環境資訊中心綜合外電;范震華 編譯;賴慧玲 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
據悉,去年11月,停產一年的美國電動車製造商菲斯科(Fisker)申請破產保護。香港商人李澤楷組成的財團以2500萬美元購入Fisker欠美國政府的未償還貸款,並計畫購入該電動汽車廠商的餘下資產。
按照原計劃,法院將於1月3日決定Fisker是否出售給李澤楷的關聯公司。不過,在交易得到美國法院首肯前夕,傳中國大陸萬向集團報價收購Fisker。
據外媒報導,Fisker 12月31日提交給法院的檔顯示,Fisker債權人已經要求法院廢止Fisker同意將資產售予李澤楷的交易,並開展公開競拍,而萬向集團旗下萬向美國公司將參與競購。萬向集團已經同意初步開出2472.5萬美元的報價,並承擔Fisker部分債務。
Fisker的產品為卡瑪插電式混合動力跑車,在美國市場售價高達10萬美元,但銷量一直不理想。據提交的檔顯示,萬向計畫最早在4月使Fisker恢復生產,並最終把製造業務從芬蘭遷回美國密西根州。
去年1月,萬向集團曾以2.566億美元的價格收購了美國最大的新能源電池製造商A123系統公司。而菲斯科此前是A123系統公司的最大客戶。
Fisker和A123兩家公司均獲得了美國能源部的綠色能源貸款,美國政府此前曾試圖阻撓把A123出售股權給萬向,因為美國監管方擔心敏感技術可能競爭對手手中。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準
據國外媒體報導,美國電動汽車生產商特斯拉(Tesla)正準備在中國建立一批免費充電站,從而支援公司汽車的長距離行駛,例如從北京開到上海。特斯拉方面已開始同物業主及電力服務提供商進行交流,但尚未透露這些充電站何時可以投入使用。
特斯拉在美國有一套類似的充電站網絡,靠電池行駛的特斯拉「Model S」型轎車能夠通過免費充電站的支援,橫穿美國。該公司目前還在為歐洲建設類似的網絡。
中國政府一直在推廣電動汽車銷售,作為解決當地汽車尾氣污染的措施之一。但這一舉措並不怎么成功,主要是因為充電設施建設的難度太大。
特斯拉目前在中國北京有一處展廳,以及一個服務與銷售網點。該公司打算將上海作為下一個目標,並且大膽拓展業務。目前中國購車者可以訂購特斯拉「Model S」與即將發布的「Model X」,預付款為25萬元人民幣,約合4.1萬美元。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
雖然美國電動車製造商特斯拉(Tesla)日前召回了2.9萬個充電器轉接頭,使Model S安全疑慮再起,但Tesla週二公布,2013年第4季(10~12月)Model S高級房車大賣6900輛,銷量與營收年增率可望雙雙超越20%。
據特斯拉提交美國國家公路交通安全管理局(NHTSA)的文件表示,2013年出廠的Model S充電器轉接頭藏有過熱可能性,「可能造成轉接頭融化,且在最遭情況下可能起火」。去年Model S一共傳出3起事故,全因車輛行駛時遭重物撞裂底盤電池防護蓋才起火,但3起事故皆未造成人員傷亡。
特斯拉周二發表的銷售數字再度驗證,消費者對Model S的信心絲毫不減。特斯拉近來不僅獲得多方產業專家肯定Model S安全性,也在美國增設快速充電的「超級充電站」,估計不久後用戶橫跨美國就不用擔心沒電。
Model S是特斯拉的主打車型,已有超過2.5萬輛Model S在上路行駛。特斯拉預期今年年底銷售分店應會增設2倍以上,今年特斯拉電動汽車銷量可能會大幅成長。
Tesla股價在周二收盤大漲16%至161.27美元,創6周以來最大漲幅,周三盤中續漲6%,每股171.37美元。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
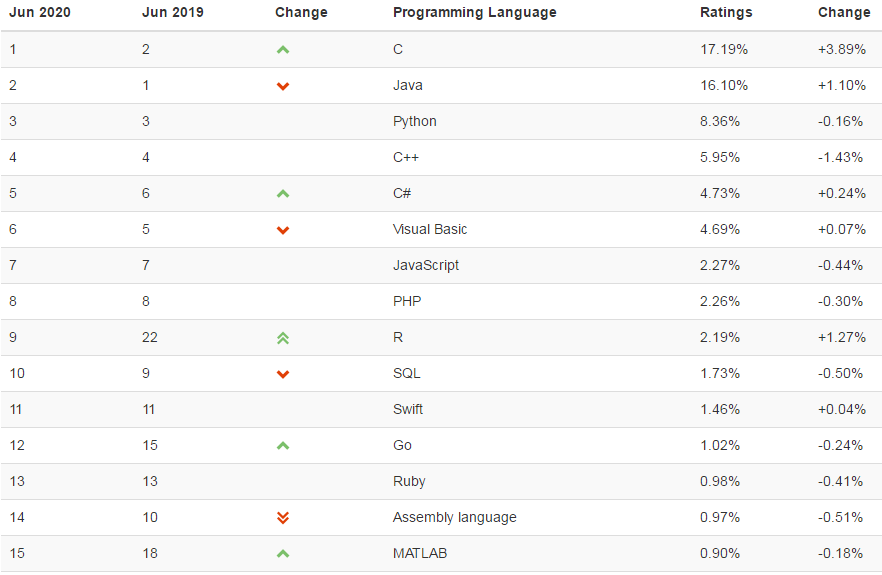
本來想參照:https://mp.weixin.qq.com/s/e7Wd7aEatcLFGgJUDkg-EQ搞一個往年編程語言動態圖的,奈何找不到數據,有數據來源的歡迎在評論區留言。
這裏找到了一個,是2020年6月的編程語言排行,供大家看一下:https://www.tiobe.com/tiobe-index/
我們要實現的效果是:
大學排名來源:http://www.zuihaodaxue.com/ARWU2003.html
部分截圖:
在http://www.zuihaodaxue.com/ARWU2003.html中的年份可以選擇,我們解析的頁面就有了:
"http://www.zuihaodaxue.com/ARWU%s.html" % str(year)
初步獲取頁面的html信息的代碼:
def get_one_page(year): try: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } url = "http://www.zuihaodaxue.com/ARWU%s.html" % str(year) response=requests.get(url,headers=headers) if response.status_code == 200: return response.content except RequestException: print('爬取失敗')
我們在頁面上進行檢查:
數據是存儲在表格中的,這樣我們就可以利用pandas獲取html中的數據,基本語法:
tb = pd.read_html(url)[num]
其中的num是標識網頁中的第幾個表格,這裏只有一個表格,所以標識為0。初步的解析代碼就有了:
def parse_on_page(html,i): tb=pd.read_html(html)[0] return tb
我們還要將爬取下來的數據存儲到csv文件中,基本代碼如下:
def save_csv(tb): start_time=time.time() tb.to_csv(r'university.csv', mode='a', encoding='utf_8_sig', header=True, index=0) endtime = time.time()-start_time print('程序運行了%.2f秒' %endtime)
最後是一個主函數,別忘了還有需要導入的包:
