Python的垃圾回收機制包括了兩大部分:
- 引用計數(大部分在
Include/object.h 中定義)
- 標記清除+隔代回收(大部分在
Modules/gcmodule.c 中定義)
1. 引用計數機制
python中萬物皆對象,他的核心結構是:PyObject
typedef __int64 ssize_t;
typedef ssize_t Py_ssize_t;
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt; // Py_ssize_t __int64
struct _typeobject *ob_type;
} PyObject;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
PyObject是每個對象的底層數據結構,其中ob_refcnt就是作為引用計數。當一個對象有新的引用時, 它的ob_refcnt就會增加,當引用它的對象被刪除,它的ob_refcnt就會減少,當引用技術為0時,該對象的生命結束了。
- 引用計數+1的情況
- 對象被創建 eg: a=2
- 對象被引用 eg: b=a
- 對象被作為參數,傳入到一個函數中,例如func(a)
- 對象作為一個元素,存儲在容器中,例如list1=[a, b]
- 引用計數-1的情況
- 對象的別名被显示的銷毀 eg: del a
- 對象的別名被賦予新的對象 eg: a=34
- 一個對象離開它的作用域, 例如f函數執行完畢時,func函數中的局部變量(全局變量不會)
- 對象所在的容器被銷毀,或者從容器中刪除
如何查看對象的引用計數
import sys
a = 'hello'
sys.getrefcount(a)
// 注意: getrefcount(a) 傳入a時, a的引用計數會加1
1.1 什麼時候觸發回收
當一個對象的引用計數變為了 0, 會直接進入釋放空間的流程
/* cpython/Include/object.h */
static inline void _Py_DECREF(const char *filename, int lineno,
PyObject *op)
{
_Py_DEC_REFTOTAL;
if (--op->ob_refcnt != 0) {
#ifdef Py_REF_DEBUG
if (op->ob_refcnt < 0) {
_Py_NegativeRefcount(filename, lineno, op);
}
#endif
}
else {
/* // _Py_Dealloc 會找到對應類型的 descructor, 並且調用這個 descructor
destructor dealloc = Py_TYPE(op)->tp_dealloc;
(*dealloc)(op);
*/
_Py_Dealloc(op);
}
}
2. 常駐內存對象
引用計數機制所帶來的維護引用計數的額外操作,與python運行中所進行的內存分配、釋放、引用賦值的次數是成正比的,這一點,相對於主流的垃圾回收技術,比如標記–清除(mark--sweep)、停止–複製(stop--copy)等方法相比是一個弱點,因為它們帶來額外操作只和內存數量有關,至於多少人引用了這塊內存則不關心。因此為了與引用計數搭配、在內存的分配和釋放上獲得最高的效率,python設計了大量的內存池機制,比如小整數對象池、字符串的intern機制,列表的freelist緩衝池等等,這些大量使用的面向特定對象的內存池機制正是為了彌補引用計數的軟肋。
2.1 小整數對象池
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
#if NSMALLNEGINTS + NSMALLPOSINTS > 0
/* Small integers are preallocated in this array so that they
can be shared.
The integers that are preallocated are those in the range
-NSMALLNEGINTS (inclusive) to NSMALLPOSINTS (not inclusive).
*/
static PyLongObject small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
Py_INCREF(op) 增加對象引用計數
Py_DECREF(op) 減少對象引用計數, 如果計數位0, 調用_Py_Dealloc
_Py_Dealloc(op) 調用對應類型的 tp_dealloc 方法
小整數對象池就是一個PyLongObject 數組, 大小=257+5=262, 範圍是[-5, 257) 注意左閉右開.
python對小整數的定義是[-5, 257), 這些整數對象是提前建立好的,不會被垃圾回收,在一個python程序中,所有位於這個範圍內的整數使用的都是同一個對象
2.2 大整數對象池
疑惑:《Python源碼剖析》提到的整數對象池block_list應該已經不存在了(因為PyLongObject為變長對象)。Python2中的PyIntObject實際是對c中的long的包裝。所以Python2也提供了專門的緩存池,供大整數輪流使用,避免每次使用不斷的malloc分配內存帶來的效率損耗,可參考劉志軍老師的講解。既然沒有池了,malloc/free會帶來的不小性能損耗。Guido認為Py3.0有極大的優化空間,在字符串和整形操作上可以取得很好的優化結果。
/* Allocate a new int object with size digits.
