環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?

菜菜哥,你換形象啦?
這麼巧,你也換啦!聽說是不會畫畫的菜嫂經過九牛二虎之力的功勞哦!鼓掌……
前幾天我出去面試了,面試官問我微服務的知識,我回答的可好了
看來微服務你真的下功夫研究了呀
是呀是呀,但是碰到一個問題,有狀態的服務是什麼意思呢?
看來你又掛在這個問題上了,且聽這次分解
對於初學者,心裏對“有狀態服務”的理解可能比較模糊,但是從面向對象編程思想的角度去理解也許會明朗很多。面向對象編程思想提倡的是用編程語言去描述世間萬物,所以面向對象編程的語言都會提供描述對象的容器以及對象行為的表達方式。舉一個很簡單的栗子,在c#或者java中,表達對象的容器就是class,對象的行為通過一系列的接口或者函數來表達。更進一步,對象抽象出來之後,大多數對象都有自己的內部狀態,體現到代碼上也就是常見的類的屬性。
面向對象編程的基本思想本質上是對現實世界的一種抽象,萬物皆可抽象。
根據業務把對象抽象出來之後,每一個實例化的對象其實都可以有自己的狀態,比如:在最常見的遊戲場景中,每一個玩家都是“玩家”這類對象的一個實例,每一個玩家都有自己的名字,性別,等級,HP等屬性,這些屬性本質上就是玩家的狀態,隨着時間的推移,每個玩家的HP,等級等屬性會隨之變化,這些變化其實就是這個玩家狀態的變化。對應到有狀態的服務也是如此,之所以稱之為有狀態,是因為服務內部的對象狀態會隨着業務有着對應的變動,而這些變動只發生在這個服務內部,在外界看來,這個服務好像是有狀態的。
有狀態的服務本質上是一些有狀態對象的集合,這些對象狀態的變化只發生在當前服務進程中。
有狀態服務之所以被稱為有狀態,一個很大的原因是它可以追溯狀態的變化過程,也就是說一個有狀態的服務保存着狀態變化的記錄,並可以根據這些歷史記錄恢復到指定的狀態,這在很多場景下非常有用。舉一個很簡單的栗子:我們平時玩的斗地主遊戲,三個玩家,當有一個玩家因為網絡原因掉線,經過一段時間,這個玩家又重新上線,需要根據某些記錄來恢復玩家掉線期間系統自動出牌的記錄,這些出牌記錄在這個業務中其實就是這個玩家的狀態變化記錄。在有狀態的服務中,很容易做到這一點。
其實實際開發中很多場景不需要記錄每個狀態的變化,只保留最新狀態即可,不單單是因為保存每個狀態的變化需要大量的存儲和架構設計,更因為是很多業務根本不需要這些狀態變化記錄,業務需要的只是最新的狀態,所以大部分有狀態的服務只保存着最新的狀態。
有狀態的服務在設計難度上比無狀態的服務要大很多,不僅僅是因為開發設計人員需要更好的抽象能力,更多的是一致性的設計問題。現代的分佈式系統,都是由多個服務器組成一個集群來對外提供服務,當一個對象在服務器A產生之後,如果請求被分配到了服務器B上,這種情況下有狀態的服務毫無意義,為什麼呢?當一個相同的業務對象存在於不同的服務器上的時候,本質上就違背了現實世界的規則,你能說一個人,即出生在中國,又出生在美國嗎? 所以有狀態的服務對於一致性問題有着天然的要求,這種思想和微服務設計理想不謀而合,舉個栗子:一個用戶信息的服務,對外提供查詢修改能力,凡是用戶信息的業務必須通過這個服務來實現。同理,一個對象狀態的查詢修改以及這個對象的行為,必須由這個對象的服務來完成。
有狀態的服務要求相同業務對象的請求必須被路由到同一個服務進程。
因此,有狀態的服務對於同一個對象的橫向擴容是做不到的,就算是做的到,多個相同對象之間的狀態同步工作也必然會花費更多的資源。在很多場景下,有狀態的服務要注意熱點問題,例如最常見的秒殺,這裏並非是說有狀態服務不適合大併發的場景,反而在高併發的場景下,有狀態的服務往往表現的比無狀態服務更加出色。
在眾多的併發模型中,最適合有狀態服務設計的莫過於Actor模型了,如果你對actor模型還不熟悉,可以擼一遍菜菜之前的文章:https://mp.weixin.qq.com/s/eEiypRysw5jsC7iYUp_yAg actor模型天生就具備了一致性這種特點,讓我們在對業務進行抽象的時候,不必考慮一致性的問題,而且每一個請求都是異步模式,在對象內部修改對象的狀態不必加鎖,這在傳統的架構中是做不到的。
基於actor模型,系統設計的難點在於抽象業務模型,一旦業務模型穩定,我們完全可以用內存方式來保存對象狀態(也可以定時去持久化),內存方式比用其他網絡存儲(例如redis)要快上幾個量級,菜菜也有一篇文章大家可以去擼一下:https://mp.weixin.qq.com/s/6YL3SnSriKEnpCyB5qkk0g ,既滿足了一致性,又可以利用進程內對象狀態來應對高併發業務場景,何樂而不為呢?
有不少同學問過我,actor模型要避免出現熱點問題,就算有內存狀態為其加速,那併發數還是超過actor的處理能力怎麼辦呢? 其實和傳統做法類似,所有的高併發系統設計無非就是“分”一個字,無論是簡單的負載均衡,還是複雜的分庫分表策略,都是分治的一種體現。一台服務器不夠,我就上十台,百台…..
