前言
在 Java 中通過鎖來控制多個線程對共享資源的訪問,使用 Java 編程語言開發的朋友都知道,可以通過 synchronized 關鍵字來實現鎖的功能,它可以隱式的獲取鎖,也就是說我們使用該關鍵字並不需要去關心鎖的獲取和釋放過程,但是在提供方便的同時也意味着其靈活性的下降。例如,有這樣的一個場景,先獲取鎖 A,然後再獲取鎖 B,當鎖 B 獲取到之後,釋放鎖 A 同時獲取鎖 C,當獲取鎖 C 后,再釋放鎖 B 同時獲取鎖 D,依次類推,像這種比較複雜的場景,使用 synchronized 關鍵字就比較難實現了。
在 Java SE 5 之後,新增加了 Lock 接口和一系列的實現類來提供和 synchronized 關鍵字一樣的功能,它需要我們显示的進行鎖的獲取和釋放,除此之外還提供了可響應中斷的鎖獲取操作以及超時獲取鎖等同步特性。JDK 中提供的 Lock 接口實現類大部分都是聚合一個同步器 AQS 的子類來實現多線程的訪問控制的,下面我們看看這個構建鎖和其它同步組件的基礎框架——隊列同步器 AQS(AbstractQueuedSynchronizer)。
AQS 基礎數據結構
同步隊列
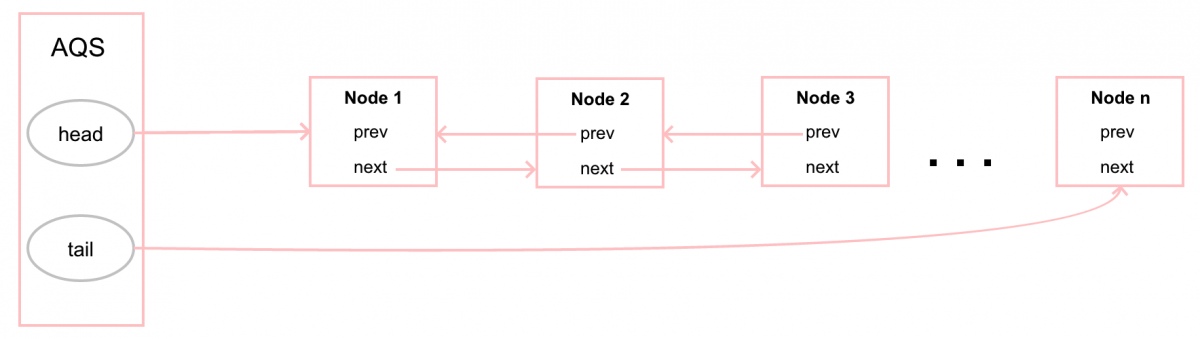
隊列同步器 AQS(下文簡稱為同步器)主要是依賴於內部的一個 FIFO(first-in-first-out)雙向隊列來對同步狀態進行管理的,當線程獲取同步狀態失敗時,同步器會將當前線程和當前等待狀態等信息封裝成一個內部定義的節點 Node,然後將其加入隊列,同時阻塞當前線程;當同步狀態釋放時,會將同步隊列中首節點喚醒,讓其再次嘗試去獲取同步狀態。同步隊列的基本結構如下:
隊列節點 Node
同步隊列使用同步器中的靜態內部類 Node 用來保存獲取同步狀態的線程的引用、線程的等待狀態、前驅節點和後繼節點。
同步隊列中 Node 節點的屬性名稱和具體含義如下錶所示:
| 屬性類型和名稱 |
描述 |
| volatile int waitStatus |
當前節點在隊列中的等待狀態 |
| volatile Node prev |
前驅節點,當節點加入同步隊列時被賦值(使用尾部添加方式) |
| volatile Node next |
後繼節點 |
| volatile Thread thread |
獲取同步狀態的線程 |
| Node nextWaiter |
等待隊列中的後繼節點,如果當前節點是共享的,則該字段是一個 SHARED 常量 |
每個節點線程都有兩種鎖模式,分別為 SHARED 表示線程以共享的模式等待鎖,EXCLUSIVE 表示線程以獨佔的方式等待鎖。同時每個節點的等待狀態 waitStatus 只能取以下錶中的枚舉值:
| 枚舉值 |
描述 |
| SIGNAL |
值為 -1,表示該節點的線程已經準備完畢,等待資源釋放 |
| CANCELLED |
值為 1,表示該節點線程獲取鎖的請求已經取消了 |
| CONDITION |
值為 -2,表示該節點線程等待在 Condition 上,等待被其它線程喚醒 |
| PROPAGATE |
值為 -3,表示下一次共享同步狀態獲取會無限進行下去,只在 SHARED 情況下使用 |
| 0 |
值為 0,初始狀態,初始化的默認值 |
同步狀態 state
同步器內部使用了一個名為 state 的 int 類型的變量表示同步狀態,同步器的主要使用方式是通過繼承,子類通過繼承並實現它的抽象方法來管理同步狀態,同步器給我們提供了如下三個方法來對同步狀態進行更改。
| 方法簽名 |
描述 |
| protected final int getState() |
獲取當前同步狀態 |
| protected final void setState(int newState) |
設置當前同步狀態 |
| protected final boolean compareAndSetState(int expect, int update) |
使用 CAS 設置當前狀態,該方法能夠保證狀態設置的原子性 |
在獨享鎖中同步狀態 state 這個值通常是 0 或者 1(如果是重入鎖的話 state 值就是重入的次數),在共享鎖中 state 就是持有鎖的數量。
獨佔式同步狀態獲取與釋放
同步器中提供了 acquire(int arg) 方法來進行獨佔式同步狀態的獲取,獲取到了同步狀態也就是獲取到了鎖,該方法源碼如下所示:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
