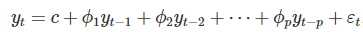作者:小土豆biubiubiu
博客園:https://www.cnblogs.com/HouJiao/
掘金:https://juejin.im/user/58c61b4361ff4b005d9e894d
微信公眾號:土豆媽的碎碎念(掃碼關注,一起吸貓,一起聽故事,一起學習前端技術)
作者文章的內容均來源於自己的實踐,如果覺得有幫助到你的話,可以點贊給個鼓勵或留下寶貴意見
前言
在日常開發中,項目中的菜單欄都是已經實現好了的。如果需要添加新的菜單,只需要在路由配置中新增一條路由,就可以實現菜單的添加。
相信大家和我一樣,有時候會躍躍欲試自己去實現一個菜單欄。那今天我就將自己實現的菜單欄的整個思路和代碼分享給大家。
本篇文章重在總結和分享菜單欄的一個遞歸實現方式,代碼的優化、菜單權限等不在本篇文章範圍之內,在文中的相關部分也會做一些提示,有個別不推薦的寫法希望大家不要參考哦。
同時可能會存在一些細節的功能沒有處理或者沒有提及到,忘知曉。
最終的效果
本次實現的這個菜單欄包含有一級菜單、二級菜單和三級菜單這三種類型,基本上已經可以覆蓋項目中不同的菜單需求。
後面會一步一步從易到難去實現這個菜單。
簡單實現
我們都知道到element提供了 NavMenu 導航菜單組件,因此我們直接按照文檔將這個菜單欄做一個簡單的實現。
基本的布局架構圖如下:
菜單首頁-menuIndex
首先要實現的是菜單首頁這個組件,根據前面的布局架構圖並且參考官方文檔,實現起來非常簡單。
<!-- src/menu/menuIndex.vue -->
<template>
<div id="menu-index">
<el-container>
<el-header>
<TopMenu :logoPath="logoPath" :name="name"></TopMenu>
</el-header>
<el-container id="left-container">
<el-aside width="200px">
<LeftMenu></LeftMenu>
</el-aside>
<el-main>
<router-view/>
</el-main>
</el-container>
</el-container>
</div>
</template>
<script>
import LeftMenu from './leftMenu';
import TopMenu from './topMenu';
export default {
name: 'MenuIndex',
components: {LeftMenu, TopMenu},
data() {
return {
logoPath: require("../../assets/images/logo1.png"),
name: '員工管理系統'
}
}
}
</script>
<style lang="scss">
#menu-index{
.el-header{
padding: 0px;
}
}
</style>
頂部菜單欄-topMenu
頂部菜單欄主要就是一個logo和產品名稱。
邏輯代碼也很簡單,我直接將代碼貼上。
<!-- src/menu/leftMenu.vue -->
<template>
<div id="top-menu">
<img class="logo" :src="logoPath" />
<p class="name">{{name}}</p>
</div>
</template>
<script>
export default {
name: 'topMenu',
props: ['logoPath', 'name']
}
</script>
<style lang="scss" scoped>
$topMenuWidth: 80px;
$logoWidth: 50px;
$bg-color: #409EFF;
$name-color: #fff;
$name-size: 18px;
#top-menu{
height: $topMenuWidth;
text-align: left;
background-color: $bg-color;
padding: 20px 20px 0px 20px;
.logo {
width: $logoWidth;
display: inline-block;
}
.name{
display: inline-block;
vertical-align: bottom;
color: $name-color;
font-size: $name-size;
}
}
</style>
這段代碼中包含了父組件傳遞給子組件的兩個數據。
props: ['logoPath', 'name']
這個是父組件menuIndex傳遞給子組件topMenu的兩個數據,分別是logo圖標的路徑和產品名稱。
完成后的界面效果如下。
左側菜單欄-leftMenu
首先按照官方文檔實現一個簡單的菜單欄。
<!-- src/menu/leftMenu.vue -->
<template>
<div id="left-menu">
<el-menu
:default-active="$route.path"
class="el-menu-vertical-demo"
:collapse="false">
<el-menu-item index="1">
<i class="el-icon-s-home"></i>
<span slot="title">首頁</span>
</el-menu-item>
<el-submenu index="2">
<template slot="title">
<i class="el-icon-user-solid"></i>
<span slot="title">員工管理</span>
</template>
<el-menu-item index="2-1">員工統計</el-menu-item>
<el-menu-item index="2-2">員工管理</el-menu-item>