所有的高併發系統設計都是基於分治思想,把每一台服務器的能力發揮到極致,難度最大的還是其中的調度算法。
用actor模型來應對高併發,我們可以採用讀寫分離的思想,主actor負責寫請求,並利用某種通信機制把狀態的變化通知到多個從actor,從actor負責對外的讀請求,這個DB的讀寫分離思想一致,其中最難的當屬actor的狀態同步問題了,解決問題的方式千百種,總有一種適合你,歡迎你留言寫下你認為最好的解決方案。
由於菜菜是c#出身,對c#的Actor服務框架Orleans比較熟悉,這裏就以Orleans為例,其他語言的coder不要見怪,Orleans是一個非常優秀的Actor模型框架,而且支持最新的netcore 3.0版本,地址為:https://github.com/dotnet/orleans 有興趣的同學可以去看一下,而且分佈式事物已經出正式版,非常給力。其他語言的也非常出色java:https://github.com/akka/akka
golang:
1. 首先我們定義玩家的狀態信息
//玩家的信息,其實也就是玩家的狀態信息
public class Player {
/// <summary>
/// 玩家id,同時也是玩家這個服務的主鍵
/// </summary>
public long Id { get; set; }
/// <summary>
/// 玩家姓名
/// </summary>
public string Name { get; set; }
/// <summary>
/// 玩家等級
/// </summary>
public int Level { get; set; }
}
2. 接下來定義玩家的服務接口
/// <summary>
/// 玩家的服務接口
/// </summary>
interface IPlayerService: Orleans.IGrainWithIntegerKey
{
//獲取玩家名稱
Task<string> GetName();
//獲取玩家等級
Task<int> GetLevel();
//設置玩家等級,這個操作會改變玩家的狀態
Task<int> SetLevel(int newLevel);
}
3. 接下來實現玩家服務的接口
public class PlayerService : Grain, IPlayerService
{
//這裏可以用玩家的信息來代表玩家的狀態信息,而且這個狀態信息又充當了進程內緩存的作用
Player playerInfo;
public async Task<int> GetLevel()
{
return (await LoadPlayer()).Level;
}
public async Task<string> GetName()
{
return (await LoadPlayer()).Name;
}
public async Task<int> SetLevel(int newLevel)
{
var playerInfo =await LoadPlayer();
if (playerInfo != null)
{
//先進行數據庫的更新,然後在更新緩存的狀態, 進程內緩存更新失敗的幾率幾乎為0
playerInfo.Level = newLevel;
}
return 1;
}
private async Task< Player> LoadPlayer()
{
if (playerInfo == null)
{
var id = this.GetPrimaryKeyLong();
//這裏模擬的信息,真實環境完全可以從持久化設備進行讀取
playerInfo= new Player() { Id = id, Name = "玩家姓名", Level = 1 };
}
return playerInfo;
}
}以上只是一個簡單案例,有狀態的服務還有更多的設計方案,以上只供參考完
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?
摘錄自2020年2月24日中央社報導
臉書(Facebook)前永續部門主管魏爾(Bill Weihl)宣布創立新組織「氣候之聲」(ClimateVoice),協助大企業員工對老闆施壓,以拿出更積極的政策對抗氣候變遷。
2018年離開臉書的魏爾說:「當一個議題對社會整體可能很重要、卻未直接影響到企業時,基本上大多數企業多數時間都會保持沈默。」
「氣候之聲」一開始將以志工方式運作,但希望不久後能募得資金並雇用員工。魏爾表示,「氣候之聲」將推動科技業員工組織並強化氣候變遷倡議運動,以施壓公司高層對相關立法進行遊說。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?
摘錄自2020年2月25日中央社報導
南極洲這個月初遭為期九天的熱浪侵襲,位於南極洲東北端的鷹島(Eagle Island)約20%積雪融化,這是日益加劇的氣候危機所帶來的普遍徵兆。
NASA地球觀測站表示,僅一週左右時間,鷹島的積雪就融化4英吋(約10公分),大約占該島季節性積雪總量的20%。
麻薩諸塞州尼柯斯學院(Nichols College)地理學家裴爾托(Mauri Pelto)告訴NASA觀測站:「我從未看過南極洲冰雪融化形成水池的速度如此之快。你可以在阿拉斯加和格陵蘭看到這樣的融冰現象,但南極洲很罕見。」
氣候學家費特韋斯(Xavier Fettweis)繪出從南極半島流入海水的融冰量,並指出熱浪是造成今夏海平面上升的最大主因。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?
摘錄自2020年02月26日中央社報導
日本女川核電廠2號機以重啟運轉為前提的申請,已通過日本原子力規制委員會審查,成為位於311大地震重災區首座合格的核電廠,也是第2座遭受海嘯侵襲重生的核電廠。
日本放送協會(NHK)報導,東北電力公司希望位於宮城縣的女川核電廠2號機能重啟運轉提出申請,日本原子力規制委員會今(26日)已正式彙整完成表示合格的審查書。
女川核電廠2號機是位於2011年311大地震後遭受重創的東北地方,首度獲審查合格的核電廠機組。東北電力公司在311大地震2年後的2013年,以重啟運轉為前提向原子力規制委員會提出審查申請。
持續進行審議的原子力規制委員會,2019年11月彙整出表示事實上符合新規範標準的審查書草案,並向一般民眾徵集意見。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?