Return NULL and set exception if we run out of memory. */
#define MAX_LONG_DIGITS \
((PY_SSIZE_T_MAX - offsetof(PyLongObject, ob_digit))/sizeof(digit))
PyLongObject *
_PyLong_New(Py_ssize_t size)
{
PyLongObject *result;
/* Number of bytes needed is: offsetof(PyLongObject, ob_digit) +
sizeof(digit)*size. Previous incarnations of this code used
sizeof(PyVarObject) instead of the offsetof, but this risks being
incorrect in the presence of padding between the PyVarObject header
and the digits. */
if (size > (Py_ssize_t)MAX_LONG_DIGITS) {
PyErr_SetString(PyExc_OverflowError,
"too many digits in integer");
return NULL;
}
result = PyObject_MALLOC(offsetof(PyLongObject, ob_digit) +
size*sizeof(digit));
if (!result) {
PyErr_NoMemory();
return NULL;
}
return (PyLongObject*)PyObject_INIT_VAR(result, &PyLong_Type, size);
}
result = PyObject_MALLOC(offsetof(PyLongObject, ob_digit) + size*sizeof(digit));
每一個大整數,均創建一個新的對象。id(num)均不同。
2.4 字符串的intern機制
Objects/unicodeobject.c
Objects/codeobject.c
PyStringObject對象的intern機制之目的是:對於被intern之後的字符串,比如“Ruby”,在整個Python的運行期間,系統中都只有唯一的一個與字符串“Ruby”對應的PyStringObject對象。這樣當判斷兩個PyStringObject對象是否相同時,如果它們都被intern了,那麼只需要簡單地檢查它們對應的PyObject*是否相同即可。這個機制既節省了空間,又簡化了對PyStringObject對象的比較,嗯,可謂是一箭雙鵰哇。
摘自:《Python源碼剖析》 — 陳儒
Python3中PyUnicodeObject對象的intern機制和Python2的PyStringObject對象intern機制一樣,主要為了節省內存的開銷,利用字符串對象的不可變性,對存在的字符串對象重複利用
In [50]: a = 'python'
In [51]: b = 'python'
In [52]: id(a)
Out[52]: 442782398256
In [53]: id(b)
Out[53]: 442782398256
In [54]: b = 'hello python'
In [55]: a = 'hello python'
In [56]: id(a)
Out[56]: 442808585520
In [57]: id(b)
Out[57]: 442726541488
什麼樣的字符串會使用intern機制?
intern機制跟編譯時期有關,相關代碼在Objects/codeobject.c
/* Intern selected string constants */
static int
intern_string_constants(PyObject *tuple)
{
int modified = 0;
Py_ssize_t i;
for (i = PyTuple_GET_SIZE(tuple); --i >= 0; ) {
PyObject *v = PyTuple_GET_ITEM(tuple, i);
if (PyUnicode_CheckExact(v)) {
if (PyUnicode_READY(v) == -1) {
PyErr_Clear();
continue;
}
if (all_name_chars(v)) {
PyObject *w = v;
PyUnicode_InternInPlace(&v);
if (w != v) {
PyTuple_SET_ITEM(tuple, i, v);
modified = 1;
}
}
}
/*....*/
}
/* all_name_chars(s): true iff s matches [a-zA-Z0-9_]* */
static int
all_name_chars(PyObject *o)
{
const unsigned char *s, *e;
if (!PyUnicode_IS_ASCII(o))
return 0;
s = PyUnicode_1BYTE_DATA(o);
e = s + PyUnicode_GET_LENGTH(o);
for (; s != e; s++) {
if (!Py_ISALNUM(*s) && *s != '_')
return 0;
}
return 1;
}
可見 all_name_chars 決定了是否會 intern,簡單來說就是 ascii 字母,数字和下劃線組成的字符串會被緩存。但是不僅如此。2.5還會說
/* This dictionary holds all interned unicode strings. Note that references
to strings in this dictionary are *not* counted in the string's ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->state ? 2 : 0)
*/
static PyObject *interned = NULL;
/*省略*/
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
#ifdef Py_DEBUG
assert(s != NULL);
assert(_PyUnicode_CHECK(s));
#else
if (s == NULL || !PyUnicode_Check(s))
return;
#endif
/* If it's a subclass, we don't really know what putting
it in the interned dict might do. */
if (!PyUnicode_CheckExact(s))
return;
// [1]
if (PyUnicode_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
// [2]
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
// [3]
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
// [4]
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}
通過函數我們可以得知,python中維護這一個interned變量的指針,這個變量指向PyDict_New創建的對象,而PyDict_New實際上創建了一個PyDictObject對象,是Python中dict類型的對象。實際上intern機制就是維護一個字典,這個字典中記錄著被intern機制處理過的字符串對象,[1]處PyUnicode_CHECK_INTERNED宏檢查字符串對象的state.interned是否被標記,
如果字符串對象的state.interned被標記了,就直接返回;[2]處嘗試把沒有被標記的字符串對象s作為key-value加入interned字典中;[3]處表示字符串對象s已經在interned字典中(對應的value值是字符串對象t),(通過Py_SETREF宏來改變p指針的指向),且原字符串對象p會因引用計數為零被回收。Py_SETREF宏在Include/object.h定義着:
/* Safely decref `op` and set `op` to `op2`.
