前置知識
圖的遍歷(dfs)
強連通&強連通分量
對於有向圖G中的任意兩個頂點u和v存在u->v的一條路徑,同時也存在v->u的路徑,我們則稱這兩個頂點強連通。以此類推,強連通分量就是某一個分量內各個頂點之間互相連通。
簡單來說,就是有向圖內的一個分量,其中的任意兩個點之家可以互相到達。
求有向圖內部強連通分量的方法大概有2種:tarjan算法,korasaju算法。這裏我們只對tarjan算法進行討論。
tarjan算法
tarjan算法是tarjan神仙提出的基於dfs時間戳和堆棧的算法,這裏我們可以先來看一下什麼是dfs時間戳
dfs時間戳
dfs時間戳就是dfs的先後順序,詳細來講,比如我們dfs最先訪問到的節點是A,於是A的時間戳就是1,第二個訪問到的節點是E,那麼E的時間戳就是2,我們用\(dfn[u]\)來表示u節點的時間戳,應該算是比較簡單的
算法步驟
首先,除了dfn以外我們還需要一個low數組,這個數組記錄了某個點通過圖上的邊能回溯到的dfn值最小的節點。這句話相信在大多數博客裏面都有提到,這裏我們來看一個簡單的例子:
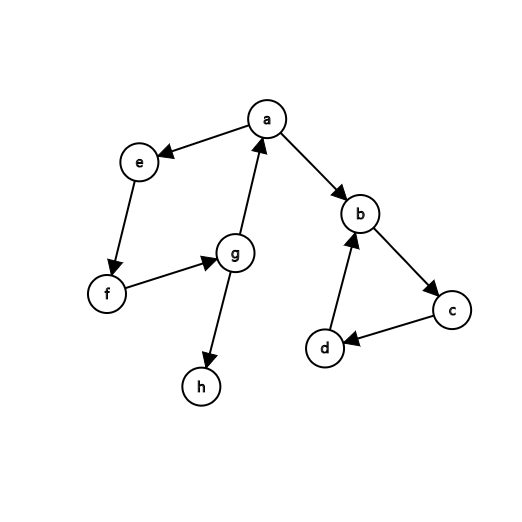
首先,我們有一個圖G:
假設我們從a點出發開始dfs,我們可以畫出一個dfs樹:
為什麼我們畫出來的dfs樹和原來的圖不一樣呢?因為我們在dfs的過程中實際上是會忽略某一些連接到已訪問節點的邊的,這些邊我們暫且稱之為回邊。對於點u來說,\(low[u]\)保存的就是點u通過某一條(或者是幾條)回邊能到達的dfn值最小的節點(也就是被最先訪問的節點)。假設這個dfn值最小的節點是u’,我們可以知道,因為u和u’都是在一棵dfs樹上的,並且u’可以到達u,同時u可以通過一條或多條回邊到達u’,也就是說u’->u路徑上的任意節點都可以通過這一條回邊來互相到達,也就是說他們會形成一個強連通分量。
更加詳細的例子
我們有一個新圖G:
假設我們從A點出發開始dfs,一路跑到D點,那麼我們為這個圖上的每一個點加上dfn數組和low數組的值(dfn,low),整個圖就會長成這個樣子:
此時我們會遇到一條D->A的回邊,也就是說點D能訪問到的dfn值最小的節點從點D本身變化到了A點,所以點D的low值就會發生相應的變化,\(low[D]=min(low[D],dfn[A])\)。
緊接着,dfs發生回溯,我們沿着之前的路徑逐步更新路徑上節點的low值,於是就有\(low[C]=min(low[C],low[D])\),直到更新到某一個dfn值和low值相同的節點。因為這個節點能訪問到的最小dfn的節點就是其本身,也就是說這個節點是整個scc最先被訪問到的節點。
全部搞完大概會變成這個樣子:
我們用一個輔助棧來保存dfs的路徑,這樣就可以在找到一個強連通分量裏面最早被訪問到的節點的時候可以輸出路徑。同時因為dfs訪問是一條路走到黑的,所以可以保證棧內在節點u(low[u]==dfn[u])之前的的節點都是屬於同一個scc的。
還是上面這幅圖,我們順便把E點給更新了:
跑完E點之後就會發現,E點本身的low就是和dfn相等的,所以此時棧內也只有E這一個節點。
於是上面這個圖的scc有以下幾個:
[E]
[A,B,C,D]
代碼實現
首先我們要發現,在dfs的初期我們每一個節點的low和dfn都是相同的,也就是說有dfn[u]=low[u]=++cnt(cnt為計數變量),並且在回溯的過程中要用后訪問節點的low值來更新先訪問節點的low值,也就是說有\(low[u]=min(low[u],low[v])\),當訪問到某一個在棧中的節點的時候,我們要用這個節點的dfn值來更新其他節點,所以有\(low[u]=min(low[u],dfn[v])\)。
那麼我們一個簡單的代碼就可以寫出來了:
void tarjan(int u){
dfn[u]=low[u]=++cnt;
s.push(u);
ins[u]=1;
for(int i=0;i<gpe[u].size();i++){
int v=gpe[u][i].to;
if(!dfn[v]){//如果節點未訪問,則訪問之
tarjan(v);
low[u]=min(low[u],low[v]);
}else if(ins[v]){//ins是為棧中節點做的一個標記
low[u]=min(low[u],dfn[v]);
}
}
}
當更新完畢之後,我們需要找出一個完整的scc,因為我們提前已經用輔助棧來記錄節點了,剩下的工作就只剩下從棧中不停地pop就完事了
if(low[u]==dfn[u]){
ins[u]=0;
scc[u]=++sccn;//sccn是強連通分量的編號
size[sccn]=1;//size記錄了強連通分量的大小
//找到某一個low[u]==dfn[u]的節點的時候就要立即處理,因為這個節點也屬於一個新的scc
while(s.top()!=u){
scc[s.top()]=sccn;//scc[u]記錄了u點屬於哪一個scc
ins[s.top()]=0;
size[sccn]+=1;
s.pop();
}
s.pop();
//這裏pop掉的就是一開始的那個low[u]==dfn[u]的節點。因為相關信息已經維護完畢,所以這裏直接pop也沒問題
}
把這兩部分結合在一起,就是tarjan求scc的完整代碼了:
void tarjan(int u){
dfn[u]=low[u]=++cnt;
s.push(u);
ins[u]=1;