import requests from requests.exceptions import RequestException import pandas as pd import time def main(year): for i in range(2003,year): html=get_one_page(i) tb=parse_on_page(html,i) #print(tb) save_csv(tb) if __name__ == "__main__": main(2004)
運行之後,我們在同級目錄下就可以看到university.csv,部分內容如下:
存在幾個問題:
(1)缺少年份
(2)最後一列沒有用
(3)國家由於是圖片表示,沒有爬取下來
(4)排名100以後的是一個區間
我們接下來一一解決:
(1)刪掉沒用的列
def parse_on_page(html,i): tb=pd.read_html(html)[0] # 重命名表格列,不需要的列用數字錶示 tb.columns = ['world rank','university', 2, 'score',4] tb.drop([2,4],axis=1,inplace=True) return tb
新的結果:
(2) 對100以後的進行唯一化,增加一列index作為排名標識
tb['index_rank'] = tb.index tb['index_rank'] = tb['index_rank'].astype(int) + 1
(3)新增加年份
tb['year'] = i
(4)新增加國家
首先我們進行檢查:
發現國家在td->a>img下的圖像路徑中有名字:UnitedStates。 我們可以取出src屬性,並用正則匹配名字即可。
def get_country(html): soup = BeautifulSoup(html,'lxml') countries = soup.select('td > a > img') lst = [] for i in countries: src = i['src'] pattern = re.compile('flag.*\/(.*?).png') country = re.findall(pattern,src)[0] lst.append(country) return lst
然後這麼使用:
# read_html沒有爬取country,需定義函數單獨爬取 tb['country'] = get_country(html)
最終解析的整體函數如下:
def parse_on_page(html,i): tb=pd.read_html(html)[0] # 重命名表格列,不需要的列用數字錶示 tb.columns = ['world rank','university', 2, 'score',4] tb.drop([2,4],axis=1,inplace=True) tb['index_rank'] = tb.index tb['index_rank'] = tb['index_rank'].astype(int) + 1 tb['year'] = i # read_html沒有爬取country,需定義函數單獨爬取 tb['country'] = get_country(html) return tb
運行之後:
最後我們要提取屬於中國部分的相關信息:
首先將年份改一下,獲取到2019年為止的信息:
if __name__ == "__main__": main(2019)
然後我們提取到中國高校的信息,直接看代碼理解:
def analysis(): df = pd.read_csv('university.csv') # 包含港澳台 # df = df.query("(country == 'China')|(country == 'China-hk')|(country == 'China-tw')|(country == 'China-HongKong')|(country == 'China-Taiwan')|(country == 'Taiwan,China')|(country == 'HongKong,China')")[['university','year','index_rank']] # 只包括內地 df = df.query("(country == 'China')") df['index_rank_score'] = df['index_rank'] # 將index_rank列轉為整形 df['index_rank'] = df['index_rank'].astype(int) # 美國 # df = df.query("(country == 'UnitedStates')|(country == 'USA')") #求topn名 def topn(df): top = df.sort_values(['year','index_rank'],ascending = True) return top[:20].reset_index() df = df.groupby(by =['year']).apply(topn) # 更改列順序 df = df[['university','index_rank_score','index_rank','year']] # 重命名列 df.rename (columns = {'university':'name','index_rank_score':'type','index_rank':'value','year':'date'},inplace = True) # 輸出結果 df.to_csv('university_ranking.csv',mode ='w',encoding='utf_8_sig', header=True, index=False) # index可以設置
本來是想爬取從2003年到2019年的,運行時發現從2005年開始,頁面不一樣了,多了一列:
方便起見,我們就只從2005年開始了,還需要修改一下代碼:
# 重命名表格列,不需要的列用數字錶示 tb.columns = ['world rank','university', 2,3, 'score',5] tb.drop([2,3,5],axis=1,inplace=True)
最後是整體代碼:
import requests from requests.exceptions import RequestException import pandas as pd import time from bs4 import BeautifulSoup import re def get_one_page(year): try: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } url = "http://www.zuihaodaxue.com/ARWU%s.html" % str(year) response=requests.get(url,headers=headers) if response.status_code == 200: return response.content except RequestException: print('爬取失敗') def parse_on_page(html,i): tb=pd.read_html(html)[0] # 重命名表格列,不需要的列用數字錶示 tb.columns = ['world rank','university', 2,3, 'score',5] tb.drop([2,3,5],axis=1,inplace=True) tb['index_rank'] = tb.index tb['index_rank'] = tb['index_rank'].astype(int) + 1 tb['year'] = i # read_html沒有爬取country,需定義函數單獨爬取 tb['country'] = get_country(html) return tb def save_csv(tb): start_time=time.time() tb.to_csv(r'university.csv', mode='a', encoding='utf_8_sig', header=True, index=0) endtime = time.time()-start_time print('程序運行了%.2f秒' %endtime) # 提取國家名稱 def get_country(html): soup = BeautifulSoup(html,'lxml') countries = soup.select('td > a > img') lst = [] for i in countries: src = i['src'] pattern = re.compile('flag.*\/(.*?).png') country = re.findall(pattern,src)[0] lst.append(country) return lst def analysis(): df = pd.read_csv('university.csv') # 包含港澳台 # df = df.query("(country == 'China')|(country == 'China-hk')|(country == 'China-tw')|(country == 'China-HongKong')|(country == 'China-Taiwan')|(country == 'Taiwan,China')|(country == 'HongKong,China')")[['university','year','index_rank']] # 只包括內地 df = df.query("(country == 'China')") df['index_rank_score'] = df['index_rank'] # 將index_rank列轉為整形 df['index_rank'] = df['index_rank'].astype(int) # 美國 # df = df.query("(country == 'UnitedStates')|(country == 'USA')") #求topn名 def topn(df): top = df.sort_values(['year','index_rank'],ascending = True) return top[:20].reset_index() df = df.groupby(by =['year']).apply(topn) # 更改列順序 df = df[['university','index_rank_score','index_rank','year']] # 重命名列 df.rename (columns = {'university':'name','index_rank_score':'type','index_rank':'value','year':'date'},inplace = True) # 輸出結果 df.to_csv('university_ranking.csv',mode ='w',encoding='utf_8_sig', header=True, index=False) # index可以設置 def main(year): for i in range(2005,year): html=get_one_page(i) tb=parse_on_page(html,i) save_csv(tb) print(i,'年排名提取完成完成') analysis() if __name__ == "__main__": main(2019)
運行之後會有一個university_ranking.csv,部分內容如下:
接下來就是可視化過程了。
1、 首先,到作者的github主頁:
https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js
2、克隆倉庫文件,使用git
# 克隆項目倉庫 git clone https://github.com/Jannchie/Historical-ranking-data-visualization-based-on-d3.js # 切換到項目根目錄 cd Historical-ranking-data-visualization-based-on-d3.js # 安裝依賴 npm install
這裏如果git clone超時可參考:
https://www.cnblogs.com/xiximayou/p/12305209.html
需要注意的是,這裏的npm是我之前裝node.js裝了的,沒有的自己需要裝一下。
在執行npm install時會報錯:
先執行:
npm init
之後一直回車即可:
再執行npm install
任意瀏覽器打開bargraph.html網頁,點擊選擇文件,然後選擇前面輸出的university_ranking.csv文件,看下效果:
只能製作動圖上傳了。
可以看到,有了大致的可視化效果,但還存在很多瑕疵,比如:表順序顛倒了、字體不合適、配色太花哨等。可不可以修改呢?