*
* As in case of Py_CLEAR "the obvious" code can be deadly:
*
* Py_DECREF(op);
* op = op2;
*
* The safe way is:
*
* Py_SETREF(op, op2);
*
* That arranges to set `op` to `op2` _before_ decref'ing, so that any code
* triggered as a side-effect of `op` getting torn down no longer believes
* `op` points to a valid object.
*
* Py_XSETREF is a variant of Py_SETREF that uses Py_XDECREF instead of
* Py_DECREF.
*/
#define Py_SETREF(op, op2) \
do { \
PyObject *_py_tmp = (PyObject *)(op); \
(op) = (op2); \
Py_DECREF(_py_tmp); \
} while (0)
[4]中把新加入interned字典中的字符串對象做減引用操作,並把state.interned標記成SSTATE_INTERNED_MORTAL。SSTATE_INTERNED_MORTAL表示字符串對象被intern機制處理,但會隨着引用計數被回收;interned標記還有另外一種SSTATE_INTERNED_IMMORTAL,表示被intern機制處理但對象不可銷毀,會與Python解釋器同在。PyUnicode_InternInPlace只能創建SSTATE_INTERNED_MORTAL狀態的字符串,要想創建SSTATE_INTERNED_IMMORTAL狀態的字符串需要通過另外一個接口,強制改變intern的狀態
void
PyUnicode_InternImmortal(PyObject **p)
{
PyUnicode_InternInPlace(p);
if (PyUnicode_CHECK_INTERNED(*p) != SSTATE_INTERNED_IMMORTAL) {
_PyUnicode_STATE(*p).interned = SSTATE_INTERNED_IMMORTAL;
Py_INCREF(*p);
}
}
為什麼引用Py_REFCNT(s) -= 2;要-2呢?
PyDict_SetDefault(PyObject *d, PyObject *key, PyObject *defaultobj)
{
PyDictObject *mp = (PyDictObject *)d;
PyObject *value;
Py_hash_t hash;
/*...*/
if (ix == DKIX_EMPTY) {
/*...*/
Py_ssize_t hashpos = find_empty_slot(mp->ma_keys, hash);
ep0 = DK_ENTRIES(mp->ma_keys);
ep = &ep0[mp->ma_keys->dk_nentries];
dictkeys_set_index(mp->ma_keys, hashpos, mp->ma_keys->dk_nentries);
Py_INCREF(key);
Py_INCREF(value);
/*...*/
return value;
}
對於被intern機制處理了的PyStringObject對象,Python採用了特殊的引用計數機制。在將一個PyStringObject對象a的PyObject指針作為key和value添加到interned中時,PyDictObject對象會通過這兩個指針對a的引用計數進行兩次加1的操作。但是Python的設計者規定在interned中a的指針不能被視為對象a的有效引用,因為如果是有效引用的話,那麼a的引用計數在Python結束之前永遠都不可能為0,因為interned中至少有兩個指針引用了a,那麼刪除a就永遠不可能了,這顯然是沒有道理的。
摘自:《Python源碼剖析》 — 陳儒
注意:實際上,即使Python會對一個字符串進行intern機制的處理,也會先創建一個PyUnicodeObject對象,然後檢查在interned字典中是否有值和其相同,存在的話就將interned字典保存的value值返回,之前臨時創建的字符串對象會由於引用計數為零而回收。
是否可以直接對C原生對象做intern的動作呢?不需要創建臨時對象
事實上CPython確實提供了以char * 為參數的intern機制相關函數,但是,也是一樣的創建temp在設置intern.
