前文我們聊了下docker容器的資源限制,回顧請參考https://www.cnblogs.com/qiuhom-1874/p/13138725.html;今天我們來聊一聊docker machine;docker machine是docker 官方提供的工具,這個工具可以在不同主機/不同系統上快速安裝、管理docker環境;docker machine 的實現原理就是通過不同的驅動來連接不同類型節點,來實現docker machine管理不同平台上的docker環境;
docker machine 安裝
1、下載二進製程序文件到本地
[root@node1 ~]# base=https://github.com/docker/machine/releases/download/v0.16.0 &&
> curl -L $base/docker-machine-$(uname -s)-$(uname -m) >/tmp/docker-machine &&
> sudo mv /tmp/docker-machine /usr/local/bin/docker-machine &&
> chmod +x /usr/local/bin/docker-machine
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 638 100 638 0 0 590 0 0:00:01 0:00:01 --:--:-- 590
100 26.8M 100 26.8M 0 0 11911 0 0:39:24 0:39:24 --:--:-- 16907
[root@node1 ~]# ll /usr/local/bin/docker-machine
-rwxr-xr-x 1 root root 28164576 Jun 18 11:28 /usr/local/bin/docker-machine
[root@node1 ~]# docker-machine version
docker-machine version 0.16.0, build 702c267f
[root@node1 ~]#
提示:以上命令主要就做了三件事,下載對應系統的對應系統架構的docker-machine到本地/tmp/下,並保存為docker-machine;然後把/tmp/docker-machine移動至/usr/local/bin/下,然後給/usr/local/bin/docker-machine添加執行權限;如果下載完我們可以在終端運行docker-machine version 能夠看到對應的版本信息,就表示docker-machine安裝好了;docker-machine程序是安裝好了,現在我們還不能直接使用;我們上面說過docker-machine本質就是通過不同的驅動去連接節點,連接節點實際上就是通過ssh鏈到節點服務器上,然後執行安裝docker;所以為了能夠很好的使用docker-machine 我們需要對管理的節點做免密登錄;
2、管理節點對work節點做免密登錄
[root@node1 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:4HrdVnoO+W/+J/ewP4A1m8HnneKWAKMKo3Ad2uExJ1k root@node1
The key's randomart image is:
+---[RSA 2048]----+
| |
| E |
| o. . |
| B... o = . |
| = B. S o + B o|
|. oo+. o . * = o.|
|... + o . * + = |
| . o . = +o+o|
| +++=B|
+----[SHA256]-----+
[root@node1 ~]# ssh-copy-id root@192.168.0.42
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '192.168.0.42 (192.168.0.42)' can't be established.
ECDSA key fingerprint is SHA256:EG9nua4JJuUeofheXlgQeL9hX5H53JynOqf2vf53mII.
ECDSA key fingerprint is MD5:57:83:e6:46:2c:4b:bb:33:13:56:17:f7:fd:76:71:cc.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@192.168.0.42's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@192.168.0.42'"
and check to make sure that only the key(s) you wanted were added.
[root@node1 ~]# ssh-copy-id root@192.168.0.43
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '192.168.0.43 (192.168.0.43)' can't be established.
ECDSA key fingerprint is SHA256:EG9nua4JJuUeofheXlgQeL9hX5H53JynOqf2vf53mII.
ECDSA key fingerprint is MD5:57:83:e6:46:2c:4b:bb:33:13:56:17:f7:fd:76:71:cc.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@192.168.0.43's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@192.168.0.43'"
and check to make sure that only the key(s) you wanted were added.
[root@node1 ~]
提示:有關免密登錄的詳細說明可以參考本人博客https://www.cnblogs.com/qiuhom-1874/p/11783371.html;接下來我們就可以使用docker-machine來對節點主機進行操作了;
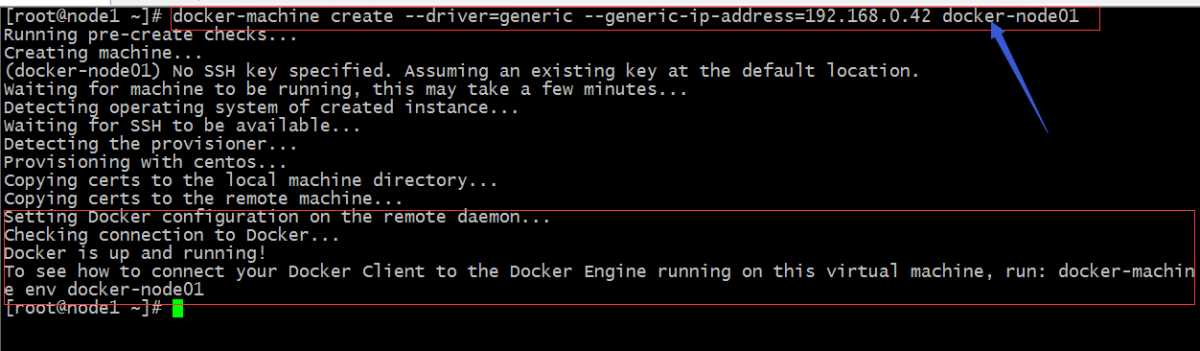
對節點主機安裝docker環境
提示:以上命令表示創建一個docker-machine主機,使用generic驅動,generic表示對linux主機,如果是windows需要用到–virtualbox;–generic-ip-address表示指定節點主機的ip地址;然後在給上一名稱;從上面的信息可以看到,docker-node01這台machine已經啟動,它告訴我們要查看怎麼連接docker-node01這台虛擬主機,請運行docker-machine env docker-node01 查看;
查看怎麼連接docker-node01這台虛擬主機
提示:它告訴我們運行下面的命令可以配置我們的shell
提示:從上面的信息可以看到我們運行 eval $(docker-machine env docker-node01)這條命令就表示把環境切換到docker-node01上;接下來的操作都會發送到docker node01上;
提示:從上面的信息可以看到,當我們使用eval $(docker-machine env docker-node01)把當前環境切換到docker-node01后,在當前終端運行的容器和下載的鏡像,在退出當前終端重新登錄后,本地的是沒有nginx鏡像的;這意味着我們切換環境后,運行容器的操作上發送給docker-node01上執行了;
測試:我們登錄到docker-node01看看是否有nginx鏡像和n1容器?