</el-submenu>
<el-submenu index="3">
<template slot="title">
<i class="el-icon-s-claim"></i>
<span slot="title">考勤管理</span>
</template>
<el-menu-item index="3-1">考勤統計</el-menu-item>
<el-menu-item index="3-2">考勤列表</el-menu-item>
<el-menu-item index="3-2">異常管理</el-menu-item>
</el-submenu>
<el-submenu index="4">
<template slot="title">
<i class="el-icon-location"></i>
<span slot="title">工時管理</span>
</template>
<el-menu-item index="4-1">工時統計</el-menu-item>
<el-submenu index="4-2">
<template slot="title">工時列表</template>
<el-menu-item index="4-2-1">選項一</el-menu-item>
<el-menu-item index="4-2-2">選項二</el-menu-item>
</el-submenu>
</el-submenu>
</el-menu>
</div>
</template>
<script>
export default {
name: 'LeftMenu'
}
</script>
<style lang="scss">
// 使左邊的菜單外層的元素高度充滿屏幕
#left-container{
position: absolute;
top: 100px;
bottom: 0px;
// 使菜單高度充滿屏幕
#left-menu, .el-menu-vertical-demo{
height: 100%;
}
}
</style>
注意菜單的樣式代碼,設置了絕對定位,並且設置top、bottom使菜單高度撐滿屏幕。
此時在看下界面效果。
基本上算是實現了一個簡單的菜單布局。
不過在實際項目在設計的時候,菜單欄的內容有可能來自後端給我們返回的數據,其中包含菜單名稱、菜單圖標以及菜單之間的層級關係。
總而言之,我們的菜單是動態生成的,而不是像前面那種固定的寫法。因此下面我將實現一個動態生成的菜單,菜單的數據來源於我們的路由配置。
結合路由配置實現動態菜單
路由配置
首先,我將項目的路由配置代碼貼出來。
import Vue from 'vue';
import Router from "vue-router";
// 菜單
import MenuIndex from '@/components/menu/menuIndex.vue';
// 首頁
import Index from '@/components/homePage/index.vue';
// 人員統計
import EmployeeStatistics from '@/components/employeeManage/employeeStatistics.vue';
import EmployeeManage from '@/components/employeeManage/employeeManage.vue'
// 考勤
// 考勤統計
import AttendStatistics from '@/components/attendManage/attendStatistics';
// 考勤列表
import AttendList from '@/components/attendManage/attendList.vue';
// 異常管理
import ExceptManage from '@/components/attendManage/exceptManage.vue';
// 工時
// 工時統計
import TimeStatistics from '@/components/timeManage/timeStatistics.vue';
// 工時列表
import TimeList from '@/components/timeManage/timeList.vue';
Vue.use(Router)
let routes = [
// 首頁(儀錶盤、快速入口)
{
path: '/index',
name: 'index',
component: MenuIndex,
redirect: '/index',
meta: {
title: '首頁', // 菜單標題
icon: 'el-icon-s-home', // 圖標
hasSubMenu: false, // 是否包含子菜單,false 沒有子菜單;true 有子菜單
},
children:[
{
path: '/index',
component: Index
}
]
},
// 員工管理
{
path: '/employee',
name: 'employee',
component: MenuIndex,
redirect: '/employee/employeeStatistics',
meta: {
title: '員工管理', // 菜單標題
icon: 'el-icon-user-solid', // 圖標
hasSubMenu: true, // 是否包含子菜單
},
children: [
// 員工統計
{
path: 'employeeStatistics',
name: 'employeeStatistics',
meta: {
title: '員工統計', // 菜單標題,
hasSubMenu: false // 是否包含子菜單
},
component: EmployeeStatistics,
},
// 員工管理(增刪改查)
{
path: 'employeeManage',
name: 'employeeManage',
