摘要:本文針對“數據牽引改進,工具固化規範”這一思路在業務團隊落地過程中的動作流程進行詳細闡述,並明確了支撐整個流程的關鍵角色定義和組織運作形式。
目的
為實現雲服務開發的過程可信,需要基於數據對各個服務產品部的可信變革動作進行數據採集、進展可視、目標牽引、能力評估,最終用數據反映目標達成。與傳統的“基於數據晾曬驅動業務團隊改進,6+1指標度量”的運作方式有本質的區別,我們是基於統一的作業工具上產生的客觀數據呈現,識別研發過程中基本的流程斷裂點和質量缺失動作,和業務團隊達成一致的目標后,把大部分改進動作固話到作業工具中自動化承載,我們稱這個思路為“數據牽引改進,工具固化規範”,也就是我們不僅告訴業務團隊哪裡有問題,同時也要基於我們的作業工具,輔助業務團隊一起改進完善。
本文針對“數據牽引改進,工具固化規範”這一思路在業務團隊落地過程中的動作流程進行詳細闡述,並明確了支撐整個流程的關鍵角色定義和組織運作形式。
數據牽引改進,是指關注軟件交付過程中各種度量數據的收集、統計、分析和反饋,通過可視化的數據客觀反映整個研發過程的狀態,以全局視角分析系統約束點,並和業務團隊達成共識,提煉出客觀有效的改進目標;工具固化規範,針對識別出來的Gap點和重點問題進行分析,制定出可以在作業工具承載的模板規範,以及需要工程師行為做出改變的能力要求,並在作業工具上對這些規範要求的落地效果進行檢查,用數據度量改進效果。最後,對改進項目進行總結分享,打造學習型組織,不斷驅動持續改進和價值交付,牽引研發團隊模式和文化的轉變。
2020年的研發過程可信圍繞CleanCode、構建、開源、E2E追溯四個領域開展,這也是公司要求的可信變革中最基本、最重要、投入產出比最大的四個點。
整體流程說明
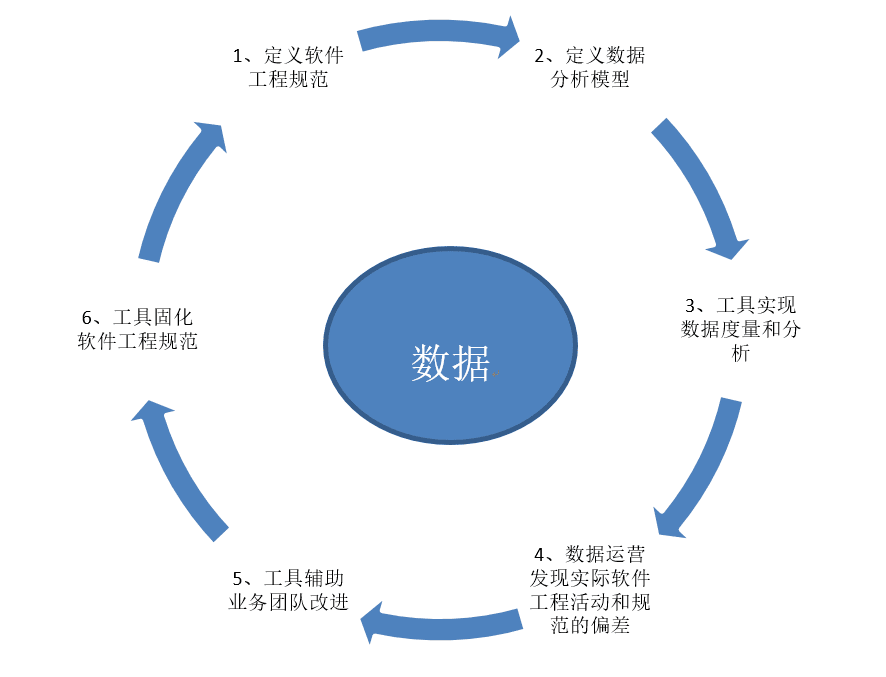
整個運作流程,圍繞數據,按照“定義軟件工程規範->定義數據分析模型->工具實現數據度量和分析->數據運營發現實際軟件工程活動和規範的偏差->工具輔助團隊改進->工具固化軟件工程規範”這個流程進行實施,並對最終效果進行階段性總結。隨着業務團隊能力的提升以及軟件工程規範性、開發模式的改變,對最初定義的軟件工程規範,會階段性的進行完善,循環往複、持續優化,最終讓業務團隊在遵守公司要求的研發過程可信規範的前提下,實現業務成功。
1) 定義軟件工程規範:圍繞公司可信變革的目標,BU對各個服務產品部的研發模式規範和能力要求,COE制定適合BU現狀的軟件工程規範;
2) 定義數據模型:COE針對制定的軟件工程規範,提煉出核心的、有針對性、可用工具度量的數據模型,並且和各個服務產品部達成一致;
3) 工具實現數據度量和分析:根據這幾個數據模型,數據分析工具自動從數據源進行採集、匯總、計算,並把結果呈現在數據看板上;業務團隊可以打開匯總數據,根據明細數據進行動作規範自檢和改進;
4) 數據運營發現實際軟件工程活動和規範的偏差:數據治理小組在實際運營過程中,分析度量指標的數據,識別業務團隊實際的軟件工程活動和要求規範不一致的Gap點和關鍵問題;
5) 工具輔助業務團隊改進:COE針對分析出來的Gap點和關鍵問題,制定相應的改進措施,作業工具承載流程規範模板化整改,並針對業務團隊的不規範行為,制定適合各個服務產品部的公約要求,促使業務團隊人員能力提升;
6) 工具固化軟件工程規範:針對業務團隊的公約要求,在作業工具上進行check,最終作業工具承載了整個軟件工程規範要求,以及融入到作業流程中的規範要求事前檢查。
三層數據分析模型