方法首先會調用 tryAcquire 方法嘗試去獲取鎖,查看方法的源碼可以發現,同步器並未對該方法進行實現(只是拋出一個不支持操作異常 UnsupportedOperationException),這個方法是需要後續同步組件的開發人員自己去實現的,如果方法返回 true 則表示當前線程成功獲取到鎖,調用 selfInterrupt() 中斷當前線程(PS:這裏留給大家一個問題:為什麼獲取了鎖以後還要中斷線程呢?),方法結束返回,如果方法返回 false 則表示當前線程獲取鎖失敗,也就是說有其它線程先前已經獲取到了鎖,此時就需要把當前線程以及等待狀態等信息添加到同步隊列中,下面來看看同步器在線程未獲取到鎖時具體是如何實現。
通過源碼發現,當獲取鎖失敗時,會執行判斷條件與操作的後半部分 acquireQueued(addWaiter(Node.EXCLUSIVE), arg),首先指定鎖模式為 Node.EXCLUSIVE 調用 addWaiter 方法,該方法源碼如下:
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
通過方法參數指定的鎖模式(共享鎖 or 獨佔鎖)和當前線程構造出一個 Node 節點,如果同步隊列已經初始化,那麼首先會進行一次從尾部加入隊列的嘗試,使用 compareAndSetTail 方法保證原子性,進入該方法源碼可以發現是基於 sun.misc 包下提供的 Unsafe 類來實現的。如果首次嘗試加入同步隊列失敗,會再次調用 enq 方法進行入隊操作,繼續跟進 enq 方法源碼如下:
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
通過其源碼可以發現和第一次嘗試加入隊列的代碼類似,只是該方法裏面加了同步隊列初始化判斷,使用 compareAndSetHead 方法保證設置頭節點的原子性,同樣它底層也是基於 Unsafe 類,然後外層套了一個 for (; 死循環,循環唯一的退出條件是從隊尾入隊成功,也就是說如果從該方法成功返回了就表示已經入隊成功了,至此,addWaiter 執行完畢返回當前 Node 節點。然後以該節點作為 acquireQueued 方法的入參繼續進行其它步驟,該方法如下所示:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
可以看到,該方法本質上也是通過一個死循環(自旋)去獲取鎖並且支持中斷,在循環體外面定義兩個標記變量,failed 標記是否成功獲取到鎖,interrupted 標記在等待的過程中是否被中斷過。方法首先通過 predecessor 獲取當前節點的前驅節點,噹噹前節點的前驅節點是 head 頭節點時就調用 tryAcquire 嘗試獲取鎖,也就是第二個節點則嘗試獲取鎖,這裏為什麼要從第二個節點才嘗試獲取鎖呢?是因為同步隊列本質上是一個雙向鏈表,在雙向鏈表中,第一個節點並不存儲任何數據是虛節點,只是起到一個佔位的作用,真正存儲數據的節點是從第二個節點開始的。如果成功獲取鎖,也就是 tryAcquire 方法返回 true 后,將 head 指向當前節點並把之前找到的頭節點 p 從隊列中移除,修改是否成功獲取到鎖標記,結束方法返回中斷標記。
如果當前節點的前驅節點 p 不是頭節點或者前驅節點 p 是頭節點但是獲取鎖操作失敗,那麼會調用 shouldParkAfterFailedAcquire 方法判斷當前 node 節點是否需要被阻塞,這裏的阻塞判斷主要是為了防止長時間自旋給 CPU 帶來非常大的執行開銷,浪費資源。該方法源碼如下:
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
方法參數為當前節點的前驅節點以及當前節點,主要是靠前驅節點來判斷是否需要進行阻塞,首先獲取到前驅節點的等待狀態 ws,如果節點狀態 ws 為 SIGNAL,表示前驅節點的線程已經準備完畢,等待資源釋放,方法返回 true 表示可以阻塞,如果 ws > 0,通過上文可以知道節點只有一個狀態 CANCELLED(值為 1) 滿足該條件,表示該節點線程獲取鎖的請求已經取消了,會通過一個 do-while 循環向前查找 CANCELLED 狀態的節點並將其從同步隊列中移除,否則進入 else 分支,使用 compareAndSetWaitStatus 原子操作將前驅節點的等待狀態修改為 SIGNAL,以上這兩種情況都不需要進行阻塞方法返回 false。
當經過判斷後需要阻塞的話,也就是 compareAndSetWaitStatus 方法返回 true 時,會通過 parkAndCheckInterrupt 方法阻塞掛起當前線程,並返回當前線程的中斷標識。方法如下:
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