for(int i=0;i<gpe[u].size();i++){
int v=gpe[u][i].to;
if(!dfn[v]){
tarjan(v);
low[u]=min(low[u],low[v]);
}else if(ins[v]){
low[u]=min(low[u],dfn[v]);
}
}
if(low[u]==dfn[u]){
ins[u]=0;
scc[u]=++sccn;
size[sccn]=1;
printf("%d ",u);
while(s.top()!=u){
scc[s.top()]=sccn;
printf("%d ",s.top());
ins[s.top()]=0;
size[sccn]+=1;
s.pop();
}
s.pop();
printf("\n");
}
return;
}
tarjan與縮點
tarjan算法最有用的地方就是縮點了。縮點,顧名思義,就是把圖上的某一塊的信息整合成一個點,從而使得後續處理的速度加快(個人的簡單總結,可能會有遺漏之類的)。
先來一個模板題吧:
P2341 受歡迎的牛 G
emmm……題目大意就是對於一條邊u->v代表了u喜歡v ,然後給出了一個奶牛和奶牛之間的關係網(不要問我為什麼是奶牛,這不是usaco題目的傳統藝能嗎),要你求出這群奶牛之中的明星奶牛。明星奶牛就是那些被所有奶牛所喜歡的奶牛。這裏要注意,喜歡是可以傳遞的,也就是說a->b,b->c,那麼a->c。(更多題目細節可以去連接裏面看看)
首先最樸素的dfs方法就是對於每一個點來檢查喜歡它的節點的數量,但是這樣的效率肯定是太低了,所以我們考慮縮點。如果在這個關係網內部存在某一個強連通分量,也就是說這個分量裏面的每一個奶牛都是互相喜歡着的,並且任何喜歡這個分量的奶牛都會喜歡到這個分量內部的每一個奶牛,於是我們可以把這個分量當成一個點來看待。
縮點結束之後的新圖肯定是一個DAG(有向無環圖),又因為縮點本身對題目是沒有影響的,所以我們可以基於這個DAG來分析題目,比之前算是簡單許多了。
很明顯,一個DAG裏面只能有一個明星牛(或者是由明星牛組成的SCC),因為當存在兩個的時候他們是無法互相喜歡的(如果互相喜歡的話就會被縮成一個點)
答案就很明顯了,我們只需要維護每一個SCC的出度(出度為0則證明這就是一個明星),如果存在兩個或兩個以上的明星則證明這個圖裡面沒有明星。如果只有一個的話我們就在tarjan裏面順手維護每一個scc的大小,最後統計一下輸出就完事了
AC代碼:
#include <bits/stdc++.h>
using namespace std;
const int maxn=10010;
struct edge{
int to;
edge(int to_){
to=to_;
}
};
vector<edge> gpe[maxn];
int dfn[maxn],low[maxn],ins[maxn],scc[maxn],size[maxn],cnt=0,sccn=0;
stack<int> s;
void tarjan(int u){
dfn[u]=low[u]=++cnt;
s.push(u);
ins[u]=1;
for(int i=0;i<gpe[u].size();i++){
int v=gpe[u][i].to;
if(!dfn[v]){
tarjan(v);
low[u]=min(low[u],low[v]);
}else if(ins[v]){
low[u]=min(low[u],dfn[v]);
}
}
if(low[u]==dfn[u]){
ins[u]=0;
scc[u]=++sccn;
size[sccn]=1;
while(s.top()!=u){
scc[s.top()]=sccn;
ins[s.top()]=0;
size[sccn]+=1;
s.pop();
}
s.pop();
}
return;
}
int n,m,oud[maxn];
int main(void){
scanf("%d %d",&n,&m);
memset(low,0x3f,sizeof(low));
memset(ins,0,sizeof(ins));
for(int i=1;i<=m;i++){
int u,v;
scanf("%d %d",&u,&v);
gpe[u].push_back(edge(v));
}
for(int i=1;i<=n;i++){
if(!dfn[i]){
cnt=0;
tarjan(i);
}
}
for(int u=1;u<=n;u++){
for(int i=0;i<gpe[u].size();i++){
int v=gpe[u][i].to;
if(scc[u]!=scc[v]) oud[scc[u]]++;
}
}
int cont=0,ans=0;
for(int i=1;i<=sccn;i++){
if(oud[i]==0){
cont++;
ans+=size[i];
}
}
if(cont==1){
printf("%d",ans);
}else{
printf("0");
}
return 0;
}
代碼以前寫的,略冗長,見諒
題目推薦:
真·模板題: P2863 [USACO06JAN]The Cow Prom S
P1262 間諜網絡
P2746 [USACO5.3]校園網Network of Schools
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