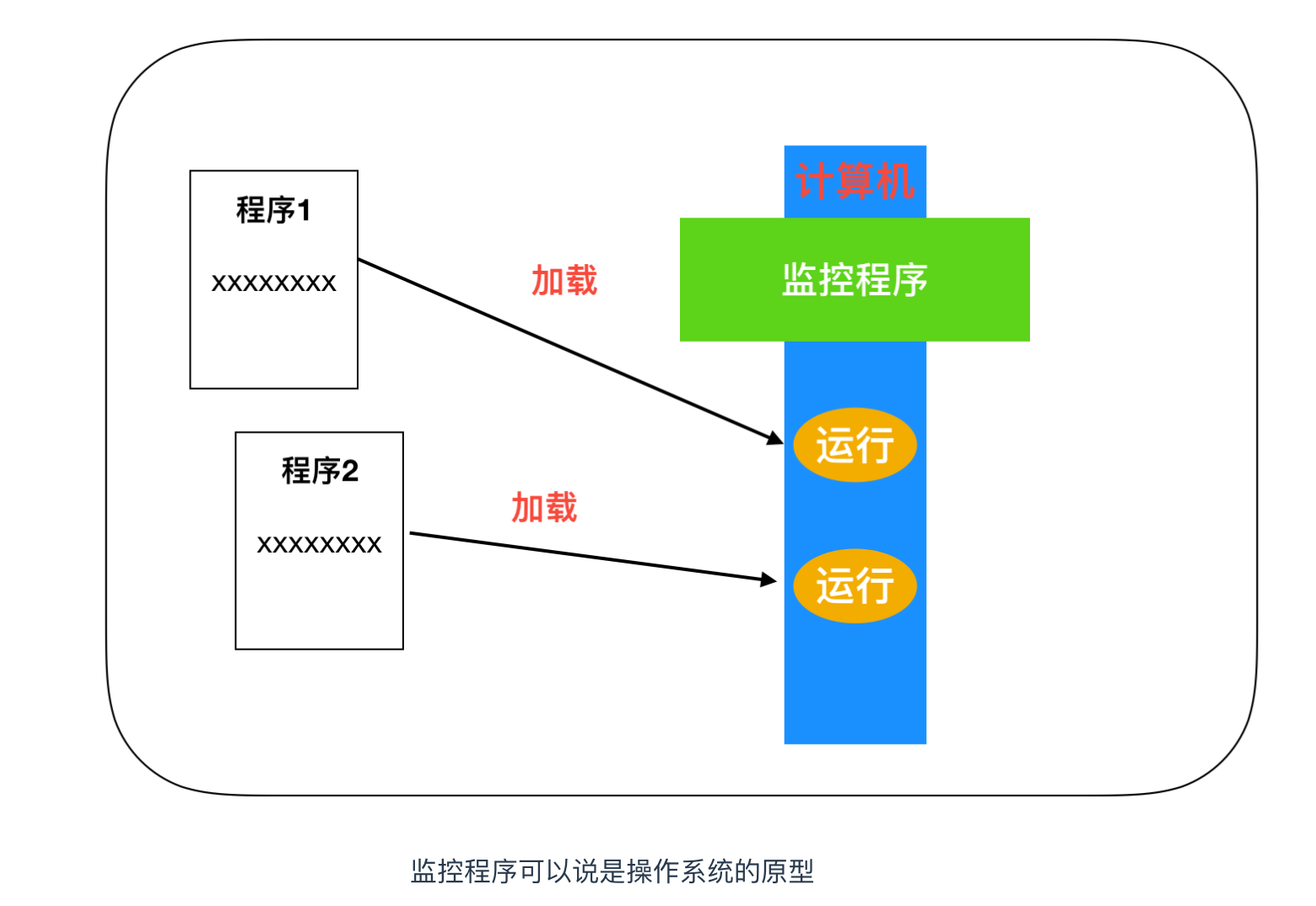
利用計算機運行程序大部分都是為了提高處理效率。例如,Microsoft Word 這樣的文字處理軟件,是用來提高文本文件處理效率的程序,Microsoft Excel 等表格計算軟件,是用來提高賬本處理效率的程序。這種為了提高特定處理效率的程序統稱為 應用
程序員的工作就是編寫各種各樣的應用來提高工作效率,程序員一般不編寫操作系統,但是程序員編寫的應用離不開操作系統,此篇文章我們就針對 Windows 操作系統來說明一下操作系統和應用之間的關係。
操作系統其實也是一種軟件,任何新事物的出現肯定都有它的歷史背景,那麼操作系統也不是憑空出現的,肯定有它的歷史背景。
在計算機尚不存在操作系統的年代,完全沒有任何程序,人們通過各種按鈕來控制計算機,這一過程非常麻煩。於是,有人開發出了僅具有加載和運行功能的監控程序,這就是操作系統的原型。通過事先啟動監控程序,程序員可以根據需要將各種程序加載到內存中運行。雖然仍舊比較麻煩,但比起在沒有任何程序的狀態下進行開發,工作量得到了很大的緩解。
隨着時代的發展,人們在利用監控程序編寫程序的過程中發現很多程序都有公共的部分。例如,通過鍵盤進行文字輸入,显示器進行數據展示等,如果每編寫一個新的應用程序都需要相同的處理的話,那真是太浪費時間了。因此,基本的輸入輸出部分的程序就被追加到了監控程序中。初期的操作系統就是這樣誕生了。
類似的想法可以共用,人們又發現有更多的應用程序可以追加到監控程序中,比如硬件控製程序,編程語言處理器(彙編、編譯、解析)以及各種應用程序等,結果就形成了和現在差異不大的操作系統,也就是說,其實操作系統是多個程序的集合體。
我在 這篇文章中提到了彙編語言,這裏簡單再提一下。
彙編語言是一種低級語言,也被稱為
符號語言。彙編語言是第二代計算機語言,在彙編語言中,用助記符代替機器指令的操作碼,用地址符號或標號代替指令或操作數的地址。用一些容易理解和記憶的字母,單詞來代替一個特定的指令,比如:用ADD代表数字邏輯上的加減,MOV代表數據傳遞等等,通過這種方法,人們很容易去閱讀已經完成的程序或者理解程序正在執行的功能,對現有程序的bug修復以及運營維護都變得更加簡單方便
可以說共用思想真是人類前進的一大步,對於解放生產力而言簡直是太重要了。
對於程序員來說,程序員創造的不是硬件,而是各種應用程序,但是如果程序員只做應用不懂硬件層面的知識的話,是無法成為硬核程序員的。現在培訓機構培養出了一批怎麼用的人才,卻沒有培訓出為什麼這麼做的人才,畢竟為什麼不是培訓機構教的,而是學校教的,我很相信耗子叔說的話:學習沒有速成這回事。言歸正題。
在操作系統誕生之後,程序員不需要在硬件層面考慮問題,所以程序員的數量就增加了。哪怕自稱對硬件一竅不通的人也可能製作出一個有模有樣的程序。不過,要想成為一個全面的程序員,有一點需要清楚的就是,掌握硬件的基本知識,並藉助操作系統進行抽象化,可以大大提高編程效率。
下面就看一下操作系統是如何給開發人員帶來便利的,在 Windows 操作系統下,用 C 語言製作一個具有表示當前時間功能的應用。time() 是用來取得當前日期和時間的函數,printf() 是把結果打印到显示器上的函數,如下:
#include <stdio.h>
#include <time.h>
void main(){
// 保存當前日期和時間信息
time_t tm;
// 取得當前的日期和時間
time(&tm);
// 在显示器上显示日期和時間
printf("%s\n", ctime(&tm));
}讀者可以自行運行程序查看結果,我們主要關注硬件在這段代碼中做了什麼事情
應用的可執行文件指的是,計算機的 CPU 可以直接解釋並運行的本地代碼,不過這些代碼是無法直接控制硬件的,事實上,這些代碼是通過操作系統來間接控制硬件的。變量中涉及到的內存分配情況,以及 time() 和 printf() 這些函數的運行結果,都不是面向硬件而是面向操作系統的。操作系統收到應用發出的指令后,首先會對該指令進行解釋,然後會對 時鐘IC 和显示器用的 I/O 進行控制。