我們採用了三層數據分析模型,由作業工具自動採集用戶研發過程行為明細數據,數據分析工具進行准實時匯總計算呈現總體目標,三層數據系統性的輔助業務團隊系統性的識別研發過程中的不規範點和能力短板,讓業務團隊“知其然,知其所以然”。這三層數據模型是層層深入,迭代完善,下層支撐上層的關係。
第一層:目標、進展、結果數據分析;和公司可信變革目標牽引對齊,結合BU實際情況,形成BU的整體可信要求,並在數據分析看板上呈現各個服務產品部要達成的過程可信目標、每日的改進進展和最終完成情況;例如,對各個服務產品部要求達成CleanCode的目標。
第二層:詞法/語法分析數據;COE針對第一層的目標牽引,分解出來的具體實施環節的度量指標,只有這些分解的指標都完成,第一層的目標才達成。這一層數據的目的主要是圍繞幫助業務團隊分析自己的能力短板在哪裡,進行有針對性的改進指;通過打開匯總數據的層層下鑽,用明細數據來分析業務團隊在DevSecOps軟件工程規範流程中關鍵動作執行的缺失點,並針對性的制定改進規範要求,牽引作業工具或者業務團隊補齊該部分缺失動作;例如,CleanCode的過程可信目標達成,可以分解成:靜態檢查配置合規率、Committer合入保障率、代碼倉Clean三個目標,只有這三個目標達成,就可以認為CleanCode總體目標達成。
第三層:語義分析數據:COE打開第二層數據,不僅要看這些關鍵動過做沒做,還要看做的效果怎麼樣,最終效果體現在業務團隊的DevSecOps軟件工程規範提升;這一層的數據分析聚焦在防止為了指標而做第二層的數據,而是看業務團隊是否在真正參考BU制定的規範牽引的目標,提升業務交付過程中的效能、可信、質量能力,以及最終產生實際的業務效果。通過打開各個團隊的明細數據分析審視業務團隊執行的關鍵動作是否符合規範,是否在合適的階段點執行,執行效果是否有效;並階段性的總結和提煉經驗,形成知識資產固化到作業工具。例如,針對第二層的靜態檢查配置合規率,可以分解為:靜態檢查配置有效性和靜態檢查執行有效性。靜態檢查配置有效性,包括:檢查靜態檢查工具配置的數量、是否符合BU的配置規範,以及是否在代碼合入主幹master時進行了配置;靜態檢查執行有效性,主要看是否每一次MR提交時都執行靜態檢查、是否發現問題在研發活動的最早階段,攔截的問題的效果怎麼樣。只有第三層的動作度量都達成后,才可以說第二層的目標是達成的。
數據治理過程流程圖
為了實現“數據牽引改進,工具固化規範”這個目標,準確、一致、准實時的數據是核心關鍵,但因為數據採集不完整、業務團隊不規範、數據呈現維度不一致等原因,數據的準確性有一個不斷提升的過程,因此需要對各個層級展示的數據進行治理。整個數據治理過程中,由“業務團隊/作業工具/治理小組/數據分析工具(阿基米德)/COE”五個角色緊密配合,而且以年/半年為目標,不斷總結經驗,循環往複、持續優化的過程。
a) COE:和公司可信變革目標牽引對齊,結合BU能力現狀,形成BU的整體可信要求;
b) COE:針對BU的業務現狀,定義出適合BU現狀的軟件工程規範要求;業務團隊:和BU發布的各個領域的軟件工程規範牽引目標達成一致;
c) COE:針對規範分解出核心的度量指標,並制定度量數據模型;
d) 研發用戶:在使用作業工具進行研發活動;作業工具:承載了BU各個服務產品部在使用過程中沉澱的行為數據;
e) 數據分析(阿基米德):准實時接入作業工具的數據,展示各個服務產品部當前的研發能力現狀;
f) COE:和各個服務產品部達成一致,制定各個服務產品部的年度牽引目標;
g) 數據分析(阿基米德):用數據呈現各個服務產品部的牽引目標和能力現狀,統一數據口徑;呈現月/周/天的明細數據,以及支撐Gap分析和重點問題的數據視圖;
