折騰了好長時間才寫這篇文章,順序消費,看上去挺好理解的,就是消費的時候按照隊列中的順序一個一個消費;而併發消費,則是消費者同時從隊列中取消息,同時消費,沒有先後順序。RocketMQ也有這兩種方式的實現,但是在實踐的過程中,就是不能順序消費,好不容易能夠實現順序消費了,發現採用併發消費的方式,消費的結果也是順序的,頓時就蒙圈了,到底怎麼回事?哪裡出了問題?百思不得其解。
經過多次調試,查看資料,debug跟蹤程序,最後終於搞清楚了,但是又不知道怎麼去寫這篇文章,是按部就班的講原理,講如何配置到最後實現,還是按照我的調試過程去寫呢?我覺得還是按照我的調試過程去寫這篇文章吧,因為我的調成過程應該和大多數人的理解思路是一致的,大家也更容易重視。
環境回顧
我們先來回顧一下前面搭建的RocketMQ的環境,這對於我們理解RocketMQ的順序消費是至關重要的。我們的RocketMQ環境是一個兩主兩從的異步集群,其中有兩個broker,broker-a和broker-b,另外,我們創建了兩個Topic,“cluster-topic”,這個Topic我們在創建的時候指定的是集群,也就是說我們發送消息的時候,如果Topic指定為“cluster-topic”,那麼這個消息應該在broker-a和broker-b之間負載;另外創建的一個Topic是“broker-a-topic”,這個Topic我們在創建的時候指定的是broker-a,當我們發送這個Topic的消息時,這個消息只會在broker-a當中,不會出現在broker-b中。
和大家羅嗦了這麼多,大家只要記住,我們的環境中有兩個broker,“broker-a”和“broker-b”,有兩個Topic,“cluster-topic”和“broker-a-topic”就可以了。
cluster-topic可以順序消費嗎
我們發送的消息,如果指定Topic為“cluster-topic”,那麼這種消息將在broker-a和broker-b直接負載,這種情況能夠做到順序消費嗎?我們試驗一下,
消費端的代碼如下:
@Bean(name = "pushConsumerOrderly", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer pushConsumerOrderly() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("pushConsumerOrderly");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("cluster-topic","*");
consumer.registerMessageListener((MessageListenerOrderly) (msgs, context) -> {
Random random = new Random();
try {
Thread.sleep(random.nextInt(5) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeOrderlyStatus.SUCCESS;
});
return consumer;
}
- 消費者組的名稱,連接的NameServer,訂閱的Topic,這裏就不多說了;
- 再來看一下註冊的消息監聽器,它是MessageListenerOrderly,順序消費,具體實現里我們打印出了消息體的內容,最後返回消費成功ConsumeOrderlyStatus.SUCCESS。
- 重點看一下打印語句之前的隨機休眠,這是非常重要的一步,它可以驗證消息是否是順序消費的,如果消費者是消費完一個消息以後,再去取下一個消息,那麼順序是沒有問題,但是如果消費者是併發地取消息,但是每個消費者的休眠時間又不一樣,那麼打印出來的就是亂序
生產端我們採用同步發送的方式,代碼如下:
@Test
public void producerTest() throws Exception {
for (int i = 0;i<5;i++) {
Message message = new Message();
message.setTopic("cluster-topic");
message.setKeys("key-"+i);
message.setBody(("this is simpleMQ,my NO is "+i+"---"+new Date()).getBytes());
SendResult sendResult = defaultMQProducer.send(message);
System.out.println("i=" + i);
System.out.println("BrokerName:" + sendResult.getMessageQueue().getBrokerName());
}
}
和前面一樣,我們發送5個消息,並且打印出i的值和broker的名稱,發送消息的順序是0,1,2,3,4,發送完成后,我們觀察一下消費端的日誌,如果順序也是0,1,2,3,4,那麼就是順序消費。我們運行一下,看看結果吧。
生產者的發送日誌如下:
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-b
發送5個消息,其中4個在broker-a,1個在broker-b。再來看看消費端的日誌:
this is simpleMQ,my NO is 3---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 0---Wed Jun 10 13:48:56 CST 2020
順序是亂的?怎麼回事?說明消費者在並不是一個消費完再去消費另一個,而是拉取了一個消息以後,並沒有消費完就去拉取下一個消息了,那這不是併發消費嗎?可是我們程序中設置的是順序消費啊。這裏我們就開始懷疑是broker的問題,難道是因為兩個broker引起的?順序消費只能在一個broker里才能實現嗎?那我們使用broker-a-topic這個試一下吧。
broker-a-topic可以順序消費嗎?