PyUnicode_InternImmortal(PyObject **p)
{
PyUnicode_InternInPlace(p);
if (PyUnicode_CHECK_INTERNED(*p) != SSTATE_INTERNED_IMMORTAL) {
_PyUnicode_STATE(*p).interned = SSTATE_INTERNED_IMMORTAL;
Py_INCREF(*p);
}
}
為什麼需要臨時對象?
因為PyDict_SetDefault() 操作的是PyDictObject對象,而該對象必須以PyObject*指針作為鍵
2.5 字符緩衝池(單字符)
python為小整數對象準備了小整數對象池,當然對於常用的字符,python對應的也建了字符串緩衝池,因為 python3 中通過 unicode_latin1[256] 將長度為 1 的 ascii 的字符也緩存了
/* Single character Unicode strings in the Latin-1 range are being
shared as well. */
static PyObject *unicode_latin1[256] = {NULL};
unicode_decode_utf8(){
/*省略*/
/* ASCII is equivalent to the first 128 ordinals in Unicode. */
if (size == 1 && (unsigned char)s[0] < 128) {
if (consumed)
*consumed = 1;
return get_latin1_char((unsigned char)s[0]);
}
/*省略*/
}
static PyObject*
get_latin1_char(unsigned char ch)
{
PyObject *unicode = unicode_latin1[ch];
if (!unicode) {
unicode = PyUnicode_New(1, ch);
if (!unicode)
return NULL;
PyUnicode_1BYTE_DATA(unicode)[0] = ch;
assert(_PyUnicode_CheckConsistency(unicode, 1));
unicode_latin1[ch] = unicode;
}
Py_INCREF(unicode);
return unicode;
}
In [46]: a = 'p'
In [47]: b = 'p'
In [48]: id(a)
Out[48]: 442757120384
In [49]: id(b)
Out[49]: 442757120384
當然單字符也包括空字符。
/* The empty Unicode object is shared to improve performance. */
static PyObject *unicode_empty = NULL;
In [8]: a = 'hello' + 'python'
In [9]: b = 'hellopython'
In [10]: a is b
Out[10]: True
In [11]: a = 'hello ' + 'python'
In [12]: b = 'hello python'
In [13]: id(a)
Out[13]: 118388503536
In [14]: id(b)
Out[14]: 118387544240
In [15]: 'hello ' + 'python' is 'hello python'
Out[15]: False
In [16]: 'hello_' + 'python' is 'hello_python'
Out[16]: True
2.6 小結:
-
小整數[-5, 257)共用對象,常駐內存
-
單個字母,長度為 1 的 ascii 的字符latin1會被interned, 包括空字符,共用對象,常駐內存
-
由字母、数字、下劃線([a-zA-Z0-9_])組成的字符串,不可修改,默認開啟intern機制,共用對象,引用計數為0時,銷毀
-
字符串(含有空格),不可修改,沒開啟intern機制,不共用對象,引用計數為0,銷毀
3. 標記清除+分代回收
為了防止出現循環引用的致命性問題,python採用的是引用計數機製為主,標記-清除和分代收集兩種機製為輔的策略。
我們設置 n1.next 指向 n2,同時設置 n2.prev 指回 n1,現在,我們的兩個節點使用循環引用的方式構成了一個`雙向鏈表`,同時請注意到 ABC 以及 DEF 的引用計數值已經增加到了2,現在,假定我們的程序不再使用這兩個節點了,我們將 n1 和 n2 都設置為None,Python會像往常一樣將每個節點的引用計數減少到1。
### 3.1 在python中的零代(Generation Zero)
Ruby使用一個鏈表(free_list)來持續追蹤未使用的、自由的對象,Python使用一種不同的鏈表來持續追蹤活躍的對象。而不將其稱之為“活躍列表”,Python的內部C代碼將其稱為零代(Generation Zero)。每次當你創建一個對象或其他什麼值的時候,Python會將其加入零代鏈表:
從上邊可以看到當我們創建ABC節點的時候,Python將其加入零代鏈表。請注意到這並不是一個真正的列表,並不能直接在你的代碼中訪問,事實上這個鏈表是一個完全內部的Python運行時。
疑惑1:對於容器對象(比如list、dict、class、instance等等),是在什麼時候綁定GC,放入第0鏈表呢?