當然是可以的,只需要分別修改文件夾中這幾個文件的參數就可以了:
config.js 全局設置各項功能的開關,比如配色、字體、文字名稱、反轉圖表等等功能;
color.css 修改柱形圖的配色;
stylesheet.css 具體修改配色、字體、文字名稱等的css樣式;
visual.js 更進一步的修改,比如圖表的透明度等。
知道在哪裡修改了以後,那麼,如何修改呢?很簡單,只需要簡單的幾步就可以實現:
打開網頁,右鍵-檢查,箭頭指向想要修改的元素,然後在右側的css樣式表裡,雙擊各項參數修改參數,修改完元素就會發生變化,可以不斷微調,直至滿意為止。
把參數複製到四個文件中對應的文件里並保存。
Git Bash運行npm run build,之後刷新網頁就可以看到優化后的效果。(我發現這一步其實不需要,而且會報錯,我直接修改config.js之後運行也成功了)
這裏我主要修改的是config.js的以下項:
// 倒序,使得最短的條位於最上方 reverse: true, // 附加信息內容。 // left label itemLabel: "本年度第一大學", // right label typeLabel: "世界排名", //為了避免名稱重疊 item_x: 500, // 時間標籤坐標。建議x:1000 y:-50開始嘗試,默認位置為x:null,y:null dateLabel_x: 1000, dateLabel_y: -50,
最終效果:
至此,就全部完成了。
看起來簡單,還是得要自己動手才行。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準
中國汽車廠商比亞迪(BYD)今(11)日宣布,首支英國倫敦史上全電動計程車隊正式上路,在2018年前批量供應零排放出租車的競爭中,搶在了日產(Nissan)等國際競爭對手之前。不到2個月前,比亞迪還交付了倫敦史上首批全電動公共汽車。
據《金融時報》報導,倫敦市長鮑里斯約翰遜(Boris Johnson)設定了全市計程車必須在2018年前實現零排放的目標,引發汽車廠商爭相開發新車。
比亞迪趕在該期限之前率先打入了倫敦交通市場。比亞迪將推出20輛電動汽車組成的車隊,由出租車公司Thriev營運。
另一方面,日本電動車廠商日產(Nissan)與英國經典黑出租車製造商倫敦出租車公司(London Taxi Company) ,也準備趕在2018年期限之前開發出全電動車型。
著名的股神華倫•巴菲特(Warren Buffett)持有比亞迪9.9%股份。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準

目前限制全球電動汽車發展的主要瓶頸,在於電池成本和續航力問題。日前有日本廠商推出一款名為FOMM Concept One的超小型電動車,雖說續航力僅有100km,但是卻有另外一點吸引人的地方,那就是如果碰到水災還能變成小艇,且價格非常親民。據說不到日幣100萬圓(約合新台幣29.7萬元)。
這款小型電動汽車,雖然不是專門的水陸兩用車,但遇到洪水等緊急情況,可以在水面漂浮24小時,也能在水面上以時速3.8公里左右的速度移動。車內裝有可拆卸的電池,充滿電後最多可在陸地上行駛100公里。這款4人座汽車全長約2.5公尺,重量僅460公斤,計劃從明年10月開始先在水災較多的泰國銷售。
FOMM公司由日本大同工業(DAIDO Kogyo)、日本特殊陶業(NGK)所共同建立,FOMM Concept One為幾家公司合作下的第一個產物。根據FOMM的規劃, Concept One的開發成本不低,但2014年4-6月將有一比龐大資金注入,倘若一切都順利預計2015年9月將可在泰國進行量產,至於第一年銷售量目標是5000輛。

本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
據英國媒體報導,英國動力系統設計公司宣佈,該公司正在開發一套名為MSYS的電動汽車動力系統,可以將電動汽車行駛里程增加10%至15%。MSYS系統預計將於2016年投產。
在英國即將舉辦的未來動力系統會議上,英國動力系統設計公司將發佈高效電動汽車動力系統報告。該動力系統提供了一種新的汽車換擋路徑,而且不會引起扭矩中斷。