線程阻塞是通過 LockSupport 這個工具類實現的,深入其源碼可以發現它底層也是基於 Unsafe 類實現的。如果以上兩個方法都返回 true 的話就更新中斷標記。這裏還有一個問題就是什麼時候會將一個節點的等待狀態 waitStatus 修改為 CANCELLED 節點線程獲取鎖的請求取消狀態呢?細心的朋友可能已經發現了,在上文貼出的 acquireQueued 方法源碼中的 finally 塊中會根據 failed 標記來決定是否調用 cancelAcquire 方法,這個方法就是用來將節點狀態修改為 CANCELLED 的,方法的具體實現留給大家去探索。至此 AQS 獨佔式同步狀態獲取鎖的流程就完成了,下面通過一個流程圖來看看整體流程:
下面再看看獨佔式鎖釋放的過程,同步器使用 release 方法來讓我們進行獨佔式鎖的釋放,其方法源碼如下:
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
首先調用 tryRelease 方法嘗試進行鎖釋放操作,繼續跟進該方法發現同步器只是拋出了一個不支持操作異常 UnsupportedOperationException,這裏和上文獨佔鎖獲取中 tryAcquire 方法是一樣的套路,需要開發者自己定義鎖釋放操作。
通過其 JavaDoc 可以得知,如果返回 false,則表示釋放鎖失敗,方法結束。該方法如果返回 true,則表示當前線程釋放鎖成功,需要通知隊列中等待獲取鎖的線程進行鎖獲取操作。首先獲取頭節點 head,如果當前頭節點不為 null,並且其等待狀態不是初始狀態(0),則解除線程阻塞掛起狀態,通過 unparkSuccessor 方法實現,該方法源碼如下:
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
首先獲取頭節點的等待狀態 ws,如果狀態值為負數(Node.SIGNAL or Node.PROPAGATE),則通過 CAS 操作將其改為初始狀態(0),然後獲取頭節點的後繼節點,如果後繼節點為 null 或者後繼節點狀態為 CANCELLED(獲取鎖請求已取消),就從隊列尾部開始尋找第一個狀態為非 CANCELLED 的節點,如果該節點不為空則使用 LockSupport 的 unpark 方法將其喚醒,該方法底層是通過 Unsafe 類的 unpark 實現的。這裏需要從隊尾查找非 CANCELLED 狀態的節點的原因是,在之前的獲取獨佔鎖失敗時的入隊 addWaiter 方法實現中,該方法如下:
假設一個線程執行到了上圖中的 ① 處,② 處還沒有執行,此時另一個線程恰好執行了 unparkSuccessor 方法,那麼就無法通過從前向後查找了,因為節點的後繼指針 next 還沒賦值呢,所以需要從后往前進行查找。至此,獨佔式鎖釋放操作就結束了,同樣的,最後我們也通過一個流程圖來看看整個鎖釋放的過程:
獨佔式可中斷同步狀態獲取
同步器提供了 acquireInterruptibly 方法來進行可響應中斷的獲取鎖操作,方法實現源碼如下:
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
方法首先檢查當前線程的中斷狀態,如果已中斷,則直接拋出中斷異常 InterruptedException 即響應中斷,否則調用 tryAcquire 方法嘗試獲取鎖,如果獲取成功則方法結束返回,獲取失敗調用 doAcquireInterruptibly 方法,跟進該方法如下:
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
仔細觀察可以發現該方法實現源碼和上文中 acquireQueued 方法的實現基本上類似,只是這裏把入隊操作 addWaiter 放到了方法裏面了,還有一個區別就是當在循環體內判斷需要進行中斷時會直接拋出異常來響應中斷,兩個方法的對比如下:
其它步驟和獨佔式鎖獲取一致,流程圖大體上和不響應中斷的鎖獲取差不多,只是在最開始多了一步線程中斷狀態檢查和循環是會拋出中斷異常而已。
獨佔式超時獲取同步狀態
同步器提供了 tryAcquireNanos 方法可以超時獲取同步狀態(也就是鎖),該方法提供了之前 synchronized 關鍵字不支持的超時獲取的特性,通過該方法我們可以在指定時間段 nanosTimeout 內獲取鎖,如果獲取到鎖則返回 true,否則,返回 false。方法源碼如下:
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
首先會調用 tryAcquire 方法嘗試獲取一次鎖,如果獲取鎖成功則立即返回,否則調用 doAcquireNanos 方法進入超時獲取鎖流程。通過上文可以得知,同步器的 acquireInterruptibly 方法在等待獲取同步狀態時,如果當前線程被中斷了,會拋出中斷異常 InterruptedException 並立刻返回。超時獲取鎖的流程其實是在響應中斷的基礎上增加了超時獲取的特性,doAcquireNanos 方法的源碼如下:
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (nanosTimeout <= 0L)
return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0L)
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
由以上方法實現源碼可以看出,針對超時獲取這裏主要實現思路是:先使用當前時間加上參數傳入的超時時間間隔 deadline 計算出超時的時間點,然後每次進行循環的時候使用超時時間點 deadline 減去當前時間得到剩餘的時間 nanosTimeout,如果剩餘時間小於 0 則證明當前獲取鎖操作已經超時,方法結束返回 false,反如果剩餘時間大於 0。
可以看到在裏面執行自旋的時候和上面獨佔式同步獲取鎖狀態 acquireQueued 方法那裡是一樣的套路,即噹噹前節點的前驅節點為頭節點時調用 tryAcquire 嘗試獲取鎖,如果獲取成功則返回。
除了超時時間計算那裡不同外,還有個不同的地方就是在超時獲取鎖失敗之後的操作,如果當前線程獲取鎖失敗,則判斷剩餘超時時間 nanosTimeout 是否小於 0,如果小於 0 則表示已經超時方法立即返回,反之則會判斷是否需要進行阻塞掛起當前線程,如果通過 shouldParkAfterFailedAcquire 方法判斷需要掛起阻塞當前線程,還要進一步比較超時剩餘時間 nanosTimeout 和 spinForTimeoutThreshold 的大小,如果小於等於 spinForTimeoutThreshold 值(1000 納秒)的話,將不會使當前線程進行超時等待,而是再次進行自旋過程。
加後面這個判斷的主要原因在於,在非常短(小於 1000 納秒)的時間內的等待無法做到十分精確,如果這時還進行超時等待的話,反而會讓我們指定 nanosTimeout 的超時從整體上給人感覺反而不太精確,因此,在剩餘超時時間非常短的情況下,同步器會再次自旋進行超時獲取鎖的過程,獨佔式超時獲取鎖整個過程如下所示:
共享式同步狀態獲取與釋放
共享鎖顧名思義就是可以多個線程共用一個鎖,在同步器中使用 acquireShared 來獲取共享鎖(同步狀態),方法源碼如下:
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
首先通過 tryAcquireShared 嘗試獲取共享鎖,該方法是一個模板方法在同步器中只是拋出一個不支持操作異常,需要開發人員自己去實現,同時方法的返回值有三種不同的類型分別代表三種不同的狀態,其含義如下:
- 小於 0 表示當前線程獲取鎖失敗
- 等於 0 表示當前線程獲取鎖成功,但是之後的線程在沒有鎖釋放的情況下獲取鎖將失敗,也就是說這個鎖是共享模式下的最後一把鎖了
- 大於 0 表示當前線程獲取鎖成功,並且還有剩餘的鎖可以獲取
當方法 tryAcquireShared 返回值小於 0 時,也就是獲取鎖失敗,將會執行方法 doAcquireShared,繼續跟進該方法:
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
方法首先調用 addWaiter 方法封裝當前線程和等待狀態為共享模塊的節點並將其添加到等待同步隊列中,可以發現在共享模式下節點的 nextWaiter 屬性是固定值 Node.SHARED。然後循環獲取當前節點的前驅節點,如果前驅節點是頭節點的話就嘗試獲取共享鎖,如果返回值大於等於 0 表示獲取共享鎖成功,則調用 setHeadAndPropagate 方法,更新頭節點同時如果有可用資源,則向後傳播,喚醒後繼節點,接下來會檢查一下中斷標識,如果已經中斷則中斷當前線程,方法結束返回。如果返回值小於 0,則表示獲取鎖失敗,需要掛起阻塞當前線程或者繼續自旋獲取共享鎖。下面看看 setHeadAndPropagate 方法的具體實現:
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
/*
* Try to signal next queued node if:
* Propagation was indicated by caller,
* or was recorded (as h.waitStatus either before
* or after setHead) by a previous operation
* (note: this uses sign-check of waitStatus because