相似的,當我們創建DEF節點的時候,Python將其加入同樣的鏈表:
現在零代包含了兩個節點對象。(他還將包含Python創建的每個其他值,與一些Python自己使用的內部值。)
3.2 標記循環引用
當達到某個 閾值之後 解釋器會循環遍歷,循環遍歷零代列表上的每個對象,檢查列表中每個互相引用的對象,根據規則減掉其引用計數。在這個過程中,Python會一個接一個的統計內部引用的數量以防過早地釋放對象。以下例子便於理解:
從上面可以看到 ABC 和 DEF 節點包含的引用數為1.有三個其他的對象同時存在於零代鏈表中,藍色的箭頭指示了有一些對象正在被零代鏈表之外的其他對象所引用。
通過識別內部引用,Python能夠減少許多零代鏈表對象的引用計數。在上圖的第一行中你能夠看見ABC和DEF的引用計數已經變為零了,這意味着收集器可以釋放它們並回收內存空間了。剩下的活躍的對象則被移動到一個新的鏈表:一代鏈表。
疑惑2: 內部如何識別零代的循環引用計數,在什麼閾值下會觸發GC執行?
3.3 在源碼中摸索答案
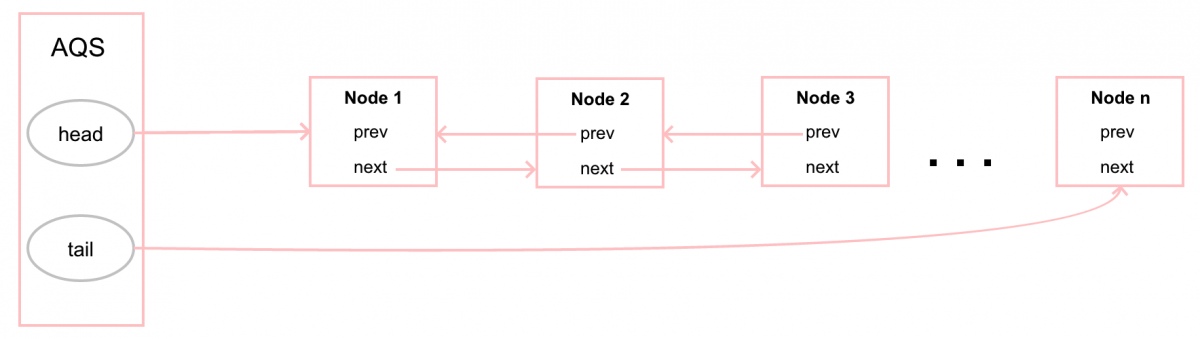
Python通過PyGC_Head來跟蹤container對象,PyGC_Head信息位於PyObject_HEAD之前,定義在Include/objimpl.h中
typedef union _gc_head {
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
double dummy; /* force worst-case alignment */
} PyGC_Head;
表頭數據結構
//Include/internal/mem.h
struct gc_generation {
PyGC_Head head;
int threshold; /* collection threshold */ // 閾值
int count; /* count of allocations or collections of younger
generations */ // 實時個數
};
Python中用於分代垃圾收集的三個“代”由_gc_runtime_state.generations數組所表示着:
解答疑惑2,三個代的閾值如下數組
/* If we change this, we need to cbhange the default value in the
signature of gc.collect. */
#define NUM_GENERATIONS 3
_PyGC_Initialize(struct _gc_runtime_state *state)
{
state->enabled = 1; /* automatic collection enabled? */
#define _GEN_HEAD(n) (&state->generations[n].head)
struct gc_generation generations[NUM_GENERATIONS] = {
/* PyGC_Head, threshold, count */
{{{_GEN_HEAD(0), _GEN_HEAD(0), 0}}, 700, 0},
{{{_GEN_HEAD(1), _GEN_HEAD(1), 0}}, 10, 0},
{{{_GEN_HEAD(2), _GEN_HEAD(2), 0}}, 10, 0},
};
for (int i = 0; i < NUM_GENERATIONS; i++) {
state->generations[i] = generations[i];
};
state->generation0 = GEN_HEAD(0);
struct gc_generation permanent_generation = {
{{&state->permanent_generation.head, &state->permanent_generation.head, 0}}, 0, 0
};
state->permanent_generation = permanent_generation;
}
**解答疑惑1:那container對象是什麼時候加入第0“代”的container對象鏈表呢?**
對於python內置對象的創建,container對象是通過PyObject_GC_New函數來創建的,而非container對象是通過PyObject_Malloc函數來創建的。
// Include/objimpl.h
#define PyObject_GC_New(type, typeobj) \
( (type *) _PyObject_GC_New(typeobj) )
// 調用了Modules/gcmodule.c中的_PyObject_GC_New函數:
PyObject *
