紹完正常的Bean的創建后,單獨用一篇文章說明
// 這裏不做過多解釋
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
try {
// 我們這篇文章重點要分析的就是populateBean方法,在這個方法中完成了屬性注入
populateBean(beanName, mbd, instanceWrapper);
// 初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
// 省略異常代碼
}
// 後續代碼不在本文探討範圍內了,暫不考慮
return exposedObject;
}
applyMergedBeanDefinitionPostProcessors
源碼如下:
// 可以看到這個方法的代碼還是很簡單的,就是調用了MergedBeanDefinitionPostProcessor的postProcessMergedBeanDefinition方法
protected void applyMergedBeanDefinitionPostProcessors(RootBeanDefinition mbd, Class<?> beanType, String beanName) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof MergedBeanDefinitionPostProcessor) {
MergedBeanDefinitionPostProcessor bdp = (MergedBeanDefinitionPostProcessor) bp;
bdp.postProcessMergedBeanDefinition(mbd, beanType, beanName);
}
}
}
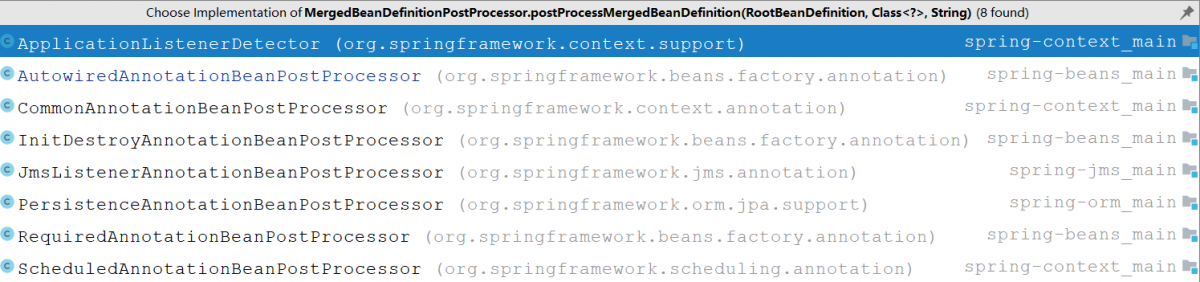
這個時候我們就要思考一個問題,容器中現在有哪些後置處理器是MergedBeanDefinitionPostProcessor呢?
查看這個方法的實現類我們會發現總共就這麼幾個類實現了MergedBeanDefinitionPostProcessor接口。實際上除了ApplicationListenerDetector之外,其餘的後置處理器的邏輯都差不多。我們在這裏我們主要就分析兩個後置處理
- ApplicationListenerDetector
- AutowiredAnnotationBeanPostProcessor
ApplicationListenerDetector
首先,我們來ApplicationListenerDetector,這個類在之前的文章中也多次提到過了,它的作用是用來處理嵌套Bean的情況,主要是保證能將嵌套在Bean標籤中的ApplicationListener也能添加到容器的監聽器集合中去。我們先通過一個例子來感受下這個後置處理器的作用吧
配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="com.dmz.source.populate.service.DmzService" id="dmzService">
<constructor-arg name="orderService">
<bean class="com.dmz.source.populate.service.OrderService"/>
</constructor-arg>
</bean>
</beans>
示例代碼:
// 事件
public class DmzEvent extends ApplicationEvent {
public DmzEvent(Object source) {
super(source);
}
}
public class DmzService {
OrderService orderService;
public DmzService(OrderService orderService) {
this.orderService = orderService;
}
}
// 實現ApplicationListener接口
public class OrderService implements ApplicationListener<DmzEvent> {
@Override
public void onApplicationEvent(DmzEvent event) {
System.out.println(event.getSource());
}
}
public class Main {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc = new ClassPathXmlApplicationContext("application-populate.xml");
cc.publishEvent(new DmzEvent("my name is dmz"));
}
}
// 程序運行結果,控制台打印:my name is dmz
說明OrderService已經被添加到了容器的監聽器集合中。但是請注意,在這種情況下,如果要使OrderService能夠執行監聽的邏輯,必須要滿足下面這兩個條件
- 外部的Bean要是單例的,對於我們的例子而言就是dmzService
- 內嵌的Bean也必須是單例的,在上面的例子中也就是orderService必須是單例
另外需要注意的是,這種嵌套的Bean比較特殊,它雖然由Spring創建,但是確不存在於容器中,就是說我們不能將其作為依賴注入到別的Bean中。
AutowiredAnnotationBeanPostProcessor
對應源碼如下:
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
// 找到注入的元數據,第一次是構建,後續可以直接從緩存中拿
// 註解元數據其實就是當前這個類中的所有需要進行注入的“點”的集合,
// 注入點(InjectedElement)包含兩種,字段/方法
// 對應的就是AutowiredFieldElement/AutowiredMethodElement
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
// 排除掉被外部管理的注入點
metadata.checkConfigMembers(beanDefinition);
}
上面代碼的核心邏輯就是
- 找到所有的注入點,其實就是被@Autowired註解修飾的方法以及字段,同時靜態的方法以及字段也會被排除
- 排除掉被外部管理的注入點,在後續的源碼分析中我們再細說
findAutowiringMetadata
// 這個方法的核心邏輯就是先從緩存中獲取已經解析好的注入點信息,很明顯,在原型情況下才會使用緩存
// 創建注入點的核心邏輯在buildAutowiringMetadata方法中
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) {
String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);
// 可能我們會修改bd中的class屬性,那麼InjectionMetadata中的注入點信息也需要刷新