h) COE:根據牽引目標和能力現狀,分析Gap原因和關鍵問題;治理小組:在數據運營過程中,根據數據分析團隊當前的能力現狀是否和數據呈現一致;
i) 研發用戶:可以實時登錄數據工具(阿基米德)進行查看各個層級的明細數據;
j) 治理小組:根據准實時進展數據,分析當前團隊研發過程中的實際問題,並匯總給COE;
k) COE:結合細粒度的分析數據、以及治理小組匯總出來的各個服務產品部的實際問題,制定規範和改進措施,包括作業工具的規範和研發用戶的動作行為公約;
l) 作業工具:承載作業工具上落地的規範要求;治理小組:作為接口人,承接研發工程師的行為規範公約,結合各個服務產品部實際情況來負責落地;
m) 研發用戶:按照規範要求和針對數據的自檢進行研發過程行為規範化;
n) 研發工具:對研發用戶的行為規範是否滿足要求進行自動化檢查;最終目標是讓整個軟件工程規範都固化在工具中進行承載;
o) 數據分析(阿基米德):呈現按照規範改進后的明細數據和匯總目標;研發用戶:自助查看整改后的明細數據;
p) COE:根據數據改進的效果,以及過程中暴露的問題進行總結后形成經驗資產,並持續改進;
數據流圖
過程可信的數據在各個工具系統中採集、流轉、匯聚、分析、呈現,整個數據流圖如下:
其中,識別出6個重要的全量數據源:
a) 代碼庫數據:該數據由伏羲的服務信息樹上配置的代碼庫數據,加上阿基米德上人工配置的代碼庫,構成各個雲服務發布到生產倉的代碼全集;
b) Workitem信息流數據:當前識別vision上的需求、問題、task,加上Gitlab/Codeclub上的issue,構成可識別的Workitem數據全集;
c) SRE現網包數據:包括普羅部署、CCE、CPS、CDK各種類型部署的包數據,構成全量現網包數據;
d) 開源二進制包數據:開源中心倉數據(java、python、go、nodejs四種)語言,加上公司c/c++的數據構成全量開源二進制包數據;
e) 研發過程配置數據:阿基米德上配置的committer數據是全量的committer數據;阿基米德上識別出來的主分支是全量的主分支(邏輯“master”)數據;
f) 伏羲研發過程數據:伏羲三個庫,MongoDB的靜態檢查、門禁數據;MySQL中的測試、發布數據;MySQL中包和多個流水線的對應關係數據;一起構成了以“包”為維度的全量伏羲研發過程數據;
運作組織
數據治理運營團隊
按照過程可信在BU的落地策略,在CleanCode、構建、開源、E2E追溯四個領域設置數據治理運營團隊,由 “數據分析工具(阿基米德)—COE—各個服務產品部接口人組成的治理小組”三個角色組成,以“指標度量為牽引,數據的客觀呈現為落地方式,業務的價值反饋為最終目的”的原則來落地數據治理工作。
COE的職責:
1) 和公司可信變革目標牽引對齊,結合BU能力現狀,形成BU的整體可信要求;定義出適合BU現狀的軟件工程規範要求;針對規範分解出核心的度量指標,並制定度量數據模型;
2) 利用作業工具已經產生的數據,和治理小組一起分析識別數據質量的問題,按照三層數據分析模型,層層打開,識別業務團隊能力Gap點。
3) 分析典型問題,識別作業流的斷裂點進行補齊,和業務團隊的不規範動作,制定規範和公約要求,逐步改善數據質量。
4) 事後歸納總結,識別出流程缺失,組織缺失,責任缺失等機制行問題,並固化到作業工具中。
治理小組:
1) 結合各個服務產品部的實際情況,承接COE的數據治理規範在各個服務產品部的落地;
2) 識別數據治理動作在各個服務產品部落地過程中的實際問題,和COE一起分析,提出系統性的解決思路,最終固化到作業工具中。