計算機中都安裝有保存日期和時間的實時時鐘(Real-time clock),上面提到的時鐘IC 就是值該實時時鐘。
操作系統控制硬件的功能,都是通過一些小的函數集合體的形式來提供的。這些函數以及調用函數的行為稱為系統調用,也就是通過應用進而調用操作系統的意思。在前面的程序中用到了 time() 以及 printf() 函數,這些函數內部也封裝了系統調用。
C 語言等高級編程語言並不依存於特定的操作系統,這是因為人們希望不管是Windows 操作系統還是 Linux 操作系統都能夠使用相同的源代碼。因此,高級編程語言的機制就是,使用獨自的函數名,然後在編譯的時候將其轉換為系統調用的方式(也有可能是多個系統調用的組合)。也就是說,高級語言編寫的應用在編譯后,就轉換成了利用系統調用的本地代碼。
不過,在高級語言中也存在直接調用系統調用的編程語言,不過,利用這種方式做成應用,移植性並不友好。
移植性:移植性指的是同樣的程序在不同操作系統下運行時所花費的時間,時間越少證明移植性越好。
通過使用操作系統提供的系統調用,程序員不必直接編寫控制硬件的程序,而且,通過使用高級編程語言,有時也無需考慮系統調用的存在,系統調用往往是自動觸發的,操作系統和高級編程語言能夠使硬件抽象化,這很了不起。
下面讓我們看一個硬件抽象化的具體實例
#include <stdio.h>
void main(){
// 打開文件
FILE *fp = fopen("MyFile.txt","w");
// 寫入文件
fputs("你好", fp);
// 關閉文件
fclose(fp);
}上述代碼使用 C 編寫的程序,fputs() 是用來往文件中寫入字符串的函數,fclose() 是用來關閉文件的函數。
上述應用在編譯運行后,會向文件中寫入 “你好” 字符串。文件是操作系統對磁盤空間的抽象化,就如同我們在 這篇文章提到的一樣,磁盤就如同樹的年輪,磁盤的讀寫是以扇區為單位的,通過磁道來尋址,如果直接對硬件讀寫的話,那麼就會變為通過向磁盤用的 I/O 指定扇區位置來對數據進行讀寫了。
但是,在上面代碼中,扇區壓根就沒有出現過傳遞給 fopen() 函數的參數,是文件名 MyFile.txt 和指定文件寫入的 w。傳遞給 fputs() 的參數,是往文件中寫入的字符串”你好” 和 fp,傳遞給 fclose() 的參數,也僅僅是 fp,也就是說磁盤通過打開文件這個操作,把磁盤抽象化了,打開文件這個操作就可以說是操作硬件的指令。
下面讓我們來看一下代碼清單中 fp 的功能,變量 fp 中被賦予的是 fopen() 函數的返回值,該值被稱為文件指針。應用打開文件后,操作系統就會自動申請分配用來管理文件讀寫的內存空間。內存地址可以通過 fopen() 函數的返回值獲得。用 fopen() 打開文件后,接下來就是通過制定的文件指針進行操作,正因為如此,fputs() 和 fclose() 以及 fclose() 參數中都制定了文件指針。
由此我們可以得出一個結論,應用程序是通過系統調用,磁盤抽象來實現對硬盤的控制的。
Windows 操作系統是世界上用戶數量最龐大的群體,作為 Windows 操作系統的資深用戶,你都知道 Windows 操作系統有哪些特徵嗎?下面列舉了一些 Windows 操作系統的特性
API 函數集成來提供系統調用WYSIWYG 實現打印輸出,WYSIWYG 其實就是 What You See Is What You Get ,值得是显示器上显示的圖形和文本都是可以原樣輸出到打印機打印的。這些是對程序員來講比較有意義的一些特徵,下面針對這些特徵來進行分別的介紹