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
// 這裏真正創建注入點
metadata = buildAutowiringMetadata(clazz);
this.injectionMetadataCache.put(cacheKey, metadata);
}
}
}
return metadata;
}
buildAutowiringMetadata
// 我們應用中使用@Autowired註解標註在字段上或者setter方法能夠完成屬性注入
// 就是因為這個方法將@Autowired註解標註的方法以及字段封裝成InjectionMetadata
// 在後續階段會調用InjectionMetadata的inject方法進行注入
private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz) {
List<InjectionMetadata.InjectedElement> elements = new ArrayList<>();
Class<?> targetClass = clazz;
do {
final List<InjectionMetadata.InjectedElement> currElements = new ArrayList<>();
// 處理所有的被@AutoWired/@Value註解標註的字段
ReflectionUtils.doWithLocalFields(targetClass, field -> {
AnnotationAttributes ann = findAutowiredAnnotation(field);
if (ann != null) {
// 靜態字段會直接跳過
if (Modifier.isStatic(field.getModifiers())) {
// 省略日誌打印
return;
}
// 得到@AutoWired註解中的required屬性
boolean required = determineRequiredStatus(ann);
currElements.add(new AutowiredFieldElement(field, required));
}
});
// 處理所有的被@AutoWired註解標註的方法,相對於字段而言,這裏需要對橋接方法進行特殊處理
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
// 只處理一種特殊的橋接場景,其餘的橋接方法都會被忽略
Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {
return;
}
AnnotationAttributes ann = findAutowiredAnnotation(bridgedMethod);
// 處理方法時需要注意,當父類中的方法被子類重寫時,如果子父類中的方法都加了@Autowired
// 那麼此時父類方法不能被處理,即不能被封裝成一個AutowiredMethodElement
if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {
if (Modifier.isStatic(method.getModifiers())) {
// 省略日誌打印
return;
}
if (method.getParameterCount() == 0) {
// 當方法的參數數量為0時,雖然不需要進行注入,但是還是會把這個方法作為注入點使用
// 這個方法最終還是會被調用
if (logger.isInfoEnabled()) {
logger.info("Autowired annotation should only be used on methods with parameters: " +
method);
}
}
boolean required = determineRequiredStatus(ann);
// PropertyDescriptor: 屬性描述符
// 就是通過解析getter/setter方法,例如void getA()會解析得到一個屬性名稱為a
// readMethod為getA的PropertyDescriptor,
// 在《Spring官網閱讀(十四)Spring中的BeanWrapper及類型轉換》文中已經做過解釋
// 這裏不再贅述,這裏之所以來這麼一次查找是因為當XML中對這個屬性進行了配置后,
// 那麼就不會進行自動注入了,XML中显示指定的屬性優先級高於註解
PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz); // 構造一個對應的AutowiredMethodElement,後續這個方法會被執行
// 方法的參數會被自動注入,這裏不限於setter方法
currElements.add(new AutowiredMethodElement(method, required, pd));
}
});
// 會處理父類中字段上及方法上的@AutoWired註解,並且父類的優先級比子類高
elements.addAll(0, currElements);
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
return new InjectionMetadata(clazz, elements);
}
難點代碼分析
上面的代碼整體來說應該很簡單,就如我們之前所說的,處理帶有@Autowired註解的字段及方法,同時會過濾掉所有的靜態字段及方法。上面複雜的地方在於對橋接方法的處理,可能大部分人都沒辦法理解這幾行代碼:
// 第一行
Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);
// 第二行
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {
return;
}
// 第三行
if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {
}
要理解這些代碼,首先你得知道什麼是橋接,為此我已經寫好了一篇文章:
Spring雜談 | 從橋接方法到JVM方法調用
除了在上面的文章中提到的橋接方法外,還有一種特殊的情況
// A類跟B類在同一個包下,A不是public的
class A {
public void test(){
}
}
// 在B中會生成一個跟A中的方法描述符(參數+返回值)一模一樣的橋接方法
// 這個橋接方法實際上就是調用父類中的方法
// 具體可以參考:https://bugs.java.com/bugdatabase/view_bug.do?bug_id=63424113
public class B extends A {
}
在理解了什麼是橋接之後,那麼上邊的第一行代碼你應該就能看懂了,就以上面的代碼為例,B中會生成一個橋接方法,對應的被橋接的方法就是A中的test方法。
接着,我們看看第二行代碼
public static boolean isVisibilityBridgeMethodPair(Method bridgeMethod, Method bridgedMethod) {