提示:用docker-machine創建虛擬主機來對節點主機管理時,我們給定虛擬主機的名稱docker-machine會把該名稱當作主機名,把節點主機的主機名更改為我們指定的名稱;從上面的信息可以看到docker-node01這台主機上有nginx鏡像和n1容器;這說明我們剛才的操作都是發送給docker-node01上了;從上面的演示可以看到,我們在docker-machine上切換環境,當前shell並不能反映我們是否切換到對應的環境了;這樣一來在主機特別多的情況,很容易出錯;接下來我們配置當前shell的PS1的環境變量;
下載docker-machine-wrapper.bash、docker-machine-prompt.bash和docker-machine.bash
[root@node01 ~]# cat /etc/bash_completion.d/down.bash
base=https://raw.githubusercontent.com/docker/machine/v0.16.0
for i in docker-machine-prompt.bash docker-machine-wrapper.bash docker-machine.bash
do
sudo wget "$base/contrib/completion/bash/${i}" -P /etc/bash_completion.d
done
[root@node01 ~]#
提示:以上腳本主要是循環下載上面說的三個腳本;執行該腳本直接有source命令即可;
提示:我們用source命令來執行上面的腳本,提示我們連接拒絕;這是因為沒有解析到raw.githubusercontent.com的地址造成的;解決辦法在/etc/hosts文件中介入raw.githubusercontent.com的解析地址即可;https://site.ip138.com/raw.githubusercontent.com/;這個網站可以查詢到raw.githubusercontent.com的地址;
提示:更改/etc/hosts文件后,接下在用source命令執行上面的腳本就不會提示我們鏈接拒絕了;
提示:可以看到/etc/bash_completion.d/目錄下有我們要的腳本了;接下來我們就需要配置當前用戶的PS1環境的值;
提示:以上信息表示導入上面的三個腳本到當前登錄用戶的終端;配置好以上.bashrc后,我們在來切換環境,當前shell就不一樣了;
提示:導入了docker-machine-wrapper.bash、docker-machine-prompt.bash和docker-machine.bash這三個腳本配合現在新定義的PS1變量,我們切換環境就很容易的辨識,我們操作的node節點主機是那一台;退出當前環境,直接使用exit即可;
到此docker-machine的環境就搭建好了;接下我們再來說說docker-machine的常用命令使用和說明
docker-machine active:查看當前激活狀態的docker主機
[root@node01 ~]# docker-machine active
docker-node01
[root@node01 ~]#
提示:所謂激活狀態的docker主機就是指的當前的DOCKER_HOST環境變量所指向的主機;
docker-machine ls:列出所有管理的主機
[root@node01 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
docker-node01 * generic Running tcp://192.168.0.42:2376 v19.03.11
docker-node02 - generic Running tcp://192.168.0.43:2376 v19.03.11
[root@node01 ~]#
docker-machine config:查看激活的docker主機的連接信息;
[root@node01 ~]# docker-machine config docker-node01
--tlsverify
--tlscacert="/root/.docker/machine/machines/docker-node01/ca.pem"
--tlscert="/root/.docker/machine/machines/docker-node01/cert.pem"
--tlskey="/root/.docker/machine/machines/docker-node01/key.pem"
-H=tcp://192.168.0.42:2376
[root@node01 ~]#
docker-machine inspect :以json格式輸出指定docker主機的詳細信息
[root@node01 ~]# docker-machine inspect docker-node01
{
"ConfigVersion": 3,
"Driver": {
"IPAddress": "192.168.0.42",
"MachineName": "docker-node01",
"SSHUser": "root",
"SSHPort": 22,
"SSHKeyPath": "",
"StorePath": "/root/.docker/machine",
"SwarmMaster": false,
"SwarmHost": "",
"SwarmDiscovery": "",
"EnginePort": 2376,
"SSHKey": ""
},
"DriverName": "generic",
"HostOptions": {
"Driver": "",
"Memory": 0,
"Disk": 0,
"EngineOptions": {
"ArbitraryFlags": [],
"Dns": null,
"GraphDir": "",
"Env": [],
"Ipv6": false,
"InsecureRegistry": [],
"Labels": [],
"LogLevel": "",
"StorageDriver": "",
"SelinuxEnabled": false,
"TlsVerify": true,
"RegistryMirror": [],
"InstallURL": "https://get.docker.com"
},
"SwarmOptions": {
"IsSwarm": false,
"Address": "",
"Discovery": "",
"Agent": false,
"Master": false,
"Host": "tcp://0.0.0.0:3376",
"Image": "swarm:latest",
"Strategy": "spread",
"Heartbeat": 0,
"Overcommit": 0,
"ArbitraryFlags": [],
"ArbitraryJoinFlags": [],
"Env": null,
"IsExperimental": false
},
"AuthOptions": {
"CertDir": "/root/.docker/machine/certs",
"CaCertPath": "/root/.docker/machine/certs/ca.pem",
"CaPrivateKeyPath": "/root/.docker/machine/certs/ca-key.pem",
"CaCertRemotePath": "",
"ServerCertPath": "/root/.docker/machine/machines/docker-node01/server.pem",
