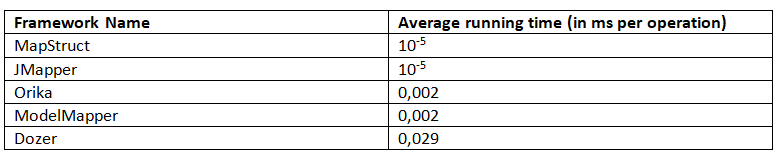本文由 JavaGuide 翻譯自 https://www.baeldung.com/java-performance-mapping-frameworks 。轉載請註明原文地址以及翻譯作者。
1. 介紹
創建由多個層組成的大型 Java 應用程序需要使用多種領域模型,如持久化模型、領域模型或者所謂的 DTO。為不同的應用程序層使用多個模型將要求我們提供 bean 之間的映射方法。手動執行此操作可以快速創建大量樣板代碼並消耗大量時間。幸運的是,Java 有多個對象映射框架。在本教程中,我們將比較最流行的 Java 映射框架的性能。
綜合日常使用情況和相關測試數據,個人感覺 MapStruct、ModelMapper 這兩個 Bean 映射框架是最佳選擇。
2. 常見 Bean 映射框架概覽
2.1. Dozer
Dozer 是一個映射框架,它使用遞歸將數據從一個對象複製到另一個對象。框架不僅能夠在 bean 之間複製屬性,還能夠在不同類型之間自動轉換。
要使用 Dozer 框架,我們需要添加這樣的依賴到我們的項目:
<dependency>
<groupId>net.sf.dozer</groupId>
<artifactId>dozer</artifactId>
<version>5.5.1</version>
</dependency>
更多關於 Dozer 的內容可以在官方文檔中找到: http://dozer.sourceforge.net/documentation/gettingstarted.html ,或者你也可以閱讀這篇文章:https://www.baeldung.com/dozer 。
2.2. Orika
Orika 是一個 bean 到 bean 的映射框架,它遞歸地將數據從一個對象複製到另一個對象。
Orika 的工作原理與 Dozer 相似。兩者之間的主要區別是 Orika 使用字節碼生成。這允許以最小的開銷生成更快的映射器。
要使用 Orika 框架,我們需要添加這樣的依賴到我們的項目:
<dependency>
<groupId>ma.glasnost.orika</groupId>
<artifactId>orika-core</artifactId>
<version>1.5.2</version>
</dependency>
更多關於 Orika 的內容可以在官方文檔中找到:https://orika-mapper.github.io/orika-docs/,或者你也可以閱讀這篇文章:https://www.baeldung.com/orika-mapping。
2.3. MapStruct
MapStruct 是一個自動生成 bean mapper 類的代碼生成器。MapStruct 還能夠在不同的數據類型之間進行轉換。Github 地址:https://github.com/mapstruct/mapstruct。
要使用 MapStruct 框架,我們需要添加這樣的依賴到我們的項目:
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.2.0.Final</version>
</dependency>
更多關於 MapStruct 的內容可以在官方文檔中找到:https://mapstruct.org/,或者你也可以閱讀這篇文章:https://www.baeldung.com/mapstruct。
要使用 MapStruct 框架,我們需要添加這樣的依賴到我們的項目:
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.2.0.Final</version>
</dependency>
2.4. ModelMapper
ModelMapper 是一個旨在簡化對象映射的框架,它根據約定確定對象之間的映射方式。它提供了類型安全的和重構安全的 API。
更多關於 ModelMapper 的內容可以在官方文檔中找到:http://modelmapper.org/ 。
要使用 ModelMapper 框架,我們需要添加這樣的依賴到我們的項目:
<dependency>
<groupId>org.modelmapper</groupId>
<artifactId>modelmapper</artifactId>
<version>1.1.0</version>
</dependency>
2.5. JMapper
JMapper 是一個映射框架,旨在提供易於使用的、高性能的 Java bean 之間的映射。該框架旨在使用註釋和關係映射應用 DRY 原則。該框架允許不同的配置方式:基於註釋、XML 或基於 api。
更多關於 JMapper 的內容可以在官方文檔中找到:https://github.com/jmapper-framework/jmapper-core/wiki。
要使用 JMapper 框架,我們需要添加這樣的依賴到我們的項目:
<dependency>
<groupId>com.googlecode.jmapper-framework</groupId>
<artifactId>jmapper-core</artifactId>
<version>1.6.0.1</version>
</dependency>
3.測試模型
為了能夠正確地測試映射,我們需要有一個源和目標模型。我們已經創建了兩個測試模型。
第一個是一個只有一個字符串字段的簡單 POJO,它允許我們在更簡單的情況下比較框架,並檢查如果我們使用更複雜的 bean 是否會發生任何變化。
簡單的源模型如下:
public class SourceCode {
String code;
// getter and setter
}
它的目標也很相似:
public class DestinationCode {
String code;
// getter and setter
}
源 bean 的實際示例如下:
public class SourceOrder {
private String orderFinishDate;
private PaymentType paymentType;
private Discount discount;
private DeliveryData deliveryData;
private User orderingUser;
private List<Product> orderedProducts;
private Shop offeringShop;
private int orderId;
private OrderStatus status;
private LocalDate orderDate;
// standard getters and setters
}
目標類如下圖所示:
public class Order {