該公司技術總監阿萊克斯•泰利•博達爾表示,該技術可提供55千瓦的持續電力供應,超過2000牛/米的扭矩,其電力動力系統效率可達91%。
阿萊克斯還透露,MSYS系統避免了其他傳動方法的弊端。雙離合器變速箱(DCT)在離合器開啟或關閉狀態時,都會持續消耗能量。而在換擋時,自動變速器(AMT)會受損於扭矩中斷。此外,基於行星齒輪變速器的自動裝置,則增加了複雜性和成本,並會拖慢速度。
MSYS系統將提供三種速度傳動裝置,使其換擋和快速換擋都能運用重疊換擋技術。隨著技術的完善,多重比例的選擇對電動汽車的變速會非常有益。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
今日得到
計算機科學領域的任何問題都可以通過增加一個間接的中間層來解決
併發:Do not communicate by sharing memory; instead, share memory by communicate. (不要以共享內存的方式來通信,相反,要通過通信來共享內存)
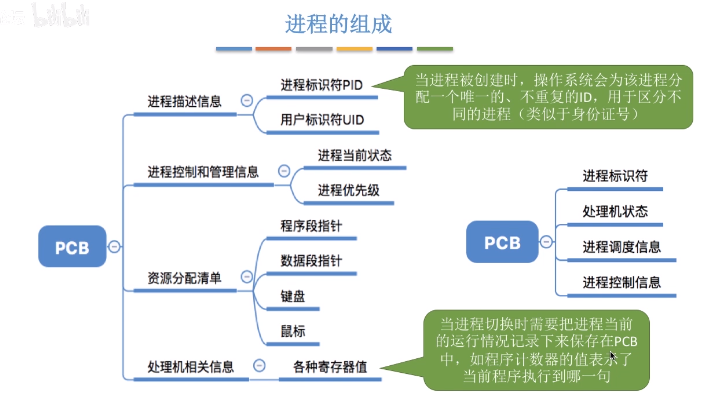
進程是系統進行資源分配和調度的一個獨立單位,程序段、數據段、PCB三部分組成了進程實體(進程映像),PCB是進程存在的唯一標準
創建態: 操作系統為進程分配資源,初始化PCB
就緒態:運行資源等條件都滿足,存儲在就緒隊列中,等待CPU調度
運行態:CPU正在執行進程
阻塞態:等待某些條件滿足,等待消息回復,等待同步鎖,sleep等,阻塞隊列
終止態 :回收進程擁有的資源,撤銷PCB
進程在操作系統內核程序臨界區中不能進行調度與切換
臨界資源:一個時間段內只允許一個進程使用資源,各進程需要互斥地訪問臨界資源
臨界區:訪問臨界資源的代碼
內核程序臨界區:訪問某種內核數據結構,如進程的就緒隊列(存儲各進程的PCB)
進程調度的方式:
進程的切換與過程:進程的調度、切換是有代價的
進程調度算法的相關參數:
調度算法:
算法思想,用於解決什麼問題?
算法規則,用於作業(PCB作業)調度還是進程調度?
搶佔式還是非搶佔式的?
優缺點?是否會導致飢餓?
以下調度算法是適用於當前交互式操作系統
算法思想:綜合FCFS、SJF(SPF)、時間片輪轉、優先級調度
算法規則:
用於作業/進程調度:用於進程調度
是否可搶佔? 搶佔式算法。在k級隊列的進程運行過程中,若更上級別的隊列(1-k-1級)中進入一個新進程,則由於新進程處於優先級高的隊列中,因此新進程會搶佔處理機,原理運行的進程放回k級隊列隊尾。
優缺點:對各類型進程相對公平(FCFS的有點);每個新到達的進程都可以很快就得到相應(RR優點);短進程只用較少的時間就可完成(SPF)的有點;不必實現估計進程的運行時間;可靈活地調整對各類進程的偏好程度,比如CPU密集型進程、I/O密集型進程(拓展:可以將因I/O而阻塞的進程重新放回原隊列,這樣I/O型進程就可以保持較高優先級)
是否會導致飢餓: 會
引入線程之後,進程只作為除CPU之外的系統資源的分配單元(如:打印機,內存地址空間等都是分配給進程的)
線程的是實現方式:
進程和線程的關係:一條線程指的是進程中一個單一順序的控制流,一個進程中可以併發多個線程,每條線程并行執行不同的任務。CPU的最小調度單元是線程,所以單進程多線程是可以利用多核CPU的。
多個用戶態的線程對應着一個內核線程,程序線程的創建、終止、切換或者同步等線程工作必須自身來完成。python就是這種。雖然可以實現異步,但是不能有效利用多核(GIL)
這種模型直接調用操作系統的內核線程,所有線程的創建、終止、切換、同步等操作,都由內核來完成。C++就是這種
這種線程模型會先創建多個內核級線程,然後用自身的用戶級線程去對應創建的多個內核級線程,自身的用戶級線程需要本身程序去調度,內核級的線程交給操作系統內核去調度。GO語言就是這種。
python中的多線程因為GIL的存在,並不能利用多核CPU優勢,但是在阻塞的系統調用中,如sock.connect(), sock.recv()等耗時的I/O操作,當前的線程會釋放GIL,讓出處理器。但是單個線程內,阻塞調用上還是阻塞的。除了GIL之外,所有的多線程還有通病,他們都是被OS調用的,調度策略是搶佔式的,以保證同等有限級的線程都有機執行,帶來的問題就是:並不知道下一刻執行那個線程,也不知道正在執行什麼代碼,會存在競態條件