meta: {
title: '員工管理', // 菜單標題
hasSubMenu: false // 是否包含子菜單
},
component: EmployeeManage
}
]
},
// 考勤管理
{
path: '/attendManage',
name: 'attendManage',
component: MenuIndex,
redirect: '/attendManage/attendStatistics',
meta: {
title: '考勤管理', // 菜單標題
icon: 'el-icon-s-claim', // 圖標
hasSubMenu: true, // 是否包含子節點,false 沒有子菜單;true 有子菜單
},
children:[
// 考勤統計
{
path: 'attendStatistics',
name: 'attendStatistics',
meta: {
title: '考勤統計', // 菜單標題
hasSubMenu: false // 是否包含子菜單
},
component: AttendStatistics,
},
// 考勤列表
{
path: 'attendList',
name: 'attendList',
meta: {
title: '考勤列表', // 菜單標題
hasSubMenu: false // 是否包含子菜單
},
component: AttendList,
},
// 異常管理
{
path: 'exceptManage',
name: 'exceptManage',
meta: {
title: '異常管理', // 菜單標題
hasSubMenu: false // 是否包含子菜單
},
component: ExceptManage,
}
]
},
// 工時管理
{
path: '/timeManage',
name: 'timeManage',
component: MenuIndex,
redirect: '/timeManage/timeStatistics',
meta: {
title: '工時管理', // 菜單標題
icon: 'el-icon-message-solid', // 圖標
hasSubMenu: true, // 是否包含子菜單,false 沒有子菜單;true 有子菜單
},
children: [
// 工時統計
{
path: 'timeStatistics',
name: 'timeStatistics',
meta: {
title: '工時統計', // 菜單標題
hasSubMenu: false // 是否包含子菜單
},
component: TimeStatistics
},
// 工時列表
{
path: 'timeList',
name: 'timeList',
component: TimeList,
meta: {
title: '工時列表', // 菜單標題
hasSubMenu: true // 是否包含子菜單
},
children: [
{
path: 'options1',
meta: {
title: '選項一', // 菜單標題
hasSubMenu: false // 是否包含子菜單
},
},
{
path: 'options2',
meta: {
title: '選項二', // 菜單標題
hasSubMenu: false // 是否包含子菜單
},
},
]
}
]
},
];
export default new Router({
routes
})
在這段代碼的最開始部分,我們引入了需要使用的組件,接着就對路由進行了配置。
此處使用了直接引入組件的方式,項目開發中不推薦這種寫法,應該使用懶加載的方式
路由配置除了最基礎的path、component以及children之外,還配置了一個meta數據項。
meta: {
title: '工時管理', // 菜單標題
icon: 'el-icon-message-solid', // 圖標
hasSubMenu: true, // 是否包含子節點,false 沒有子菜單;true 有子菜單
}
meta數據包含的配置有菜單標題(title)、圖標的類名(icon)和是否包含子節點(hasSubMenu)。
根據title、icon這兩個配置項,可以展示當前菜單的標題和圖標。
hasSubMenu表示當前的菜單項是否有子菜單,如果當前菜單包含有子菜單(hasSubMenu為true),那當前菜單對應的標籤元素就是el-submenu;否則當前菜單對應的菜單標籤元素就是el-menu-item。
是否包含子菜單是一個非常關鍵的邏輯,我在實現的時候是直接將其配置到了meta.hasSubMenu這個參數裏面。
根據路由實現多級菜單
路由配置完成后,我們就需要根據路由實現菜單了。
獲取路由配置
既然要根據路由配置實現多級菜單,那第一步就需要獲取我們的路由數據。這裏我使用簡單粗暴的方式去獲取路由配置數據:this.$router.options.routes。
這種方式也不太適用日常的項目開發,因為無法在獲取的時候對路由做進一步的處理,比如權限控制。
我們在組件加載時打印一下這個數據。
// 代碼位置:src/menu/leftMenu.vue
mounted(){
console.log(this.$router.options.routes);
}
打印結果如下。
可以看到這個數據就是我們在router.js中配置的路由數據。
為了方便使用,我將這個數據定義到計算屬性中。
// 代碼位置:src/menu/leftMenu.vue
computed: {
routesInfo: function(){
return this.$router.options.routes;
}
}
一級菜單
首先我們來實現一級菜單。
主要的邏輯就是循環路由數據routesInfo,在循環的時候判斷當前路由route是否包含子菜單,如果包含則當前菜單使用el-submenu實現,否則當前菜單使用el-menu-item實現。
<!-- src/menu/leftMenu.vue -->