// 說明這個方法本身就不是橋接方法,直接返回true
if (bridgeMethod == bridgedMethod) {
return true;
}
// 說明是橋接方法,並且方法描述符一致
// 當且僅當是上面例子中描述的這種橋接的時候這個判斷才會滿足
// 正常來說橋接方法跟被橋接方法的返回值+參數類型肯定不一致
// 所以這個判斷會過濾掉其餘的所有類型的橋接方法
// 只會保留本文提及這種特殊情況下產生的橋接方法
return (bridgeMethod.getReturnType().equals(bridgedMethod.getReturnType()) &&
Arrays.equals(bridgeMethod.getParameterTypes(), bridgedMethod.getParameterTypes()));
}
最後,再來看看第三行代碼,核心就是這句 method.equals(ClassUtils.getMostSpecificMethod(method, clazz)。這句代碼的主要目的就是為了處理下面這種情況
@Component
public class D extends C {
@Autowired
@Override
public void setDmzService(DmzService dmzService) {
dmzService.init();
this.dmzService = dmzService;
}
}
// C不是Spring中的組件
public class C {
DmzService dmzService;
@Autowired
public void setDmzService(DmzService dmzService) {
this.dmzService = dmzService;
}
}
這種情況下,在處理D中的@Autowired註解時,雖然我們要處理父類中的@Autowired註解,但是因為子類中的方法已經複寫了父類中的方法,所以此時應該要跳過父類中的這個被複寫的方法,這就是第三行代碼的作用。
小結
到這裏我們主要分析了applyMergedBeanDefinitionPostProcessors這段代碼的作用,它的執行時機是在創建對象之後,屬性注入之前。按照官方的定義來說,到這裏我們仍然可以使用這個方法來修改bd的定義,那麼相對於通過BeanFactoryPostProcessor的方式修改bd,applyMergedBeanDefinitionPostProcessors這個方法影響的範圍更小,BeanFactoryPostProcessor影響的是整個Bean的生命周期,而applyMergedBeanDefinitionPostProcessors只會影響屬性注入之後的生命周期。
其次,我們分析了Spring中內置的MergedBeanDefinitionPostProcessor,選取了其中兩個特殊的後置處理器進行分析,其中ApplicationListenerDetector主要處理內嵌的事件監聽器,而AutowiredAnnotationBeanPostProcessor主要用於處理@Autowired註解,實際上我們會發現,到這裏還只是完成了@Autowired註解的解析,還沒有真正開始進行注入,真正注入的邏輯在後面我們要分析的populateBean方法中,在這個方法中會使用解析好的注入元信息完成真正的屬性注入,那麼接下來我們就開始分析populateBean這個方法的源碼。
populateBean
循環依賴的代碼我們暫且跳過,後續出一篇專門文章解讀循環依賴,我們直接看看populateBean到底做了什麼。
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
// 處理空實例
if (bw == null) {
// 如果創建的對象為空,但是在XML中又配置了需要注入的屬性的話,那麼直接報錯
if (mbd.hasPropertyValues()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// 空對象,不進行屬性注入
return;
}
}
// 滿足兩個條件,不是合成類 && 存在InstantiationAwareBeanPostProcessor
// 其中InstantiationAwareBeanPostProcessor主要作用就是作為Bean的實例化前後的鈎子
// 外加完成屬性注入,對於三個方法就是
// postProcessBeforeInstantiation 創建對象前調用
// postProcessAfterInstantiation 對象創建完成,@AutoWired註解解析后調用
// postProcessPropertyValues(已過期,被postProcessProperties替代) 進行屬性注入
// 下面這段代碼的主要作用就是我們可以提供一個InstantiationAwareBeanPostProcessor
// 提供的這個後置處理如果實現了postProcessAfterInstantiation方法並且返回false
// 那麼可以跳過Spring默認的屬性注入,但是這也意味着我們要自己去實現屬性注入的邏輯
// 所以一般情況下,我們也不會這麼去擴展
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
}
// 這裏其實就是判斷XML是否提供了屬性相關配置
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
// 確認注入模型
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
// 主要處理byName跟byType兩種注入模型,byConstructor這種注入模型在創建對象的時候已經處理過了
// 這裏都是對自動注入進行處理,byName跟byType兩種注入模型均是依賴setter方法
// byName,根據setter方法的名字來查找對應的依賴,例如setA,那麼就是去容器中查找名字為a的Bean
// byType,根據setter方法的參數類型來查找對應的依賴,例如setXx(A a),就是去容器中查詢類型為A的bean
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
// pvs是XML定義的屬性
// 自動注入后,bean實際用到的屬性就應該要替換成自動注入后的屬性
pvs = newPvs;
}
// 檢查是否有InstantiationAwareBeanPostProcessor
// 前面說過了,這個後置處理器就是來完成屬性注入的
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
// 是否需要依賴檢查,默認是不會進行依賴檢查的
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
// 下面這段代碼有點麻煩了,因為涉及到版本問題
// 其核心代碼就是調用了postProcessProperties完成了屬性注入