我們把上面的程序稍作修改,只把訂閱的Topic和發送消息時消息的Topic改為broker-a-topic即可。代碼在這裏就不給大家重複寫了,重啟一下程序,發送消息看看日誌吧。
生產者端的日誌如下:
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
我們看到5個消息都發送到了broker-a中,再來看看消費端的日誌,
this is simpleMQ,my NO is 0---Wed Jun 10 14:00:28 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 14:00:29 CST 2020
消費的順序還是亂的,這是怎麼回事?消息都在broker-a中了,為什麼消費時順序還是亂的?程序有問題嗎?review了好幾遍沒有發現問題。
問題排查
問題卡在這個地方,卡了好長時間,最後在官網的示例中發現,它在發送消息時,使用了一個MessageQueueSelector,我們也實現一下試試吧,改造一下發送端的程序,如下:
SendResult sendResult = defaultMQProducer.send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
return mqs.get(0);
}
},i);
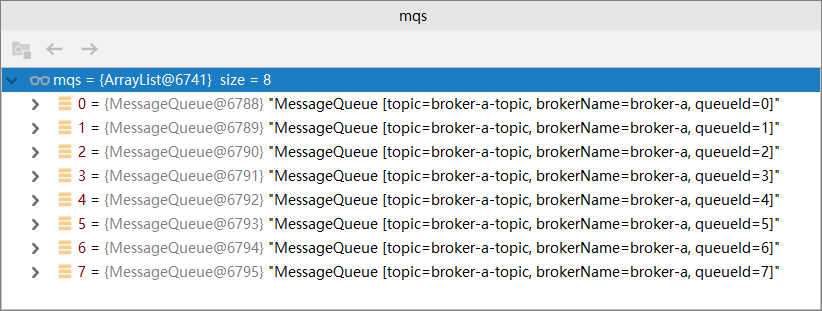
在發送的方法中,我們實現了MessageQueueSelector接口中的select方法,這個方法有3個參數,mq的集合,發送的消息msg,和我們傳入的參數,這個參數就是最後的那個變量i,大家不要漏了。這個select方法需要返回的是MessageQueue,也就是mqs變量中的一個,那麼mqs中有多少個MessageQueue呢?我們猜測是2個,因為我們只有broker-a和broker-b,到底是不是呢?我們打斷點看一下,
MessageQueue有8個,並且brokerName都是broker-a,原來Broker和MessageQueue不是相同的概念,之前我們都理解錯了。我們可以用下面的方式理解,
集群 ——–》 Broker ————》 MessageQueue
一個RocketMQ集群里可以有多個Broker,一個Broker里可以有多個MessageQueue,默認是8個。
那現在對於順序消費,就有了正確的理解了,順序消費是只在一個MessageQueue內,順序消費,我們驗證一下吧,先看看發送端的日誌,
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
5個消息都發送到了broker-a中,通過前面的改造程序,這5個消息應該都是在MessageQueue-0當中,再來看看消費端的日誌,
this is simpleMQ,my NO is 0---Wed Jun 10 14:21:40 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:21:41 CST 2020
這回是順序消費了,每一個消費者都是等前面的消息消費完以後,才去消費下一個消息,這就完全解釋的通了,我們再把消費端改成併發消費看看,如下:
@Bean(name = "pushConsumerOrderly", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer pushConsumerOrderly() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("pushConsumerOrderly");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("broker-a-topic","*");
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
Random random = new Random();
try {
Thread.sleep(random.nextInt(5) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
return consumer;
}
這回使用的是併發消費,我們再看看結果,
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
5個消息都在broker-a中,並且知道它們都在同一個MessageQueue中,再看看消費端,
this is simpleMQ,my NO is 1---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 0---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:28:00 CST 2020
是亂序的,說明消費者是併發的消費這些消息的,即使它們在同一個MessageQueue中。
總結
好了,到這裏終於把順序消費搞明白了,其中的關鍵就是Broker中還有多個MessageQueue,同一個MessageQueue中的消息才能順序消費。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化