_PyObject_GC_New(PyTypeObject *tp)
{
PyObject *op = _PyObject_GC_Malloc(_PyObject_SIZE(tp));
if (op != NULL)
op = PyObject_INIT(op, tp);
return op;
}
static PyObject *
_PyObject_GC_Alloc(int use_calloc, size_t basicsize)
{
PyObject *op;
PyGC_Head *g;
size_t size;
if (basicsize > PY_SSIZE_T_MAX - sizeof(PyGC_Head))
return PyErr_NoMemory();
size = sizeof(PyGC_Head) + basicsize;
// [1] 申請PyGC_Head和對象本身的內存
if (use_calloc)
g = (PyGC_Head *)PyObject_Calloc(1, size);
else
g = (PyGC_Head *)PyObject_Malloc(size);
if (g == NULL)
return PyErr_NoMemory();
// [2] 設置gc_refs的值
g->gc.gc_refs = 0;
_PyGCHead_SET_REFS(g, GC_UNTRACKED);
// [3]
generations[0].count++; /* number of allocated GC objects */
if (generations[0].count > generations[0].threshold &&
enabled &&
generations[0].threshold &&
!collecting &&
!PyErr_Occurred()) {
collecting = 1;
collect_generations();
collecting = 0;
}
// [4] FROM_GC宏定義可以通過PyGC_Head地址轉換PyObject_HEAD地址,逆運算是AS_GC宏定義。
op = FROM_GC(g);
return op;
}
PyObject *
_PyObject_GC_Malloc(size_t basicsize)
{
return _PyObject_GC_Alloc(0, basicsize);
}
[4] FROM_GC宏定義可以通過PyGC_Head地址轉換PyObject_HEAD地址,逆運算是AS_GC宏定義。
/* Get an object's GC head */
#define AS_GC(o) ((PyGC_Head *)(o)-1)
/* Get the object given the GC head */
#define FROM_GC(g) ((PyObject *)(((PyGC_Head *)g)+1))
當觸發閾值后,是如何進行GC回收的?
collect是垃圾回收的主入口函數。特別注意 finalizers 與 python 的__del__綁定了。
/* This is the main function. Read this to understand how the
* collection process works. */
static Py_ssize_t
collect(int generation, Py_ssize_t *n_collected, Py_ssize_t *n_uncollectable,
int nofail)
{
int i;
Py_ssize_t m = 0; /* # objects collected */
Py_ssize_t n = 0; /* # unreachable objects that couldn't be collected */
PyGC_Head *young; /* the generation we are examining */
PyGC_Head *old; /* next older generation */
PyGC_Head unreachable; /* non-problematic unreachable trash */
PyGC_Head finalizers; /* objects with, & reachable from, __del__ */
PyGC_Head *gc;
_PyTime_t t1 = 0; /* initialize to prevent a compiler warning */
struct gc_generation_stats *stats = &_PyRuntime.gc.generation_stats[generation];
...
// “標記-清除”前的準備
// 垃圾標記
// 垃圾清除
...