<el-menu
:default-active="$route.path"
class="el-menu-vertical-demo"
:collapse="false">
<!-- 一級菜單 -->
<!-- 循環路由數據 -->
<!-- 判斷當前路由route是否包含子菜單 -->
<el-submenu
v-for="route in routesInfo"
v-if="route.meta.hasSubMenu"
:index="route.path">
<template slot="title">
<i :class="route.meta.icon"></i>
<span slot="title">{{route.meta.title}}</span>
</template>
</el-submenu>
<el-menu-item :index="route.path" v-else>
<i :class="route.meta.icon"></i>
<span slot="title">{{route.meta.title}}</span>
</el-menu-item>
</el-menu>
結果:
可以看到,我們第一級菜單已經生成了,員工管理、考勤管理、工時管理這三個菜單是有子菜單的,所以會有一個下拉按鈕。
不過目前點開是沒有任何內容的,接下來我們就來實現這三個菜單下的二級菜單。
二級菜單
二級菜單的實現和一級菜單的邏輯是相同的:循環子路由route.children,在循環的時候判斷子路由childRoute是否包含子菜單,如果包含則當前菜單使用el-submenu實現,否則當前菜單使用el-menu-item實現。
那話不多說,直接上代碼。
<!-- src/menu/leftMenu.vue -->
<el-menu
:default-active="$route.path"
class="el-menu-vertical-demo"
:collapse="false">
<!-- 一級菜單 -->
<!-- 循環路由數據 -->
<!-- 判斷當前路由route是否包含子菜單 -->
<el-submenu
v-for="route in routesInfo"
v-if="route.meta.hasSubMenu"
:index="route.path">
<template slot="title">
<i :class="route.meta.icon"></i>
<span slot="title">{{route.meta.title}}</span>
</template>
<!-- 二級菜單 -->
<!-- 循環子路由`route.children` -->
<!-- 循環的時候判斷子路由`childRoute`是否包含子菜單 -->
<el-submenu
v-for="childRoute in route.children"
v-if="childRoute.meta.hasSubMenu"
:index="childRoute.path">
<template slot="title">
<i :class="childRoute.meta.icon"></i>
<span slot="title">{{childRoute.meta.title}}</span>
</template>
</el-submenu>
<el-menu-item :index="childRoute.path" v-else>
<i :class="childRoute.meta.icon"></i>
<span slot="title">{{childRoute.meta.title}}</span>
</el-menu-item>
</el-submenu>
<el-menu-item :index="route.path" v-else>
<i :class="route.meta.icon"></i>
<span slot="title">{{route.meta.title}}</span>
</el-menu-item>
</el-menu>
結果如下:
可以看到二級菜單成功實現。
三級菜單
三級菜單就不用多說了,和一級、二級邏輯相同,這裏還是直接上代碼。
<!-- src/menu/leftMenu.vue -->
<el-menu
:default-active="$route.path"
class="el-menu-vertical-demo"
:collapse="false">
<!-- 一級菜單 -->
<!-- 循環路由數據 -->
<!-- 判斷當前路由route是否包含子菜單 -->
<el-submenu
v-for="route in routesInfo"
v-if="route.meta.hasSubMenu"
:index="route.path">
<template slot="title">
<i :class="route.meta.icon"></i>
<span slot="title">{{route.meta.title}}</span>
</template>
<!-- 二級菜單 -->
<!-- 循環子路由`route.children` -->
<!-- 循環的時候判斷子路由`childRoute`是否包含子菜單 -->
<el-submenu
v-for="childRoute in route.children"
v-if="childRoute.meta.hasSubMenu"
:index="childRoute.path">
<template slot="title">
<i :class="childRoute.meta.icon"></i>
<span slot="title">{{childRoute.meta.title}}</span>
</template>
<!-- 三級菜單 -->
<!-- 循環子路由`childRoute.children` -->
<!-- 循環的時候判斷子路由`child`是否包含子菜單 -->