"ServerKeyPath": "/root/.docker/machine/machines/docker-node01/server-key.pem",
"ClientKeyPath": "/root/.docker/machine/certs/key.pem",
"ServerCertRemotePath": "",
"ServerKeyRemotePath": "",
"ClientCertPath": "/root/.docker/machine/certs/cert.pem",
"ServerCertSANs": [],
"StorePath": "/root/.docker/machine/machines/docker-node01"
}
},
"Name": "docker-node01"
}
[root@node01 ~]#
提示:以上命令也支持-f選項來指定格式,用法同docker image/container inspect 類似;
[root@node01 ~]# docker-machine inspect -f {{.HostOptions.AuthOptions.StorePath}} docker-node01
/root/.docker/machine/machines/docker-node01
[root@node01 ~]# docker-machine inspect -f {{.DriverName}} docker-node01
generic
[root@node01 ~]#
docker-machine ip :獲取指定docker主機的ip地址
[root@node01 ~]# docker-machine ip docker-node01
192.168.0.42
[root@node01 ~]# docker-machine ip docker-node02
192.168.0.43
[root@node01 ~]#
docker-machine ssh :連接指定docker執行命令
[root@node01 ~]# docker-machine ssh docker-node01 "ip a"
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:91:99:30 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.42/24 brd 192.168.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe91:9930/64 scope link
valid_lft forever preferred_lft forever
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:0f:e1:e0:f7 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:fff:fee1:e0f7/64 scope link
valid_lft forever preferred_lft forever
[root@node01 ~]#
docker-machine scp:在docker主機間以及docker主機和本地之間通過scp命令來遠程複製文件
[root@node01 ~]# echo "this is test file" > /tmp/test.txt
[root@node01 ~]# cat /tmp/test.txt
this is test file
[root@node01 ~]# docker-machine scp /tmp/test.txt docker-node01:/root/
test.txt 100% 18 5.4KB/s 00:00
[root@node01 ~]# docker-machine ssh docker-node01 "ls -l /root/"
total 4
-rw-r--r-- 1 root root 18 Jun 19 11:26 test.txt
[root@node01 ~]# docker-machine ssh docker-node01 "cat /root/test.txt"
this is test file
[root@node01 ~]#
提示:同scp命令用法類似;
docker-machine rm:刪除指定名稱的docker主機對應的虛擬主機;
[root@node01 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
docker-node01 * generic Running tcp://192.168.0.42:2376 v19.03.11
docker-node02 - generic Running tcp://192.168.0.43:2376 v19.03.11
[root@node01 ~]# docker-machine rm docker-node02
About to remove docker-node02
WARNING: This action will delete both local reference and remote instance.
Are you sure? (y/n): y
Successfully removed docker-node02
[root@node01 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
docker-node01 * generic Running tcp://192.168.0.42:2376 v19.03.11
[root@node01 ~]#
提示:docker-machine rm 只是刪除docker-machine上的虛擬主機,對於真正的物理節點上的docker環境並沒有刪除;實際上就切斷對指定docker主機的管控;
docker-machine upgrade:將指定主機的docker版本更新為最新
[root@node01 ~]# docker-machine upgrade docker-node01
Waiting for SSH to be available...
Detecting the provisioner...
Upgrading docker...
Restarting docker...
[root@node01 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
docker-node01 * generic Running tcp://192.168.0.42:2376 v19.03.11
[root@node01 ~]#
提示:如果指定docker主機的版本已經是最新的版本,那麼它將不會再更新;
docker-machine url:獲取指定主機監聽URL
[root@node01 ~]# docker-machine url docker-node01
tcp://192.168.0.42:2376
[root@node01 ~]#
提示:通過docker-machine安裝的docker環境,實際上就是把yum安裝的docker環境,客戶端和服務端分離了,各個節點就是各個服務端,而docker-machine就是同一的客戶端,因為客戶端和服務端不再同一主機,所以它會把docker監聽在一個TCP端口上,方便客戶端的來連接管理;
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?