private User orderingUser;
private List<Product> orderedProducts;
private OrderStatus orderStatus;
private LocalDate orderDate;
private LocalDate orderFinishDate;
private PaymentType paymentType;
private Discount discount;
private int shopId;
private DeliveryData deliveryData;
private Shop offeringShop;
// standard getters and setters
}
整個模型結構可以在這裏找到:https://github.com/eugenp/tutorials/tree/master/performance-tests/src/main/java/com/baeldung/performancetests/model/source。
4. 轉換器
為了簡化測試設置的設計,我們創建了如下所示的轉換器接口:
public interface Converter {
Order convert(SourceOrder sourceOrder);
DestinationCode convert(SourceCode sourceCode);
}
我們所有的自定義映射器都將實現這個接口。
4.1. OrikaConverter
Orika 支持完整的 API 實現,這大大簡化了 mapper 的創建:
public class OrikaConverter implements Converter{
private MapperFacade mapperFacade;
public OrikaConverter() {
MapperFactory mapperFactory = new DefaultMapperFactory
.Builder().build();
mapperFactory.classMap(Order.class, SourceOrder.class)
.field("orderStatus", "status").byDefault().register();
mapperFacade = mapperFactory.getMapperFacade();
}
@Override
public Order convert(SourceOrder sourceOrder) {
return mapperFacade.map(sourceOrder, Order.class);
}
@Override
public DestinationCode convert(SourceCode sourceCode) {
return mapperFacade.map(sourceCode, DestinationCode.class);
}
}
4.2. DozerConverter
Dozer 需要 XML 映射文件,有以下幾個部分:
<mappings xmlns="http://dozer.sourceforge.net"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozer.sourceforge.net
http://dozer.sourceforge.net/schema/beanmapping.xsd">
<mapping>
<class-a>com.baeldung.performancetests.model.source.SourceOrder</class-a>
<class-b>com.baeldung.performancetests.model.destination.Order</class-b>
<field>
<a>status</a>
<b>orderStatus</b>
</field>
</mapping>
<mapping>
<class-a>com.baeldung.performancetests.model.source.SourceCode</class-a>
<class-b>com.baeldung.performancetests.model.destination.DestinationCode</class-b>
</mapping>
</mappings>
定義了 XML 映射后,我們可以從代碼中使用它:
public class DozerConverter implements Converter {
private final Mapper mapper;
public DozerConverter() {
DozerBeanMapper mapper = new DozerBeanMapper();
mapper.addMapping(
DozerConverter.class.getResourceAsStream("/dozer-mapping.xml"));
this.mapper = mapper;
}
@Override
public Order convert(SourceOrder sourceOrder) {
return mapper.map(sourceOrder,Order.class);
}
@Override
public DestinationCode convert(SourceCode sourceCode) {
return mapper.map(sourceCode, DestinationCode.class);
}
}
4.3. MapStructConverter
Map 結構的定義非常簡單,因為它完全基於代碼生成:
@Mapper
public interface MapStructConverter extends Converter {
MapStructConverter MAPPER = Mappers.getMapper(MapStructConverter.class);
@Mapping(source = "status", target = "orderStatus")
@Override
Order convert(SourceOrder sourceOrder);
@Override
DestinationCode convert(SourceCode sourceCode);
}
4.4. JMapperConverter
JMapperConverter 需要做更多的工作。接口實現后:
public class JMapperConverter implements Converter {
JMapper realLifeMapper;
JMapper simpleMapper;
public JMapperConverter() {
JMapperAPI api = new JMapperAPI()