<el-submenu
v-for="child in childRoute.children"
v-if="child.meta.hasSubMenu"
:index="child.path">
<template slot="title">
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}}</span>
</template>
</el-submenu>
<el-menu-item :index="child.path" v-else>
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}}</span>
</el-menu-item>
</el-submenu>
<el-menu-item :index="childRoute.path" v-else>
<i :class="childRoute.meta.icon"></i>
<span slot="title">{{childRoute.meta.title}}</span>
</el-menu-item>
</el-submenu>
<el-menu-item :index="route.path" v-else>
<i :class="route.meta.icon"></i>
<span slot="title">{{route.meta.title}}</span>
</el-menu-item>
</el-menu>
可以看到工時列表下的三級菜單已經显示了。
總結
此時我們已經結合路由配置實現了這個動態的菜單。
不過這樣的代碼在邏輯上相關於三層嵌套的for循環,對應的是我們有三層的菜單。
假如我們有四層、五層甚至更多層的菜單時,那我們還得在嵌套更多層for循環。很顯然這樣的方式暴露了前面多層for循環的缺陷,所以我們就需要對這樣的寫法進行一個改進。
遞歸實現動態菜單
前面我們一直在說一級、二級、三級菜單的實現邏輯都是相同的:循環子路由,在循環的時候判斷子路由是否包含子菜單,如果包含則當前菜單使用el-submenu實現,否則當前菜單使用el-menu-item實現。那這樣的邏輯最適合的就是使用遞歸去實現。
所以我們需要將這部分共同的邏輯抽離出來作為一個獨立的組件,然後遞歸的調用這個組件。
邏輯拆分
<!-- src/menu/menuItem.vue -->
<template>
<div>
<el-submenu
v-for="child in route"
v-if="child.meta.hasSubMenu"
:index="child.path">
<template slot="title">
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}}</span>
</template>
</el-submenu>
<el-menu-item :index="child.path" v-else>
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}}</span>
</el-menu-item>
</div>
</template>
<script>
export default {
name: 'MenuItem',
props: ['route']
}
</script>
需要注意的是,這次抽離出來的組件循環的時候直接循環的是route數據,那這個route數據是什麼呢。
我們先看一下前面三層循環中循環的數據源分別是什麼。
為了看得更清楚,我將前面代碼中一些不相關的內容進行了刪減。
<!-- src/menu/leftMenu.vue -->
<!-- 一級菜單 -->
<el-submenu
v-for="route in routesInfo"
v-if="route.meta.hasSubMenu">
<!-- 二級菜單 -->
<el-submenu
v-for="childRoute in route.children"
v-if="childRoute.meta.hasSubMenu">
<!-- 三級菜單 -->
<el-submenu
v-for="child in childRoute.children"
v-if="child.meta.hasSubMenu">
</el-submenu>
</el-submenu>
</el-submenu>
從上面的代碼可以看到:
一級菜單循環的是`routeInfo`,即最初我們獲取的路由數據`this.$router.options.routes`,循環出來的每一項定義為`route`
二級菜單循環的是`route.children`,循環出來的每一項定義為`childRoute`
三級菜單循環的是`childRoute.children`,循環出來的每一項定義為`child`
按照這樣的邏輯,可以發現二級菜單、三級菜單循環的數據源都是相同的,即前一個循環結果項的children,而一級菜單的數據來源於this.$router.options.routes。
前面我們抽離出來的menuItem組件,循環的是route數據,即不管是一層菜單還是二層、三層菜單,都是同一個數據源,因此我們需要統一數據源。那當然也非常好實現,我們在調用組件的時候,為組件傳遞不同的值即可。
代碼實現
前面公共組件已經拆分出來了,後面的代碼就非常好實現了。
首先是抽離出來的meunItem組件,實現的是邏輯判斷以及遞歸調用自身。
<!-- src/menu/menuItem.vue -->
<template>
<div>
<el-submenu
v-for="child in route"
v-if="child.meta.hasSubMenu"
:index="child.path">
<template slot="title">
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}}</span>
</template>
<!--遞歸調用組件自身 -->