這裏表示的32位操作系統表示的是處理效率最高的數據大小。Windows 處理數據的基本單位是 32 位。這與最一開始在 MS-DOS 等16位操作系統不同,因為在16位操作系統中處理32位數據需要兩次,而32位操作系統只需要一次就能夠處理32位的數據,所以一般在 windows 上的應用,它們的最高能夠處理的數據都是 32 位的。
比如,用 C 語言來處理整數數據時,有8位的 char 類型,16位的short類型,以及32位的long類型三個選項,使用位數較大的 long 類型進行處理的話,增加的只是內存以及磁盤的開銷,對性能影響不大。
現在市面上大部分都是64位操作系統了,64位操作系統也是如此。
Windows 是通過名為 API 的函數集來提供系統調用的。API是聯繫應用程序和操作系統之間的接口,全稱叫做 Application Programming Interface,應用程序接口。
當前主流的32位版 Windows API 也稱為 Win32 API,之所以這樣命名,是需要和不同的操作系統進行區分,比如最一開始的 16 位版的 Win16 API,和後來流行的 Win64 API 。
API 通過多個 DLL 文件來提供,各個 API 的實體都是用 C 語言編寫的函數。所以,在 C 語言環境下,使用 API 更加容易,比如 API 所用到的 MessageBox() 函數,就被保存在了 Windows 提供的 user32.dll 這個 DLL 文件中。
GUI(Graphical User Interface) 指得就是圖形用戶界面,通過點擊显示器中的窗口以及圖標等可視化的用戶界面,舉個例子:Linux 操作系統就有兩個版本,一種是簡潔版,直接通過命令行控制硬件,還有一種是可視化版,通過光標點擊圖形界面來控制硬件。
WYSIWYG 指的是显示器上輸出的內容可以直接通過打印機打印輸出。在 Windows 中,显示器和打印機被認作同等的圖形輸出設備處理的,該功能也為 WYSIWYG 提供了條件。
藉助 WYSIWYG 功能,程序員可以輕鬆不少。最初,為了是現在显示器中显示和在打印機中打印,就必須分別編寫各自的程序,而在 Windows 中,可以藉助 WYSIWYG 基本上在一個程序中就可以做到显示和打印這兩個功能了。
多任務指的就是同時能夠運行多個應用程序的功能,Windows 是通過時鐘分割技術來實現多任務功能的。時鐘分割指的是短時間間隔內,多個程序切換運行的方式。在用戶看來,就好像是多個程序在同時運行,其底層是 CPU 時間切片,這也是多線程多任務的核心。
Windows 中,網絡功能是作為標準功能提供的。數據庫(數據庫服務器)功能有時也會在後面追加。網絡功能和數據庫功能雖然並不是操作系統不可或缺的,但因為它們和操作系統很接近,所以被統稱為中間件而不是應用。意思是處於操作系統和應用的中間層,操作系統和中間件組合在一起,稱為系統軟件。應用不僅可以利用操作系統,也可以利用中間件的功能。
相對於操作系統一旦安裝就不能輕易更換,中間件可以根據需要進行更換,不過,對於大部分應用來說,更換中間件的話,會造成應用也隨之更換,從這個角度來說,更換中間件也不是那麼容易。
即插即用(Plug-and-Play)指的是新的設備連接(plug) 后就可以直接使用的機制,新設備連接計算機后,計算機就會自動安裝和設定用來控制該設備的驅動程序
設備驅動是操作系統的一部分,提供了同硬件進行基本的輸入輸出的功能。鍵盤、鼠標、显示器、磁盤裝置等,這些計算機中必備的硬件的設備驅動,一般都是隨操作系統一起安裝的。
有時 DLL 文件也會同設備驅動文件一起安裝。這些 DLL 文件中存儲着用來利用該新追加的硬件API,通過 API ,可以製作出運行該硬件的心應用。
文章參考:
《程序是怎樣跑起來的》第九章
關注公眾號後台回復 191106 即可獲得《程序是怎樣跑起來的》电子書
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?