.add(JMapperAPI.mappedClass(Order.class));
realLifeMapper = new JMapper(Order.class, SourceOrder.class, api);
JMapperAPI simpleApi = new JMapperAPI()
.add(JMapperAPI.mappedClass(DestinationCode.class));
simpleMapper = new JMapper(
DestinationCode.class, SourceCode.class, simpleApi);
}
@Override
public Order convert(SourceOrder sourceOrder) {
return (Order) realLifeMapper.getDestination(sourceOrder);
}
@Override
public DestinationCode convert(SourceCode sourceCode) {
return (DestinationCode) simpleMapper.getDestination(sourceCode);
}
}
我們還需要向目標類的每個字段添加@JMap註釋。此外,JMapper 不能在 enum 類型之間轉換,它需要我們創建自定義映射函數:
@JMapConversion(from = "paymentType", to = "paymentType")
public PaymentType conversion(com.baeldung.performancetests.model.source.PaymentType type) {
PaymentType paymentType = null;
switch(type) {
case CARD:
paymentType = PaymentType.CARD;
break;
case CASH:
paymentType = PaymentType.CASH;
break;
case TRANSFER:
paymentType = PaymentType.TRANSFER;
break;
}
return paymentType;
}
4.5. ModelMapperConverter
ModelMapperConverter 只需要提供我們想要映射的類:
public class ModelMapperConverter implements Converter {
private ModelMapper modelMapper;
public ModelMapperConverter() {
modelMapper = new ModelMapper();
}
@Override
public Order convert(SourceOrder sourceOrder) {
return modelMapper.map(sourceOrder, Order.class);
}
@Override
public DestinationCode convert(SourceCode sourceCode) {
return modelMapper.map(sourceCode, DestinationCode.class);
}
}
5. 簡單的模型測試
對於性能測試,我們可以使用 Java Microbenchmark Harness,關於如何使用它的更多信息可以在 這篇文章:https://www.baeldung.com/java-microbenchmark-harness 中找到。
我們為每個轉換器創建了一個單獨的基準測試,並將基準測試模式指定為 Mode.All。
5.1. 平均時間
對於平均運行時間,JMH 返回以下結果(越少越好):
這個基準測試清楚地表明,MapStruct 和 JMapper 都有最佳的平均工作時間。
5.2. 吞吐量
在這種模式下,基準測試返回每秒的操作數。我們收到以下結果(越多越好):
在吞吐量模式中,MapStruct 是測試框架中最快的,JMapper 緊隨其後。
5.3. SingleShotTime
這種模式允許測量單個操作從開始到結束的時間。基準給出了以下結果(越少越好):
這裏,我們看到 JMapper 返回的結果比 MapStruct 好得多。
5.4. 採樣時間
這種模式允許對每個操作的時間進行採樣。三個不同百分位數的結果如下:
所有的基準測試都表明,根據場景的不同,MapStruct 和 JMapper 都是不錯的選擇,儘管 MapStruct 對 SingleShotTime 給出的結果要差得多。
6. 真實模型測試
對於性能測試,我們可以使用 Java Microbenchmark Harness,關於如何使用它的更多信息可以在 這篇文章:https://www.baeldung.com/java-microbenchmark-harness 中找到。
我們為每個轉換器創建了一個單獨的基準測試,並將基準測試模式指定為 Mode.All。
6.1. 平均時間
JMH 返回以下平均運行時間結果(越少越好):
該基準清楚地表明,MapStruct 和 JMapper 均具有最佳的平均工作時間。
6.2. 吞吐量
在這種模式下,基準測試返回每秒的操作數。我們收到以下結果(越多越好):
在吞吐量模式中,MapStruct 是測試框架中最快的,JMapper 緊隨其後。
6.3. SingleShotTime
這種模式允許測量單個操作從開始到結束的時間。基準給出了以下結果(越少越好):
6.4. 採樣時間
這種模式允許對每個操作的時間進行採樣。三個不同百分位數的結果如下:
儘管簡單示例和實際示例的確切結果明顯不同,但是它們的趨勢相同。在哪種算法最快和哪種算法最慢方面,兩個示例都給出了相似的結果。
6.5. 結論
根據我們在本節中執行的真實模型測試,我們可以看出,最佳性能顯然屬於 MapStruct。在相同的測試中,我們看到 Dozer 始終位於結果表的底部。
7. 總結
在這篇文章中,我們已經進行了五個流行的 Java Bean 映射框架性能測試:ModelMapper , MapStruct , Orika ,Dozer, JMapper。
示例代碼地址:https://github.com/eugenp/tutorials/tree/master/performance-tests。
開源項目推薦
作者的其他開源項目推薦:
- :【Java學習+面試指南】 一份涵蓋大部分Java程序員所需要掌握的核心知識。
- : 適合新手入門以及有經驗的開發人員查閱的 Spring Boot 教程(業餘時間維護中,歡迎一起維護)。
- : 我覺得技術人員應該有的一些好習慣!
- :從零入門 !Spring Security With JWT(含權限驗證)後端部分代碼。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益