PropertyDescriptor[] filteredPds = null;
// 存在InstantiationAwareBeanPostProcessor,我們需要調用這類後置處理器的方法進行注入
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 這句就是核心
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
// 得到需要進行依賴檢查的屬性的集合
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
// 這個方法已經過時了,放到這裏就是為了兼容老版本
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
}
// 需要進行依賴檢查
if (needsDepCheck) {
if (filteredPds == null) {
// 得到需要進行依賴檢查的屬性的集合
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
// 對需要進行依賴檢查的屬性進行依賴檢查
checkDependencies(beanName, mbd, filteredPds, pvs);
}
// 將XML中的配置屬性應用到Bean上
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
上面這段代碼主要可以拆分為三個部分
- 處理自動注入
- 處理屬性注入(主要指處理@Autowired註解),最重要
- 處理依賴檢查
處理自動注入
autowireByName
對應源碼如下:
protected void autowireByName(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
// 得到符合下麵條件的屬性名稱
// 1.有setter方法
// 2.需要進行依賴檢查
// 3.不包含在XML配置中
// 4.不是簡單類型(基本數據類型,枚舉,日期等)
// 這裏可以看到XML配置優先級高於自動注入的優先級
// 不進行依賴檢查的屬性,也不會進行屬性注入
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
if (containsBean(propertyName)) {
Object bean = getBean(propertyName);
// 將自動注入的屬性添加到pvs中去
pvs.add(propertyName, bean);
// 註冊bean之間的依賴關係
registerDependentBean(propertyName, beanName);
// 忽略日誌
}
// 忽略日誌
}
}
看到了嗎?代碼就是這麼的簡單,不是要通過名稱注入嗎?直接通過beanName調用getBean,完事兒
autowireByType
protected void autowireByType(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
// 這個類型轉換器,主要是在處理@Value時需要使用
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
Set<String> autowiredBeanNames = new LinkedHashSet<>(4);
// 得到符合下麵條件的屬性名稱
// 1.有setter方法
// 2.需要進行依賴檢查
// 3.不包含在XML配置中
// 4.不是簡單類型(基本數據類型,枚舉,日期等)
// 這裏可以看到XML配置優先級高於自動注入的優先級
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
try {
PropertyDescriptor pd = bw.getPropertyDescriptor(propertyName);
if (Object.class != pd.getPropertyType()) {
// 這裏獲取到的就是setter方法的參數,因為我們需要按照類型進行注入嘛
MethodParameter methodParam = BeanUtils.getWriteMethodParameter(pd);
// 如果是PriorityOrdered在進行類型匹配時不會去匹配factoryBean
// 如果不是PriorityOrdered,那麼在查找對應類型的依賴的時候會會去匹factoryBean
// 這就是Spring的一種設計理念,實現了PriorityOrdered接口的Bean被認為是一種
// 最高優先級的Bean,這一類的Bean在進行為了完成裝配而去檢查類型時,
// 不去檢查factoryBean
// 具體可以參考PriorityOrdered接口上的註釋文檔
boolean eager = !(bw.getWrappedInstance() instanceof PriorityOrdered);
// 將參數封裝成為一個依賴描述符
// 依賴描述符會通過:依賴所在的類,字段名/方法名,依賴的具體類型等來描述這個依賴
DependencyDescriptor desc = new AutowireByTypeDependencyDescriptor(methodParam, eager);
// 解析依賴,這裡會處理@Value註解
// 另外,通過指定的類型到容器中查找對應的bean
Object autowiredArgument = resolveDependency(desc, beanName, autowiredBeanNames, converter);
if (autowiredArgument != null) {
// 將查找出來的依賴屬性添加到pvs中,後面會將這個pvs應用到bean上
pvs.add(propertyName, autowiredArgument);
}
// 註冊bean直接的依賴關係
for (String autowiredBeanName : autowiredBeanNames) {
registerDependentBean(autowiredBeanName, beanName);
if (logger.isDebugEnabled()) {
logger.debug("Autowiring by type from bean name '" + beanName + "' via property '" +
propertyName + "' to bean named '" + autowiredBeanName + "'");
}
}
autowiredBeanNames.clear();
}
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(mbd.getResourceDescription(), beanName, propertyName, ex);
}
}
}
resolveDependency
這個方法在Spring雜談 | 什麼是ObjectFactory?什麼是ObjectProvider?已經做過分析了,本文不再贅述。