/* Update stats */
if (n_collected)
*n_collected = m;
if (n_uncollectable)
*n_uncollectable = n;
stats->collections++;
stats->collected += m;
stats->uncollectable += n;
if (PyDTrace_GC_DONE_ENABLED())
PyDTrace_GC_DONE(n+m);
return n+m;
}
3.3.1 標記-清除前的準備
// [1]
/* update collection and allocation counters */
if (generation+1 < NUM_GENERATIONS)
_PyRuntime.gc.generations[generation+1].count += 1;
for (i = 0; i <= generation; i++)
_PyRuntime.gc.generations[i].count = 0;
// [2]
/* merge younger generations with one we are currently collecting */
for (i = 0; i < generation; i++) {
gc_list_merge(GEN_HEAD(i), GEN_HEAD(generation));
}
// [3]
/* handy references */
young = GEN_HEAD(generation);
if (generation < NUM_GENERATIONS-1)
old = GEN_HEAD(generation+1);
else
old = young;
// [4]
/* Using ob_refcnt and gc_refs, calculate which objects in the
* container set are reachable from outside the set (i.e., have a
* refcount greater than 0 when all the references within the
* set are taken into account).
*/
update_refs(young);
subtract_refs(young);
[1] 先更新了將被回收的“代”以及老一“代”的count計數器。
這邊對老一“代”的count計數器增量1就可以看出來在第1“代”和第2“代”的count值其實表示的是該代垃圾回收的次數。
[2] 通過gc_list_merge函數將這些“代”合併成一個鏈表。
/* append list `from` onto list `to`; `from` becomes an empty list */
static void
gc_list_merge(PyGC_Head *from, PyGC_Head *to)
{
PyGC_Head *tail;
assert(from != to);
if (!gc_list_is_empty(from)) {
tail = to->gc.gc_prev;
tail->gc.gc_next = from->gc.gc_next;
tail->gc.gc_next->gc.gc_prev = tail;
to->gc.gc_prev = from->gc.gc_prev;
to->gc.gc_prev->gc.gc_next = to;
}
gc_list_init(from);
}
static void
gc_list_init(PyGC_Head *list)
{
list->gc.gc_prev = list;
list->gc.gc_next = list;
}
gc_list_merge函數將from鏈錶鏈接到to鏈表末尾並把from鏈表置為空鏈表。
[3] 經過合併操作之後,所有需要被進行垃圾回收的對象都鏈接到young“代”(滿足超過閾值的最老“代”),並記錄old“代”,後面需要將不可回收的對象移到old“代”。
鏈表的合併操作:
[4] 尋找root object集合
要對合併的鏈表進行垃圾標記,首先需要尋找root object集合。
所謂的root object即是一些全局引用和函數棧中的引用。這些引用所用的對象是不可被刪除的。
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
a = list1
del list1
del list2
上面的Python中循環引用的代碼,變量a所指向的對象就是root object。
三色標記模型
3.3.2 垃圾標記
// [1]
/* Leave everything reachable from outside young in young, and move
* everything else (in young) to unreachable.
* NOTE: This used to move the reachable objects into a reachable
* set instead. But most things usually turn out to be reachable,
* so it's more efficient to move the unreachable things.
*/
gc_list_init(&unreachable);
move_unreachable(young, &unreachable);
// [2]
/* Move reachable objects to next generation. */
if (young != old) {
if (generation == NUM_GENERATIONS - 2) {
_PyRuntime.gc.long_lived_pending += gc_list_size(young);
}
gc_list_merge(young, old);
}
else {
/* We only untrack dicts in full collections, to avoid quadratic
dict build-up. See issue #14775. */
untrack_dicts(young);
_PyRuntime.gc.long_lived_pending = 0;
_PyRuntime.gc.long_lived_total = gc_list_size(young);
}
[1] 初始化不可達鏈表,調用move_unreachable函數將循環引用的對象移動到不可達鏈表中:
/* Move the unreachable objects from young to unreachable. After this,
* all objects in young have gc_refs = GC_REACHABLE, and all objects in
* unreachable have gc_refs = GC_TENTATIVELY_UNREACHABLE. All tracked
* gc objects not in young or unreachable still have gc_refs = GC_REACHABLE.
* All objects in young after this are directly or indirectly reachable
* from outside the original young; and all objects in unreachable are
* not.