協程通過在線程中實現調度,避免了陷入內核級別的上下文切換造成的性能損失,進而突破了線程在IO上的性能瓶頸。
python的協程源於yield指令
協程式對線程的調度,yield類似惰性求職方式可以視為一種流程控制工具,實現協作式多任務,python3.5引入了async/await表達式,使得協程證實在語言層面得到支持和優化,大大簡化之前的yield寫法。線程正式在語言層面得到支持和優化。線程是內核進行搶佔式調度的,這樣就確保每個線程都有執行的機會。而coroutine運行在同一個線程中,有語言層面運行時中的EventLoop(事件循環)來進行調度。在python中協程的調度是非搶佔式的,也就是說一個協程必須主動讓出執行機會,其他協程才有機會運行。讓出執行的關鍵字 await, 如果一個協程阻塞了,持續不讓出CPU處理機,那麼整個線程就卡住了,沒有任何併發。
PS: 作為服務端,event loop最核心的就是I/O多路復用技術,所有來自客戶端的請求都由I/O多路復用函數來處理;作為客戶端,event loop的核心在於Future對象延遲執行,並使用send函數激發協程,掛起,等待服務端處理完成返回后再調用Callback函數繼續執行。[python 協程與go協程的區別]
Go 天生在語言層面支持,和python類似都是用關鍵字,而GO語言使用了go關鍵字,go協程之間的通信,採用了channel關鍵字。
go實現了兩種併發形式:
package main
import ("fmt")
func main() {
jobs := make(chan int)
done := make(chan bool) // end flag
go func() {
for {
j, ok := <- jobs
fmt.Println("---->:", j, ok)
if ok {
fmt.Println("received job")
} else {
fmt.Println("end received jobs")
done <- true
return
}
}
}()
go func() {
for j:= 1; j <= 3; j++ {
jobs <-j
fmt.Println("sent job", j)
}
close(jobs)
fmt.Println("close(jobs)")
}()
fmt.Println("sent all jobs")
<-done // 阻塞 讓main等待協程完成
}
Go的CSP併發模型是通過goroutine 和 channel來實現的。
協程本質上來說是一種用戶態的線程,不需要系統來執行搶佔式調度,而是在語言測個面實現線程的調度。
併發:Do not communicate by sharing memory; instead, share memory by communicate.
Actor模型和CSP模型的區別:
好文推薦:Go/Python/Erlang編程語言對比分析及示例
一個M會對應一個內核線程,一個M也會連接一個上下文P,一個上下文P相當於一個“處理器”,一個上下文連接一個或者多個Goroutine。P(Processor)的數量是在啟動時被設置為環境變量GOMAXPROCS的值,或者通過運行時調用函數runtime.GOMAXPROCS()進行設置
erlang和golang都是採用CSP模型,python中協程是eventloop模型。但是erlang是基於進程的消息通信,go是基於goroutine和channel通信。
python和golang都引入了消息調度系統模型,來避免鎖的影響和進程線程的開銷問題。
計算機科學領域的任何問題都可以通過增加一個間接的中間層來解決 — G-P-M模型正是此理論踐行者,此理論也用到了python的asyncio對地獄回調的處理上(使用Task+Future避免回調嵌套),是不是巧合?
其實異步≈可中斷的函數+事件循環+回調,go和python都把嵌套結構轉換成列表結構有點像算法中的遞歸轉迭代.