可以看到,真正做事的方法是doResolveDependency
@Override
public Object resolveDependency(DependencyDescriptor descriptor, String requestingBeanName, Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
// descriptor代表當前需要注入的那個字段,或者方法的參數,也就是注入點
// ParameterNameDiscovery用於解析方法參數名稱
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
// 1. Optional<T>
if (Optional.class == descriptor.getDependencyType()) {
return createOptionalDependency(descriptor, requestingBeanName);
// 2. ObjectFactory<T>、ObjectProvider<T>
} else if (ObjectFactory.class == descriptor.getDependencyType() ||
ObjectProvider.class == descriptor.getDependencyType()) {
return new DependencyObjectProvider(descriptor, requestingBeanName);
// 3. javax.inject.Provider<T>
} else if (javaxInjectProviderClass == descriptor.getDependencyType()) {
return new Jsr330Factory().createDependencyProvider(descriptor, requestingBeanName);
} else {
// 4. @Lazy
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
// 5. 正常情況
if (result == null) {
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;
}
}
doResolveDependency
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
InjectionPoint previousInjectionPoint = ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}
// 依賴的具體類型
Class<?> type = descriptor.getDependencyType();
// 處理@Value註解,這裏得到的時候@Value中的值
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
// 解析@Value中的佔位符
String strVal = resolveEmbeddedValue((String) value);
// 獲取到對應的bd
BeanDefinition bd = (beanName != null && containsBean(beanName) ? getMergedBeanDefinition(beanName) : null);
// 處理EL表達式
value = evaluateBeanDefinitionString(strVal, bd);
}
// 通過解析el表達式可能還需要進行類型轉換
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
// 對map,collection,數組類型的依賴進行處理
// 最終會根據集合中的元素類型,調用findAutowireCandidates方法
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
// 根據指定類型可能會找到多個bean
// 這裏返回的既有可能是對象,也有可能是對象的類型
// 這是因為到這裏還不能明確的確定當前bean到底依賴的是哪一個bean
// 所以如果只會返回這個依賴的類型以及對應名稱,最後還需要調用getBean(beanName)
// 去創建這個Bean
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
// 一個都沒找到,直接拋出異常
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
// 通過類型找到了多個
if (matchingBeans.size() > 1) {
// 根據是否是主Bean
// 是否是最高優先級的Bean
// 是否是名稱匹配的Bean
// 來確定具體的需要注入的Bean的名稱
// 到這裏可以知道,Spring在查找依賴的時候遵循先類型再名稱的原則(沒有@Qualifier註解情況下)
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
// 無法推斷出具體的名稱
// 如果依賴是必須的,直接拋出異常
// 如果依賴不是必須的,但是這個依賴類型不是集合或者數組,那麼也拋出異常
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(type, matchingBeans);
}
// 依賴不是必須的,但是依賴類型是集合或者數組,那麼返回一個null
else {
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// 直接找到了一個對應的Bean
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
// 前面已經說過了,這裏可能返回的是Bean的類型,所以需要進一步調用getBean
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
// 做一些檢查,如果依賴是必須的,查找出來的依賴是一個null,那麼報錯
// 查詢處理的依賴類型不符合,也報錯
Object result = instanceCandidate;
if (result instanceof NullBean) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
result = null;
}
if (!ClassUtils.isAssignableValue(type, result)) {
throw new BeanNotOfRequiredTypeException(autowiredBeanName, type, instanceCandidate.getClass());
}
return result;
}
finally {
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
findAutowireCandidates