<MenuItem :route="child.children"></MenuItem>
</el-submenu>
<el-menu-item :index="child.path" v-else>
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}}</span>
</el-menu-item>
</div>
</template>
<script>
export default {
name: 'MenuItem',
props: ['route']
}
</script>
接着是leftMenu組件,調用menuIndex組件,傳遞原始的路由數據routesInfo。
<!-- src/menu/leftMenu.vue -->
<template>
<div id="left-menu">
<el-menu
:default-active="$route.path"
class="el-menu-vertical-demo"
:collapse="false">
<MenuItem :route="routesInfo"></MenuItem>
</el-menu>
</div>
</template>
<script>
import MenuItem from './menuItem'
export default {
name: 'LeftMenu',
components: { MenuItem }
}
</script>
<style lang="scss">
// 使左邊的菜單外層的元素高度充滿屏幕
#left-container{
position: absolute;
top: 100px;
bottom: 0px;
// 使菜單高度充滿屏幕
#left-menu, .el-menu-vertical-demo{
height: 100%;
}
}
</style>
最終的結果這裏就不展示了,和我們需要實現的結果是一致的。
功能完善
到此,我們結合路由配置實現了菜單欄這個功能基本上已經完成了,不過這是一個缺乏靈魂的菜單欄,因為沒有設置菜單的跳轉,我們點擊菜單欄還無法路由跳轉到對應的組件,所以接下來就來實現這個功能。
菜單跳轉的實現方式有兩種,第一種是NavMenu組件提供的跳轉方式。
第二種是在菜單上添加router-link實現跳轉。
那本次我選擇的是第一種方式實現跳轉,這種實現方式需要兩個步驟才能完成,第一步是啟用el-menu上的router;第二步是設置導航的index屬性。
那下面就來實現這兩個步驟。
啟用el-menu上的router
<!-- src/menu/leftMenu.vue -->
<!-- 省略其餘未修改代碼-->
<el-menu
:default-active="$route.path"
class="el-menu-vertical-demo"
router
:collapse="false">
<MenuItem :route="routesInfo">
</MenuItem>
</el-menu>
設置導航的index屬性
首先我將每一個菜單標題對應需要設置的index屬性值列出來。
index值對應的是每個菜單在路由中配置的path值
首頁
員工管理
員工統計 index="/employee/employeeStatistics"
員工管理 index="/employee/employeeManage"
考勤管理
考勤統計 index="/attendManage/attendStatistics"
考勤列表 index="/attendManage/attendList"
異常管理 index="/attendManage/exceptManage"
員工統計
員工統計 index="/timeManage/timeStatistics"
員工統計 index="/timeManage/timeList"
選項一 index="/timeManage/timeList/options1"
選項二 index="/timeManage/timeList/options2"
接着在回顧前面遞歸調用的組件,導航菜單的index設置的是child.path,為了看清楚child.path的值,我將其添加菜單標題的右側,讓其显示到界面上。
<!-- src/menu/menuItem.vue -->
<!-- 省略其餘未修改代碼-->
<el-submenu
v-for="child in route"
v-if="child.meta.hasSubMenu"
:index="child.path">
<template slot="title">
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}} | {{child.path}}</span>
</template>
<!--遞歸調用組件自身 -->
<MenuItem :route="child.children"></MenuItem>
</el-submenu>
<el-menu-item :index="child.path" v-else>
<i :class="child.meta.icon"></i>
<span slot="title">{{child.meta.title}} | {{child.path}}</span>
</el-menu-item>
同時將菜單欄的寬度由200px設置為400px。
<!-- src/menu/menuIndex.vue -->
<!-- 省略其餘未修改代碼-->
<el-aside width="400px">
<LeftMenu></LeftMenu>
</el-aside>
然後我們看一下效果。
可以發現,child.path的值就是當前菜單在路由中配置path值(router.js中配置的path值)。
那麼問題就來了,前面我們整理了每一個菜單標題對應需要設置的index屬性值,就目前來看,現在設置的index值是不符合要求的。不過仔細觀察現在菜單設置的index值和正常值是有一點接近的,只是缺少了上一級菜單的path值,如果能將上一級菜單的path值和當前菜單的path值進行一個拼接,就能得到正確的index值了。