* PROPAGATE status may transition to SIGNAL.)
* and
* The next node is waiting in shared mode,
* or we don't know, because it appears null
*
* The conservatism in both of these checks may cause
* unnecessary wake-ups, but only when there are multiple
* racing acquires/releases, so most need signals now or soon
* anyway.
*/
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
首先將當前獲取到鎖的節點設置為頭節點,然後方法參數 propagate > 0 時表示之前 tryAcquireShared 方法的返回值大於 0,也就是說當前還有剩餘的共享鎖可以獲取,則獲取當前節點的後繼節點並且後繼節點是共享節點時喚醒節點去嘗試獲取鎖,doReleaseShared 方法是同步器共享鎖釋放的主要邏輯。
同步器提供了 releaseShared 方法來進行共享鎖的釋放,方法源碼如下所示:
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
首先調用 tryReleaseShared 方法嘗試釋放共享鎖,方法返回 false 代表鎖釋放失敗,方法結束返回 false,否則就表示成功釋放鎖,然後執行 doReleaseShared 方法,進行喚醒後繼節點並檢查它是否可以向後傳播等操作。繼續跟進該方法如下:
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
可以看到和獨佔式鎖釋放不同的是,在共享模式下,狀態同步和釋放可以同時執行,其原子性由 CAS 來保證,如果頭節點改變了也會繼續循環。每次共享節點在共享模式下喚醒時,頭節點都會指向它,這樣就可以保證可以獲取到共享鎖的所有後續節點都可以喚醒了。
如何自定義同步組件
在 JDK 中基於同步器實現的一些類絕大部分都是聚合了一個或多個繼承了同步器的類,使用同步器提供的模板方法自定義內部同步狀態的管理,然後通過這個內部類去實現同步狀態管理的功能,其實這從某種程度上來說使用了 模板模式。比如 JDK 中可重入鎖 ReentrantLock、讀寫鎖 ReentrantReadWriteLock、信號量 Semaphore 以及同步工具類 CountDownLatch 等,其源碼部分截圖如下:
通過上文可以知道,我們基於同步器可以分別自定義獨佔鎖同步組件和共享鎖同步組件,下面以實現一個在同一個時刻最多只允許 3 個線程訪問,其它線程的訪問將被阻塞的同步工具 TripletsLock 為例,很顯然這個工具是共享鎖模式,主要思路就是去實現一個 JDk 中的 Lock 接口來提供面向使用者的方法,比如,調用 lock 方法獲取鎖,使用 unlock 來對鎖進行釋放等,在 TripletsLock 類內部有一個自定義同步器 Sync 繼承自同步器 AQS,用來對線程的訪問和同步狀態進行控制,當線程調用 lock 方法獲取鎖時,自定義同步器 Sync 先計算出獲取到鎖后的同步狀態,然後使用 Unsafe 類操作來保證同步狀態更新的原子性,由於同一時刻只能 3 個線程訪問,這裏我們可以將同步狀態 state 的初始值設置為 3,表示當前可用的同步資源數量,當有線程成功獲取到鎖時將同步狀態 state 減 1,有線程成功釋放鎖時將同步狀態加 1,同步狀態的取值範圍為 0、1、2、3,同步狀態為 0 時表示沒有可用同步資源,這個時候如果有線程訪問將被阻塞。下面來看看這個自定義同步組件的實現代碼:
/**
* @author mghio
* @date: 2020-06-13
* @version: 1.0
* @description:
* @since JDK 1.8
*/
public class TripletsLock implements Lock {
private final Sync sync = new Sync(3);
private static final class Sync extends AbstractQueuedSynchronizer {
public Sync(int state) {
setState(state);
}
Condition newCondition() {
return new ConditionObject();
}
@Override