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
// 簡單來說,這裏就是到容器中查詢requiredType類型的所有bean的名稱的集合
// 這裡會根據descriptor.isEager()來決定是否要匹配factoryBean類型的Bean
// 如果isEager()為true,那麼會匹配factoryBean,反之,不會
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = new LinkedHashMap<>(candidateNames.length);
// 第一步會到resolvableDependencies這個集合中查詢是否已經存在了解析好的依賴
// 像我們之所以能夠直接在Bean中注入applicationContext對象
// 就是因為Spring之前就將這個對象放入了resolvableDependencies集合中
for (Class<?> autowiringType : this.resolvableDependencies.keySet()) {
if (autowiringType.isAssignableFrom(requiredType)) {
Object autowiringValue = this.resolvableDependencies.get(autowiringType);
// 如果resolvableDependencies放入的是一個ObjectFactory類型的依賴
// 那麼在這裡會生成一個代理對象
// 例如,我們可以在controller中直接注入request對象
// 就是因為,容器啟動時就在resolvableDependencies放入了一個鍵值對
// 其中key為:Request.class,value為:ObjectFactory
// 在實際注入時放入的是一個代理對象
autowiringValue = AutowireUtils.resolveAutowiringValue(autowiringValue, requiredType);
if (requiredType.isInstance(autowiringValue)) {
// 這裏放入的key不是Bean的名稱
// value是實際依賴的對象
result.put(ObjectUtils.identityToString(autowiringValue), autowiringValue);
break;
}
}
}
// 接下來開始對之前查找出來的類型匹配的所有BeanName進行處理
for (String candidate : candidateNames) {
// 不是自引用,什麼是自引用?
// 1.候選的Bean的名稱跟需要進行注入的Bean名稱相同,意味着,自己注入自己
// 2.或者候選的Bean對應的factoryBean的名稱跟需要注入的Bean名稱相同,
// 也就是說A依賴了B但是B的創建又需要依賴A
// 要符合注入的條件
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
// 調用addCandidateEntry,加入到返回集合中,後文有對這個方法的分析
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 排除自引用的情況下,沒有找到一個合適的依賴
if (result.isEmpty() && !indicatesMultipleBeans(requiredType)) {
// 1.先走fallback邏輯,Spring提供的一個擴展吧,感覺沒什麼卵用
// 默認情況下fallback的依賴描述符就是自身
DependencyDescriptor fallbackDescriptor = descriptor.forFallbackMatch();
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, fallbackDescriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// fallback還是失敗
if (result.isEmpty()) {
// 處理自引用
// 從這裏可以看出,自引用的優先級是很低的,只有在容器中真正的只有這個Bean能作為
// 候選者的時候,才會去處理,否則自引用是被排除掉的
for (String candidate : candidateNames) {
if (isSelfReference(beanName, candidate) &&
// 不是一個集合或者
// 是一個集合,但是beanName跟candidate的factoryBeanName相同
(!(descriptor instanceof MultiElementDescriptor) || !beanName.equals(candidate)) &&
isAutowireCandidate(candidate, fallbackDescriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
}
}
return result;
}
// candidates:就是findAutowireCandidates方法要返回的候選集合
// candidateName:當前的這個候選Bean的名稱
// descriptor:依賴描述符
// requiredType:依賴的類型
private void addCandidateEntry(Map<String, Object> candidates, String candidateName,
DependencyDescriptor descriptor, Class<?> requiredType) {
// 如果依賴是一個集合,或者容器中已經包含這個單例了
// 那麼直接調用getBean方法創建或者獲取這個Bean
if (descriptor instanceof MultiElementDescriptor || containsSingleton(candidateName)) {
Object beanInstance = descriptor.resolveCandidate(candidateName, requiredType, this);
candidates.put(candidateName, (beanInstance instanceof NullBean ? null : beanInstance));
}
// 如果依賴的類型不是一個集合,這個時候還不能確定到底要使用哪個依賴,
// 所以不能將這些Bean創建出來,所以這個時候,放入candidates是Bean的名稱以及類型
else {
candidates.put(candidateName, getType(candidateName));
}
}
處理屬性注入(@Autowired)
postProcessProperties
// 在applyMergedBeanDefinitionPostProcessors方法執行的時候,
// 已經解析過了@Autowired註解(buildAutowiringMetadata方法)