那這個思路實現的方式依然是在遞歸時將當前菜單的path作為參數傳遞給menuItem組件。
<!-- src/menu/menuIndex.vue -->
<!--遞歸調用組件自身 -->
<MenuItem
:route="child.children"
:basepath="child.path">
</MenuItem>
將當前菜單的path作為參數傳遞給menuItem組件之後,在下一級菜單實現時,就能拿到上一級菜單的path值。然後組件中將basepath的值和當前菜單的path值做一個拼接,作為當前菜單的index值。
<!-- src/menu/menuIndex.vue -->
<el-menu-item :index="getPath(child.path)" v-else>
</el-menu-item>
<script>
import path from 'path'
export default {
name: 'MenuItem',
props: ['route','basepath'],
data(){
return {
}
},
methods :{
// routepath 為當前菜單的path值
// getpath: 拼接 當前菜單的上一級菜單的path 和 當前菜單的path
getPath: function(routePath){
return path.resolve(this.basepath, routePath);
}
}
}
</script>
再看一下界面。
我們可以看到二級菜單的index值已經沒問題了,但是仔細看,發現工時管理–工時列表下的兩個三級菜單index值還是有問題,缺少了工時管理這個一級菜單的path。
那這個問題是因為我們在調用組件自身是傳遞的basepath有問題。
<!--遞歸調用組件自身 -->
<MenuItem
:route="child.children"
:basepath="child.path">
</MenuItem>
basepath傳遞的只是上一級菜單的path,在遞歸二級菜單時,index的值是一級菜單的path值+二級菜單的path值;那當我們遞歸三級菜單時,index的值就是二級菜單的path值+三級菜單的path值,這也就是為什麼工時管理-工時列表下的兩個三級菜單index值存在問題。
所以這裏的basepath值在遞歸的時候應該是累積的,而不只是上一級菜單的path值。因此藉助遞歸算法的優勢,basepath的值也需要通過getPath方法進行處理。
<MenuItem
:route="child.children"
:basepath="getPath(child.path)">
</MenuItem>
最終完整的代碼如下。
<!-- src/menu/menuIndex.vue -->
<template>
<div>
<el-submenu
v-for="child in route"
v-if="child.meta.hasSubMenu"
:key="child.path"
:index="getPath(child.path)">
<template slot="title">
<i :class="child.meta.icon"></i>
<span slot="title">
{{child.meta.title}}
</span>
</template>
<!--遞歸調用組件自身 -->
<MenuItem
:route="child.children"
:basepath="getPath(child.path)">
</MenuItem>
</el-submenu>
<el-menu-item :index="getPath(child.path)" v-else>
<i :class="child.meta.icon"></i>
<span slot="title">
{{child.meta.title}}
</span>
</el-menu-item>
</div>
</template>
<script>
import path from 'path'
export default {
name: 'MenuItem',
props: ['route','basepath'],
data(){
return {
}
},
methods :{
// routepath 為當前菜單的path值
// getpath: 拼接 當前菜單的上一級菜單的path 和 當前菜單的path
getPath: function(routePath){
return path.resolve(this.basepath, routePath);
}
}
}
</script>
刪除其餘用來調試的代碼
最終效果
文章的最後呢,將本次實現的最終效果在此展示一下。
選項一和選項二這兩個三級菜單在路由配置中沒有設置component,這兩個菜單隻是為了實現三級菜單,在最後的結果演示中,我已經刪除了路由中配置的這兩個三級菜單
此處在leftMenu組件中為el-menu開啟了unique-opened
在menuIndex組件中,將左側菜單欄的寬度改為200px
關於
作者
小土豆biubiubiu
一個努力學習的前端小菜鳥,知識是無限的。堅信只要不停下學習的腳步,總能到達自己期望的地方
同時還是一個喜歡小貓咪的人,家裡有一隻美短小母貓,名叫土豆
博客園
https://www.cnblogs.com/HouJiao/
掘金
https://juejin.im/user/58c61b4361ff4b005d9e894d
微信公眾號
土豆媽的碎碎念
微信公眾號的初衷是記錄自己和身邊的一些故事,同時會不定期更新一些技術文章
歡迎大家掃碼關注,一起吸貓,一起聽故事,一起學習前端技術
作者寄語
小小總結,歡迎大家指導~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益