protected int tryAcquireShared(int reduceCount) {
for (; ;) {
int currentState = getState();
int newState = currentState - reduceCount;
if (newState < 0 || compareAndSetState(currentState, newState)) {
return newState;
}
}
}
@Override
protected boolean tryReleaseShared(int count) {
for (; ;) {
int currentState = getState();
int newState = currentState + count;
if (compareAndSetState(currentState, newState)) {
return true;
}
}
}
}
@Override
public void lock() {
sync.acquireShared(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
return sync.tryAcquireShared(1) > 0;
}
@Override
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
@Override
public void unlock() {
sync.releaseShared(1);
}
@Override
public Condition newCondition() {
return sync.newCondition();
}
}
下面啟動 20 個線程測試看看自定義同步同步工具類 TripletsLock 是否達到我們的預期。測試代碼如下:
/**
* @author mghio
* @date: 2020-06-13
* @version: 1.0
* @description:
* @since JDK 1.8
*/
public class TripletsLockTest {
private final Lock lock = new TripletsLock();
private final DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
@Test
public void testTripletsLock() {
// 啟動 20 個線程
for (int i = 0; i < 20; i++) {
Thread worker = new Runner();
worker.setDaemon(true);
worker.start();
}
for (int i = 0; i < 20; i++) {
second(2);
System.out.println();
}
}
private class Runner extends Thread {
@Override
public void run() {
for (; ;) {
lock.lock();
try {
second(1);
System.out.println(dateFormat.format(new Date()) + " ----> " + Thread.currentThread().getName());
second(1);
} finally {
lock.unlock();
}
}
}
}
private static void second(long seconds) {
try {
TimeUnit.SECONDS.sleep(seconds);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
測試結果如下:
從以上測試結果可以發現,同一時刻只有三個線程可以獲取到鎖,符合預期,這裏需要明確的是這個鎖獲取過程是非公平的。
總結
本文主要是對同步器中的基礎數據結構、獨佔式與共享式同步狀態獲取與釋放過程做了簡要分析,由於水平有限如有錯誤之處還請留言討論。隊列同步器 AbstractQueuedSynchronizer 是 JDK 中很多的一些多線程併發工具類的實現基礎框架,對其深入學習理解有助於我們更好的去使用其特性和相關工具類。
參考文章
Java併發編程的藝術
Java Synchronizer – AQS Learning
從 ReentrantLock 的實現看 AQS 的原理及應用
The java.util.concurrent Synchronizer Framework
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!