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
// 這裏獲取到的是解析過的緩存好的注入元數據
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
// 直接調用inject方法
// 存在兩種InjectionMetadata
// 1.AutowiredFieldElement
// 2.AutowiredMethodElement
// 分別對應字段的屬性注入以及方法的屬性注入
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
return pvs;
}
字段的屬性注入
// 最終反射調用filed.set方法
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Field field = (Field) this.member;
Object value;
if (this.cached) {
// 第一次注入的時候肯定沒有緩存
// 這裏也是對原型情況的處理
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
} else {
DependencyDescriptor desc = new DependencyDescriptor(field, this.required);
desc.setContainingClass(bean.getClass());
Set<String> autowiredBeanNames = new LinkedHashSet<>(1);
Assert.state(beanFactory != null, "No BeanFactory available");
TypeConverter typeConverter = beanFactory.getTypeConverter();
try {
// 這裏可以看到,對@Autowired註解在字段上的處理
// 跟byType下自動注入的處理是一樣的,就是調用resolveDependency方法
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
} catch (BeansException ex) {
throw new UnsatisfiedDependencyException(null, beanName, new InjectionPoint(field), ex);
}
synchronized (this) {
// 沒有緩存過的話,這裏需要進行緩存
if (!this.cached) {
if (value != null || this.required) {
this.cachedFieldValue = desc;
// 註冊Bean之間的依賴關係
registerDependentBeans(beanName, autowiredBeanNames);
// 如果這個類型的依賴只存在一個的話,我們就能確定這個Bean的名稱
// 那麼直接將這個名稱緩存到ShortcutDependencyDescriptor中
// 第二次進行注入的時候就可以直接調用getBean(beanName)得到這個依賴了
// 實際上正常也只有一個,多個就報錯了
// 另外這裡會過濾掉@Vlaue得到的依賴
if (autowiredBeanNames.size() == 1) {
String autowiredBeanName = autowiredBeanNames.iterator().next();
// 通過resolvableDependencies這個集合找的依賴不滿足containsBean條件
// 不會進行緩存,因為緩存實際還是要調用getBean,而resolvableDependencies
// 是沒法通過getBean獲取的
if (beanFactory.containsBean(autowiredBeanName) &&
beanFactory.isTypeMatch(autowiredBeanName, field.getType())) { // 依賴描述符封裝成ShortcutDependencyDescriptor進行緩存
this.cachedFieldValue = new ShortcutDependencyDescriptor(
desc, autowiredBeanName, field.getType());
}
}
} else {
this.cachedFieldValue = null;
}
this.cached = true;
}
}
}
if (value != null) {
// 反射調用Field.set方法
ReflectionUtils.makeAccessible(field);
field.set(bean, value);
}
}
方法的屬性注入
// 代碼看着很長,實際上邏輯跟字段注入基本一樣
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
// 判斷XML中是否配置了這個屬性,如果配置了直接跳過
// 換而言之,XML配置的屬性優先級高於@Autowired註解
if (checkPropertySkipping(pvs)) {
return;
}
Method method = (Method) this.member;
Object[] arguments;
if (this.cached) {
arguments = resolveCachedArguments(beanName);
} else {
// 通過方法參數類型構造依賴描述符
// 邏輯基本一樣的,最終也是調用beanFactory.resolveDependency方法
Class<?>[] paramTypes = method.getParameterTypes();
arguments = new Object[paramTypes.length];
DependencyDescriptor[] descriptors = new DependencyDescriptor[paramTypes.length];
Set<String> autowiredBeans = new LinkedHashSet<>(paramTypes.length);
Assert.state(beanFactory != null, "No BeanFactory available");
TypeConverter typeConverter = beanFactory.getTypeConverter();
// 遍歷方法的每個參數
for (int i = 0; i < arguments.length; i++) {
MethodParameter methodParam = new MethodParameter(method, i);
DependencyDescriptor currDesc = new DependencyDescriptor(methodParam, this.required);
currDesc.setContainingClass(bean.getClass());