調度器在計算機中是分配工作時所需要的資源,Linux的調度是CPU找到可運行的線程,Go的調度是為M線程找到P(內存,執行票據)和可運行的G(協程)
Go協程是輕量級的,棧初始2KB(OS操作系統的線程一般都是固有的棧內存2M), 調度不涉及系統調用,用戶函數調用前會檢查棧空間是否足夠,不夠的話,會進行站擴容,棧大小限制可以達到1GB。
Go的網絡操作是封裝了epoll, 為NonBlocking模式,切換協程不阻塞線程。
Go語言相比起其他語言的優勢在於OS線程是由OS內核來調度的,goroutine則是由Go運行時(runtime)自己的調度器調度的,這個調度器使用一個稱為m:n調度的技術(復用/調度m個goroutine到n個OS線程)。 其一大特點是goroutine的調度是在用戶態下完成的, 不涉及內核態與用戶態之間的頻繁切換,包括內存的分配與釋放,都是在用戶態維護着一塊大的內存池, 不直接調用系統的malloc函數(除非內存池需要改變),成本比調度OS線程低很多。 另一方面充分利用了多核的硬件資源,近似的把若干goroutine均分在物理線程上, 再加上本身goroutine的超輕量,以上種種保證了go調度方面的性能。點我了解更多
legendtkl阿里雲技術專家
Golang源碼探索(二) 協程的實現原理
王道操作系統
操作系統中調度算法(FCFS、RR、SPN、SRT、HRRN)
Python協程與Go協程的區別二
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準

本人在1年半之前,不熟悉Python(不過有若干年Java開發基礎),由於公司要用Python,所以學習了一通。現在除了能用Python做本職工作外,還出了本Python書,《基於股票大數據分析的Python入門實戰 視頻教學版》,京東鏈接:https://item.jd.com/69241653952.html,還在某網站錄製了視頻課,後面還有其它線上線下課的機會。
本人的感受是,哪怕上班用不到Python,程序員也應該學Python,因為Python能給大家帶來更多的主業副業機會,而且現在做Python的人還沒Java多。在本文里將結合本人的經驗,一方面分享下如何高效學Python,另一方面分享下用Python掙錢的經驗。
尷尬體現在哪裡?一些大廠雖然有專門做Python的高薪崗位,但一般會直接找些深度學習機器學習方向的碩士博士,而且是要名校的,而小公司一般限於成本的原因,無法直接設置單做Python的崗位,而且也就是做些技術含量較低的應用, 比如做個爬蟲或者簡單調個機器學習的庫,所以一般是讓做其它語言的人順帶做掉。
而且Python用庫和方法的形式包裝掉了一些很複雜的算法,程序員一般只需要調用方法就可以實現基本的機器學習和深度學習之類的活,而在大廠里高薪的Python崗,絕非是簡單地調用Python,而是需要深入了解算法,從而根據業務定製模型,所以一般社會上的程序員很難通過自學,達到大廠里高薪Python程序員的標準。
總之,你在工作后通過自學Python,未必能達到大廠高薪職位的標準,因為由於你數學基礎不行,未必能深入算法,而一般公司也不會單獨開設Python崗位,所以對應地,學Python之前大家應該明確靠Python的掙錢方式。
1 主業上,還得以Java等語言為主,但如果你能在簡歷和面試中證明自己很精通一般的Python爬蟲、數據分析和機器學習等方面的應用,絕對能幫你更好地找到工作,並且個人提升也會很快。
2 雖然Python底層包含的深度學習等方面的算法很難,但用Python做案例並不難,大家可以通過Python做些副業的活。
第一步,了解Python的基本語法,比如集合,讀寫文件,讀寫數據庫和異常處理等,如果大家有Java等語言的開發基礎,這塊很簡單,本人也就用了2個星期。但正是因為簡單,所以這些技能很不值錢,別人學起來也快。
第二步,了解數據分析三劍客,具體來說就是Numpy, Pandas和matplotlib,用Numpy和Pandas清洗數據,用Pandas的DataFrame存儲數據,再用matplotlib繪製柱狀圖餅圖之類的圖形。
第三步,了解爬蟲技能,這裏除了需要了解自帶的urllib庫之外,還需要了解一種框架,比如Scrapy,需要到能根據需求定製爬蟲代碼的程序。
其實數據分析和爬蟲相關的語法技能,也不複雜,本人用1個半月也就達到能幹活的程度了,相信大家應該更快。而且,學到這種程序,應該就可以去做些案例以此掙錢了,比如寫分析xx網站的案例,錄成視頻去賣了,而且也能完成公司里大多數數據獲取和數據分析的功能需求了。
第四步去了解機器學習庫,具體而言就去學習sklearn庫,這個庫里不僅包含了線性回歸嶺回歸和SVM分類等機器學習算法,還包含了波士頓房價、鳶尾花和手寫體識別等的數據集,而且由於已經包裝了相關算法,用sklearn庫學習機器學習的過程並不難,不需要過多的數學知識。學好這個庫,外帶結合爬蟲和數據分析的技能,就更在某個領域幹活掙錢了,比如本人在股票分析領域出了本書,並且也出了些視頻,後繼還可以繼續深入股票量化分析領域。
第五步,可以去了解深度學習,無非是人工神經網絡,自然語言分析,圖像識別等,這方面雖然包含的數學知識更複雜,但由於也經過包裝,所以直接用接口也不難。這方面學好以後,雖然說高不成低不就,即沒法進大廠,同時小公司也用不到,但用這些知識準備些案例,出書講課錄視頻,甚至做企業培訓,還是能帶來一定的收益的。
在學上述知識的時候,千萬不能只學語法,因為沒用,一定得結合實例,同時把這些知識變現的時候,也不能單講語法,也是要準備若干案例,比如像我這樣的股票分析,或者是scrapy+數據分析+深度學習的xx網站數據分析案例,這些技能雖然很高大上,但其實做到調用接口實踐案例的程度就能掙錢,如果再有機緣以此進入大廠,那就真的前途無量了。
之前講的是如何學,學什麼,這裏就開始講如何掙錢。當然最簡單的就是建個公眾號,在上面發文,吸引粉絲,這個門檻相對低。
但注意如果僅僅發表入門級的文章,比如numpy庫怎麼用,怎麼用matplotlib庫繪製基本圖形,這絕對不夠,因為此類文章太多,哪些文章能吸引人?