上一篇講了CSS浮動 博客地址:
我們前面說過,浮動本質是用來做一些文字混排效果的,但是被我們拿來做布局用,則會有很多的問題出現。
由於浮動元素不再佔用原文檔流的位置,所以它會對後面的元素排版產生影響,為了解決這些問題,此時就需要在該元素中清除浮動。
準確地說,並不是清除浮動,而是清除浮動后造成的影響
清除浮動的本質: 主要為了解決父級元素因為子級浮動引起內部高度為0 的問題。
我們來詳細解釋下這句話
再解釋下就是在標準流下面一個父div沒有設置高度屬性,那麼它的高度就會被子元素的高度撐開。但是如果這個父div中的子元素是浮動的話,如果父div下面再有
一個兄弟div,那麼這個兄弟div就會遮擋這個父元素。這個現象也叫浮動溢出。
示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
.father {
height: 200px;
border: 1px solid red;
width: 300px
}
.big {
width: 100px;
height: 100px;
background-color: purple;
float: left;
}
.small {
width: 80px;
height: 80px;
background-color: blue;
float: left;
}
.footer {
width: 400px;
height: 100px;
background-color: pink;
}
</style>
</head>
<body>
<div class="father"> 父div
<div class="big">子div</div>
<div class="small">子div</div>
</div>
<div class="footer">兄弟div</div>
</body>
</html>運行結果
很明顯這裏,div1和div2已經上浮,而兄弟div就往上移動。這裏因為父div有文字所以佔了點高度,不然兄弟div會完全覆蓋父div。
當然我們可以通過設置父div的高度,來使它不被兄弟div所覆蓋。比如這裏設置 height: 200px;
在刷新下頁面
當父div設置高度后,被覆蓋的問題卻是解決了,但在很多時候我們是不會去設置父div的高度,因為很多時候我們都不知道父div的高度要設置多少。
所以這個時候需要思考解決這個問題。
清除浮動的方法本質: 就是把父盒子里浮動的盒子圈到裏面,讓父盒子閉合出口和入口不讓他們出來影響其他元素。
在CSS中,clear屬性用於清除浮動。
基本語法格式
選擇器 {clear:屬性值;}屬性值
通過在浮動元素末尾添加一個空的標籤,例如
<div style="clear:both"></div>我們在上面的代碼添加
<body>
<div class="father"> 父div
<div class="big">子div</div>
<div class="small">子div</div>
<div style="clear:both"></div> <!-- 只需在父盒子里最後面添加這個空標籤添加clear:both屬性就可以清除浮動 -->
</div>
<div class="footer">兄弟div</div>
</body>運行結果
完美解決了。
優點 通俗易懂,書寫方便。
缺點 添加無意義的標籤,結構化較差。
可以通過觸發BFC的方式,可以實現清除浮動效果。(BFC後面會講)
可以給父級元素添加: overflow為 hidden|auto|scroll 都可以實現。我們將上面代碼修改為
<body>
<div class="father" style="overflow: hidden;"> 父div <!-- 父元素添加 overflow: hidden -->
<div class="big">子div</div>
<div class="small">子div</div>
</div>
<div class="footer">兄弟div</div>
</body>也是能實現去除浮動的效果。
優點 代碼簡潔
缺點 內容增多時候容易造成不會自動換行導致內容被隱藏掉,無法显示需要溢出的元素。
3、使用after偽元素清除浮動
:after 方式為空元素的升級版,好處是不用單獨加標籤了** 示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>使用after偽元素清除浮動</title>
<style>
.clearfix:after { /*正常瀏覽器 清除浮動*/
content:"";
display: block;
height: 0;
clear: both;
visibility: hidden;
}
.clearfix {
*zoom: 1; /*zoom 1 就是ie6 清除浮動方式 * ie7一下的版本所識別*/
}
.father {
border: 1px solid red;
width: 300px;
}
.big {
width: 100px;
height: 100px;
background-color: purple;
float: left;
}
.small {
width: 80px;
height: 80px;
background-color: blue;
float: left;
}
.footer {
width: 400px;
height: 100px;
background-color: pink;
}
</style>
</head>
<body>
<div class="father clearfix">
<div class="big"></div>
<div class="small"></div>
</div>
<div class="footer"></div>
</body>
</html>優點 符合閉合浮動思想 結構語義化正確
缺點 由於IE6-7不支持:after,使用 zoom:1觸發 hasLayout。
注意: content:”.” 裏面盡量跟一個小點,或者其他,盡量不要為空,否則再firefox 7.0前的版本會有生成空格。
4、使用before和after雙偽元素清除浮動
使用方法 將上面的clearfix樣式替換成如下
.clearfix:before, .clearfix:after {
content: "";
display: table;
}
.clearfix:after {
clear: both;
}
.clearfix {
*zoom: 1;
}優點 代碼更簡潔
缺點 由於IE6-7不支持:after,使用 zoom:1觸發 hasLayout。
1、在網頁主要布局時使用:after偽元素方法並作為主要清理浮動方式.文檔結構更加清晰;
2、在小模塊如ul里推薦使用overflow:hidden;(同時留意可能產生的隱藏溢出元素問題);你如果願意有所作為,就必須有始有終。(9)本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?

 |
先前在媒體上熱烈討論的電動車 Gogoro 繼續以生活品味為主打形象,這次與時裝雜誌的活動結合,試圖要把騎機車這件事事情變得更潮。Gogoro 獲邀參與 GQ 紳裝正義 2016 SUIT WALK 遊行與派對活動。
為響應 GQ 派對主題,Gogoro 也舉辦「紳士有禮」體驗,只要消費者在 Taipei 101 四樓 Gogoro 展區完成最新智慧解鎖、拍照分享後即可獲得神秘限定騎乘邀請函,現場亦可索取潮男限定試騎卷,憑卷在 3 月 14 日白色情人節到 Gogoro 信義全球體驗中心試騎,即可獲得 Gogoro 限量潮 T 一件,數量有限敬請把握! Gogoro 執行長暨創辦人陸學森表示:「Gogoro 非常榮幸可以成為這次時尚盛會中唯一的二輪交通品牌,我們希望鼓勵無論男性女性,時時刻刻都用各式方式展現自己的風格,例如 Smartscooter® 智慧雙輪可以讓消費者更換不同設計的面板,也是希望突破機車只是交通工具的想像,讓智慧雙輪不僅可以帶你帥氣的在城市間遊走、也可以透過不同的面板造型與設計,讓車主展現你獨一無二的個人風格。」
 |
▲ 全球最時尚大叔 Nick Wooster 稱讚 Gogoro 智慧雙輪時尚外型最合紳士出遊。(Source:Gogoro) 紳裝正義活動到 2016 年已經是第三屆舉行,從 2014 年開始主辦人就串連台灣、香港、新加坡與上海等亞洲時尚重地,邀請所有的型男紳士在每年白色情人節期間,穿上最時尚、最具個人風格的西裝到街頭遊行展現紳士魅力。此次 Gogoro 除了是唯一受邀參加遊行的交通工具品牌之外,遊行後也與其他時尚品牌如 Porches、HUGO BOSS、瑞士頂級 Zenith 真力時手錶等,於 Taipei 101 四樓參與 GQ 紳裝正義派對,在現場展現如何透過科技時尚魅力、展現自我風格。
 |
▲ 時尚男孩小杰帶領 Gogoro 型男軍團參與 GQ 紳裝正義遊行。(Source:Gogoro) (首圖說明:Gogoro 型男軍團參與GQ SUIT WALK 2016 於台北101時尚派對。Source:Gogoro) (本文授權轉載自《》─〈〉)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?