descriptors[i] = currDesc;
try {
// 還是要調用這個方法
Object arg = beanFactory.resolveDependency(currDesc, beanName, autowiredBeans, typeConverter);
if (arg == null && !this.required) {
arguments = null;
break;
}
arguments[i] = arg;
} catch (BeansException ex) {
throw new UnsatisfiedDependencyException(null, beanName, new InjectionPoint(methodParam), ex);
}
}
synchronized (this) {
if (!this.cached) {
if (arguments != null) {
Object[] cachedMethodArguments = new Object[paramTypes.length];
System.arraycopy(descriptors, 0, cachedMethodArguments, 0, arguments.length);
// 註冊bean之間的依賴關係
registerDependentBeans(beanName, autowiredBeans);
// 跟字段注入差不多,存在@Value註解,不進行緩存
if (autowiredBeans.size() == paramTypes.length) {
Iterator<String> it = autowiredBeans.iterator();
for (int i = 0; i < paramTypes.length; i++) {
String autowiredBeanName = it.next();
if (beanFactory.containsBean(autowiredBeanName) &&
beanFactory.isTypeMatch(autowiredBeanName, paramTypes[i])) {
cachedMethodArguments[i] = new ShortcutDependencyDescriptor(
descriptors[i], autowiredBeanName, paramTypes[i]);
}
}
}
this.cachedMethodArguments = cachedMethodArguments;
} else {
this.cachedMethodArguments = null;
}
this.cached = true;
}
}
}
if (arguments != null) {
try {
// 反射調用方法
// 像我們的setter方法就是在這裏調用的
ReflectionUtils.makeAccessible(method);
method.invoke(bean, arguments);
} catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
}
}
處理依賴檢查
protected void checkDependencies(
String beanName, AbstractBeanDefinition mbd, PropertyDescriptor[] pds, PropertyValues pvs)
throws UnsatisfiedDependencyException {
int dependencyCheck = mbd.getDependencyCheck();
for (PropertyDescriptor pd : pds) {
// 有set方法但是在pvs中沒有對應屬性,那麼需要判斷這個屬性是否要進行依賴檢查
// 如果需要進行依賴檢查的話,就需要報錯了
// pvs中保存的是自動注入以及XML配置的屬性
if (pd.getWriteMethod() != null && !pvs.contains(pd.getName())) {
// 是否是基本屬性,枚舉/日期等也包括在內
boolean isSimple = BeanUtils.isSimpleProperty(pd.getPropertyType());
// 如果DEPENDENCY_CHECK_ALL,對任意屬性都開啟了依賴檢查,報錯
// DEPENDENCY_CHECK_SIMPLE,對基本屬性開啟了依賴檢查並且是基本屬性,報錯
// DEPENDENCY_CHECK_OBJECTS,對非基本屬性開啟了依賴檢查並且不是非基本屬性,報錯
boolean unsatisfied = (dependencyCheck == AbstractBeanDefinition.DEPENDENCY_CHECK_ALL) ||
(isSimple && dependencyCheck == AbstractBeanDefinition.DEPENDENCY_CHECK_SIMPLE) ||
(!isSimple && dependencyCheck == AbstractBeanDefinition.DEPENDENCY_CHECK_OBJECTS);
if (unsatisfied) {
throw new UnsatisfiedDependencyException(mbd.getResourceDescription(), beanName, pd.getName(),
"Set this property value or disable dependency checking for this bean.");
}
}
}
}
將解析出來的屬性應用到Bean上
到這一步解析出來的屬性主要有三個來源
- XML中配置的
- 通過byName的方式自動注入的
- 通過byType的方式自動注入的
但是在應用到Bean前還需要做一步類型轉換,這一部分代碼實際上跟我們之前在Spring官網閱讀(十四)Spring中的BeanWrapper及類型轉換介紹的差不多,而且因為XML跟自動注入的方式都不常見,正常@Autowired的方式進行注入的話,這個方法沒有什麼用,所以本文就不再贅述。
總結
本文我們主要分析了Spring在屬性注入過程中的相關代碼,整個屬性注入可以分為兩個部分
@Autowired/@Vale的方式完成屬性注入- 自動注入(
byType/byName)
完成屬性注入的核心方法其實就是doResolveDependency。doResolveDependency這個方法的邏輯簡單來說分為兩步:
- 通過依賴類型查詢到所有的類型匹配的bean的名稱
- 如果找到了多個的話,再根據依賴的名稱匹配對應的Bean的名稱
- 調用getBean得到這個需要被注入的Bean
- 最後反射調用字段的set方法完成屬性注入
從上面也可以知道,其實整個屬性注入的邏輯是很簡單的。
如果本文對你有幫助的話,記得點個贊吧!也歡迎關注我的公眾號,微信搜索:程序員DMZ,或者掃描下方二維碼,跟着我一起認認真真學Java,踏踏實實做一個coder。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心