1 綜合應用類,比如scrapy+數據分析三劍客。
2 實戰案例類,比如用scrapy爬個網站數據,然後分析。
3 專業領域類,比如量化分析股票,分析房價等。
4 深度學習機器學習這些領域現在還很火,這些領域如果把某個算法通俗易懂地講透也行,或者這些方面給寫案例,比如用自然語言分析技術分析某網站的評論等。
如果能定期發表此類文章,公眾號一定能聚集到不少粉絲,同樣也可以做視頻的up主。
如何讓別人認為你是python某個領域的大牛?要麼有大廠架構師職位加持,這不是每個人都能達到,或者是著名博主公眾號主,但似乎這也需要經歷來積澱,不過如果你在python數據分析和機器學習等方面出本書,那說服力自然就上來了。
出書可以偏重案例,比如講爬蟲數據分析的書,在合法的前提下給出爬取分析若干知名網頁的案例,如果講機器學習的書,甚至可以結合sklearn庫自帶的數據集,講清楚常用算法的案例應用,如果有時間有機會,我甚至打算再出版本基於python股票量化的書。
相對而言,寫一本講述包括語法、結合小案例講(機器學習等)庫的用法和結合綜合案例講機器學習算法和數據分析綜合應用的書,並不難。對於一個有5年開發經驗的程序員而言,從零基礎積累個半年,就完全可以達到出書的地步,如果資歷稍微弱些,只有2,3年開發經歷,估計學個1年也應該可以達到出書的地步。
還是這句話,出書掙的錢不多,但絕對能證明你在python某個領域的能力,小到聯繫副業,大到以此找工作,一定能幫到你。具體操作的話,可以直接在清華出版社,机械工業出版社,人民郵電出版社和电子工業出版社的官網找聯繫方式,然後直接和編輯溝通,至於一些有中介性質的圖書公司,大家自己看着辦。
包括到各大視頻網站去錄製數據分析、爬蟲、機器學習和深度學習等方面的系列課,也可以找你所在城市的線下培訓班去講課,如果你有相關大公司背景,有自己的書,或者業內知名,你就可以聯繫些做企業培訓的公司。這樣做下個半年後,月入1萬應該不是問題。
在做各種副業的時候,一般來說也是要偏重案例,比如你有若干個深度學習的案例外帶相關算法的說明,再加上些好的文案,應該很能吸引人。當然也可以直接找項目做,目前python方面比較熱門的項目可能還是用爬蟲,但這塊做的時候就要非常慎重了,不能做違法的事情,而當前用到深度學習機器學習技術的項目倒不多,可能因為這些應用更集中在大公司吧。
說實話,python方面的活,哪怕門檻最低的做公眾號,要做好也不簡單,更何況出書了。至於,自己聯繫平台出視頻,或者做線下培訓或者做項目,就不僅得靠技術,更得靠人脈了,經營這類活需要的時間更多。
不過掙錢拿有容易的,況且,如果下班后總是看手機或者混日子,可能一天天就很快過去了,與其下班做些沒收益的消遣,還不如學些python幹些活,這樣多少好歹也有收益,或者指不定無心插柳柳成蔭,你經營python一段時間后,或者真就以此進了大廠,或者也通過各種途徑成為業內知名人事,拓展了不少副業渠道,也算是不負好時光吧。
感謝大家看完此文,如果感覺有一定道理,請點贊此文。如果要轉載,也請全文轉載,別刪節本人辛苦寫成的文章。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!