3) 跟蹤過程可信在業務團隊落地的過程中的進展,為業務團隊最終達成可信變革目標負責,為改進過程產生實際的業務價值負責;
數據分析工具(阿基米德):
1) 確保接入的數據準確、實時、一致,用數據實時反映BU各個服務產品部的能力現狀,為COE和治理小組的數據運營提供數據支撐;
2) 系統性的落地COE的方案設計,實現整個BU統一標準的數據看板,能夠清晰的通過數據識別出來業務團隊的能力Gap,牽引業務團隊達成整體改進目標;
3) 按照三層數據模型進行數據展示,層層下鑽,讓業務團隊“知其然,知其所以然”,牽引業務團隊中的每一個人都能自己進行改進;
4) 通過數據分析,識別DevSecOps軟件工程規範在BU的業務團隊落地過程中的重點問題,以及該問題背後的流程、制度缺失,促使最終規範固化在作業工具中。
例會設置
“數據驅動DevSecOps能力提升例會”為研發領域數據治理相關問題的求助和裁決例會。
會議分為三個階段:
1) 第一階段,例行議題,形式類似於“體檢報告”,用數據反映業務團隊的現狀和問題;
2) 第二階段,申報議題,形式類似於“專家會診”,討論某一個具體數據治理過程中的問題和Top困難求助;
3) 第三階段,靈活安排議題,形式類似於“問題總結”,針對某一類的具體問題,進行集中討論和歸納總結定義,形成BU的規範流程和章程總結。
主數據承載系統
主數據是指具有高業務價值的、可以在企業內跨越多個業務部門被重複使用的數據,是單一、準確、權威的數據來源。和業務型數據、分析型數據相比,主數據主要有以下幾個特徵:
1) 特徵一致性:也就是能否保證主數據的關鍵特徵在不同應用、不同系統中的高度一致,直接關係了數據治理成敗;
2) 識別唯一性:在一個系統、一個平台,甚至一個企業範圍內,同一主數據實體要求具有唯一的數據標識,即數據編碼;
3) 長期有效性:貫穿該業務對象的整個生命周期甚至更長,當該主數據失去其效果時,系統採取的措施通常為軟刪除,而不是物理刪除;
4) 業務穩定性:在業務過程中其識別信息和關鍵特徵會被業務過程中產生的數據繼承、引用和複製。除非該主數據本身的特徵發生變化,否則該主數據不會隨着業務的過程中被其他系統修改。
主數據源識別原則:
a) 如果有多個數據源構成同類型數據的主數據,兩種處理策略:
1)選取一個源系統逐步收編其他源系統的數據,變成唯一主數據源
2)如果1)不能實現,由阿基米德系統進行封裝后屏蔽多個數據源系統,該類型數據的唯一數據源變成阿基米德,待後續1)實現后,阿基米德該類型主數據源失效。
3)當數據在多個作業系統中進行流轉時,判斷是否作為主數據源的標準是:數據在該系統有實際的業務動作產生,而不是只承載數據的流轉。
b) 如果確定為唯一數據源,其他消費該類型數據的系統不能和數據源產生衝突。
所有數據僅能在數據源產生,其它系統只能讀取不能修改。下游發現的數據源質量問題,應當在數據源頭進行修正。
c) 主數據使用方不得改變原始數據,但可以進行擴展。
數據消費方不得對獲取的數據進行增、刪、改,但可以在數據的基礎上進行屬性擴展。
d) 在滿足信息安全的前提下充分共享,不得拒絕合理的數據共享需求。
數據如果不流轉,不僅不會產生業務價值,還增加存儲成本;只有不斷流轉,對業務團隊產生實際價值時,還能得到使用效果的反饋,促進數據價值的進一步提升。
原則為:核心資產安全優先,非關鍵資產效率優先。
一類主數據源
二類主數據源
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※別再煩惱如何寫文案,掌握八大原則!