1. ArrayList 和Vector 的區別
ArrayList和Vector底層實現原理都是一樣得,都是使用數組方式存儲數據
Vector是線程安全的,但是性能比ArrayList要低。
ArrayList,Vector主要區別為以下幾點:
(1):Vector是線程安全的,源碼中有很多的synchronized可以看出,而ArrayList不是。導致Vector效率無法和ArrayList相比;
(2):ArrayList和Vector都採用線性連續存儲空間,當存儲空間不足的時候,ArrayList默認增加為原來的50%,Vector默認增加為原來的一倍;
(3):Vector可以設置capacityIncrement,而ArrayList不可以,從字面理解就是capacity容量,Increment增加,容量增長的參數。
2.說說ArrayList,Vector, LinkedList 的存儲性能和特性
ArrayList採用的數組形式來保存對象,這種方法將對象放在連續的位置中,所以最大的缺點就是插入和刪除的時候比較麻煩,查找比較快;
Vector使用了sychronized方法(線程安全),所以在性能上比ArrayList要差些.
LinkedList採用的鏈表將對象存放在獨立的空間中,而且在每個空間中還保存下一個鏈表的索引。使用雙向鏈表方式存儲數據,按序號索引數據需要前向或後向遍曆數據,所以索引數據慢,是插入數據時只需要記錄前後項即可,所以插入的速度快。
3.快速失敗(fail-fast) 和安全失敗(fail-safe) 的區別是什麼?
1.快速失敗
原理是:
迭代器在遍歷時直接訪問集合中的內容,並且在遍歷過程中使用一個modCount變量。集合在被遍歷期間如果內容發生變化,就會改變modCount的值。每當迭代器使用hasNext()或next()遍歷下一個元素之前,都會先檢查modCount變量是否為expectmodCount值。如果是的話就返回遍歷;否則拋出異常,終止遍歷。
查看ArrayList源碼,在next方法執行的時候,會執行checkForComodification()方法。
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1 ;
return (E) elementData[lastRet = i];
}
final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }
這裏異常的拋出條件是modCount != expectedModCount這個條件。如果集合發生變化時修改modCount值剛好又設置為了expectedModCount值,則異常不會拋出。因此,不能依賴於這個異常是否拋出而進行併發操作,這個異常只建議用於檢測併發修改的bug。
2.安全失敗
採用安全失敗機制的集合容器,在遍歷時不是直接在集合上訪問的,而是先複製原有集合內容,在拷貝的集合上進行遍歷。
原理:
由於迭代時是對原集合的拷貝進行遍歷,所以在遍歷過程中對原集合所做的修改並不能被迭代器檢測到,所以不會觸發ConcurrentModificationException,例如CopyOnWriteArrayList。
缺點:
基於拷貝內容的優點是避免了ConcurrentModificationException,但同樣地,迭代器並不能訪問到修改後的內容。即:迭代器遍歷的是開始遍歷那一刻拿到的集合拷貝,在遍歷期間原集合發生的修改迭代器是不知道的。
場景:
Java.util.concurrent包下的容器都是安全失敗的,可以在多線程下併發使用,併發修改。
快速失敗和安全失敗都是對迭代器而言的。快速失敗:當在迭代一個集合時,如果有另外一個線程在修改這個集合,就會跑出ConcurrentModificationException,java.util下都是快速失敗。安全失敗:在迭代時候會在集合二層做一個拷貝,所以在修改集合上層元素不會影響下層。在java.util.concurrent包下都是安全失敗。
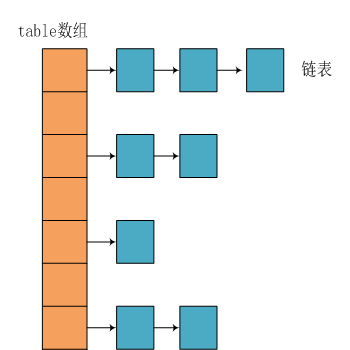
4.HashMap 的數據結構
HashMap的主幹類是一個Entry數組(jdk1.7) ,每個Entry都包含有一個鍵值隊(key-value).
我們可以看一下源碼:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry <K,V> next; // 存儲指向下一個Entry的引用,單鏈表結構 int hash; // 對key的hashcode值進行hash運算後得到的值,存儲在Entry,避免重複計算 /** * Creates new entry. */ Entry( int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; }
所以,HashMap的整體結果如下
簡單來說,HashMap由數組+鏈表組成的,數組是HashMap的主體,鏈表則是主要為了解決哈希衝突而存在的,如果定位到的數組位置不含鏈表(當前entry的next指向null ),那麼對於查找,添加等操作很快,僅需一次尋址即可;如果定位到的數組包含鏈表,對於添加操作,其時間複雜度為O(n),首先遍歷鏈表,存在即覆蓋,否則新增;對於查找操作來講,仍需遍歷鏈表,然後通過key對象的equals方法逐一比對查找。所以,性能考慮,HashMap中的鏈表出現越少,性能才會越好。
5.HashMap 的工作原理
HashMap基於hashing原理,我們通過put()和get()方法存儲和獲取對象,當我們將鍵值對傳遞給put()方法時,它調用鍵對象的hashCode()方法來計算hashcode,讓後找到bucket位置來存儲值對象。當獲取對象時,通過鍵對象的equals()方法找到正確的鍵值對,然後返回對象。
我們看一下put()源碼:
public V put(K key, V value) { // 當key為null,調用putForNullKey方法,保存null與table第一個位置中,這是HashMap允許為null的原因 if (key == null ) return putForNullKey( value); // 計算key的hash值 int hash = hash(key.hashCode()); // 計算key hash值在table數組中的位置 int i = indexFor(hash, table.length); // 從i出開始迭代e,找到key保存的位置 for (Entry<K, V> e = table[i]; e != null ; e = e.next) { Object k; // 判斷該條鏈上是否有hash值相同的(key相同) // 若存在相同,則直接覆蓋value,返回舊value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; // 舊值=新值 e.value = value; e.recordAccess( this ); return oldValue; // 返回舊值 } } // 修改次數增加1 modCount++ ; // 將key、value添加至i位置處 addEntry(hash, key, value, i); return null ; }
通過源碼我們可以清晰看到HashMap保存數據的過程為:首先判斷key是否為null,若為null,則直接調用putForNullKey方法。若不為空則先計算key的hash值,然後根據hash值搜索在table數組中的索引位置,如果table數組在該位置處有元素,則通過比較是否存在相同的key,若存在則覆蓋原來key的value,否則將該元素保存在鏈頭(最先保存的元素放在鏈尾)。若table在該處沒有元素,則直接保存。
get()源碼:
public V get(Object key) { // 若為null,調用getForNullKey方法返回相對應的value if (key == null ) return getForNullKey(); // 根據該key的hashCode值計算它的hash碼 int hash = hash(key.hashCode()); // 取出table數組中指定索引處的值 for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null ; e = e .next) { Object k; // 若搜索的key與查找的key相同,則返回相對應的value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e .value; } return null ; }
在這裡能夠根據key快速的取到value除了和HashMap的數據結構密不可分外,還和Entry有莫大的關係,在前面就提到過,HashMap在存儲過程中並沒有將key,value分開來存儲,而是當做一個整體key-value來處理的,這個整體就是Entry對象。同時value也只相當於key的附屬而已。在存儲的過程中,系統根據key的hashcode來決定Entry在table數組中的存儲位置,在取的過程中同樣根據key的hashcode取出相對應的Entry對象。
6.Hashmap 什麼時候進行擴容呢?
這裏我們再來複習put的流程:當我們想一個HashMap中添加一對key-value時,系統首先會計算key的hash值,然後根據hash值確認在table中存儲的位置。若該位置沒有元素,則直接插入。否則迭代該處元素鏈表並依此比較其key的hash值。如果兩個hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),則用新的Entry的value覆蓋原來節點的value。如果兩個hash值相等但key值不等,則將該節點插入該鏈表的鏈頭。具體的實現過程見addEntry方法,如下:
void addEntry( int hash, K key, V value, int bucketIndex) { // 獲取bucketIndex處的Entry Entry<K, V> e = table[bucketIndex]; // 將新創建的Entry放入bucketIndex索引處,並讓新的Entry指向原來的Entry table[bucketIndex] = new Entry<K, V> (hash, key, value, e); // 若HashMap中元素的個數超過極限了,則容量擴大兩倍 if ( size++ >= threshold) resize( 2 * table.length); }
這個方法中有兩點需要注意:
一是鏈的產生。這是一個非常優雅的設計。系統總是將新的Entry對象添加到bucketIndex處。如果bucketIndex處已經有了對象,那麼新添加的Entry對象將指向原有的Entry對象,形成一條Entry鏈,但是若bucketIndex處沒有Entry對象,也就是e==null,那麼新添加的Entry對象指向null ,也就不會產生Entry鏈了。
二、擴容問題。
隨著HashMap中元素的數量越來越多,發生碰撞的概率就越來越大,所產生的鏈表長度就會越來越長,這樣勢必會影響HashMap的速度,為了保證HashMap的效率,系統必須要在某個臨界點進行擴容處理。該臨界點在當HashMap中元素的數量等於table數組長度*加載因子。但是擴容是一個非常耗時的過程,因為它需要重新計算這些數據在新table數組中的位置並進行複製處理。所以如果我們已經預知HashMap中元素的個數,那麼預設元素的個數能夠有效的提高HashMap的性能。
7.HashSet怎樣保證元素不重複
都知道HashSet中不能存放重複的元素,有時候可以用來做去重操作。但是其內部是怎麼保證元素不重複的呢?
打開HashSet源碼,發現其內部維護一個HashMap:
public class HashSet<E> extends AbstractSet <E> implements Set <E> , Cloneable, java.io.Serializable { static final long serialVersionUID = - 5024744406713321676L ; private transient HashMap<E,Object> map; private static final Object PRESENT = new Object(); public HashSet() { map = new HashMap<> (); }
...
}
HashSet的構造方法其實就是在內部實例化了一個HashMap對象,其中還會看到一個static final的PRESENT變量;
想知道為什麼HashSet不能存放重複對象,那麼第一步看看它的add方法進行的判重,代碼如下
public boolean add(E e) { return map.put(e, PRESENT)== null ; }
其實看add()方法,這時候答案已經出來了:HashMap的key是不能重複的,而這裏HashSet的元素又是作為了map的key,當然也不能重複了。
順便看一下HashMap裏面又是怎麼保證key不重複的,代碼如下:
public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null ) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e ! = null ; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess( this ); return oldValue; } } modCount ++ ; addEntry(hash, key, value, i); return null ; }
其中最關鍵的一句:
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
調用了對象的hashCode和equals方法進行判斷,所以又得到一個結論:若要將對象存放到HashSet中並保證對像不重複,應根據實際情況將對象的hashCode方法和equals方法進行重寫
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?