*/
static void
move_unreachable(PyGC_Head *young, PyGC_Head *unreachable)
{
PyGC_Head *gc = young->gc.gc_next;
/* Invariants: all objects "to the left" of us in young have gc_refs
* = GC_REACHABLE, and are indeed reachable (directly or indirectly)
* from outside the young list as it was at entry. All other objects
* from the original young "to the left" of us are in unreachable now,
* and have gc_refs = GC_TENTATIVELY_UNREACHABLE. All objects to the
* left of us in 'young' now have been scanned, and no objects here
* or to the right have been scanned yet.
*/
while (gc != young) {
PyGC_Head *next;
if (_PyGCHead_REFS(gc)) {
/* gc is definitely reachable from outside the
* original 'young'. Mark it as such, and traverse
* its pointers to find any other objects that may
* be directly reachable from it. Note that the
* call to tp_traverse may append objects to young,
* so we have to wait until it returns to determine
* the next object to visit.
*/
PyObject *op = FROM_GC(gc);
traverseproc traverse = Py_TYPE(op)->tp_traverse;
assert(_PyGCHead_REFS(gc) > 0);
_PyGCHead_SET_REFS(gc, GC_REACHABLE);
(void) traverse(op,
(visitproc)visit_reachable,
(void *)young);
next = gc->gc.gc_next;
if (PyTuple_CheckExact(op)) {
_PyTuple_MaybeUntrack(op);
}
}
else {
/* This *may* be unreachable. To make progress,
* assume it is. gc isn't directly reachable from
* any object we've already traversed, but may be
* reachable from an object we haven't gotten to yet.
* visit_reachable will eventually move gc back into
* young if that's so, and we'll see it again.
*/
next = gc->gc.gc_next;
gc_list_move(gc, unreachable);
_PyGCHead_SET_REFS(gc, GC_TENTATIVELY_UNREACHABLE);
}
gc = next;
}
}
這邊遍歷young“代”的container對象鏈表,_PyGCHead_REFS(gc)判斷是不是root object或從某個root object能直接/間接引用的對象,由於root object集合中的對象是不能回收的,因此,被這些對象直接或間接引用的對象也是不能回收的。
_PyGCHead_REFS(gc)為0並不能斷定這個對象是可回收的,但是還是先移動到unreachable鏈表中,設置了GC_TENTATIVELY_UNREACHABLE標誌表示暫且認為是不可達的,如果是存在被root object直接或間接引用的對象,這樣的對象還會被移出unreachable鏈表中。
[2] 將可達的對象移到下一“代”。
3.3.3 垃圾清除
// [1]
/* All objects in unreachable are trash, but objects reachable from
* legacy finalizers (e.g. tp_del) can't safely be deleted.
*/
gc_list_init(&finalizers);
move_legacy_finalizers(&unreachable, &finalizers);
/* finalizers contains the unreachable objects with a legacy finalizer;
* unreachable objects reachable *from* those are also uncollectable,
* and we move those into the finalizers list too.
*/
move_legacy_finalizer_reachable(&finalizers);
// [2]
/* Collect statistics on collectable objects found and print
* debugging information.
*/
for (gc = unreachable.gc.gc_next; gc != &unreachable;
gc = gc->gc.gc_next) {
m++;
}
// [3]
/* Clear weakrefs and invoke callbacks as necessary. */
m += handle_weakrefs(&unreachable, old);
// [4]
/* Call tp_finalize on objects which have one. */
finalize_garbage(&unreachable);
// [5]
if (check_garbage(&unreachable)) {
revive_garbage(&unreachable);
gc_list_merge(&unreachable, old);
}
else {
/* Call tp_clear on objects in the unreachable set. This will cause
* the reference cycles to be broken. It may also cause some objects
* in finalizers to be freed.
*/
delete_garbage(&unreachable, old);
}
// [6]
/* Collect statistics on uncollectable objects found and print
* debugging information. */
for (gc = finalizers.gc.gc_next;
gc != &finalizers;
gc = gc->gc.gc_next) {
n++;
}
...
// [7]
/* Append instances in the uncollectable set to a Python
* reachable list of garbage. The programmer has to deal with
* this if they insist on creating this type of structure.
*/
(void)handle_legacy_finalizers(&finalizers, old);
/* Clear free list only during the collection of the highest
* generation */
if (generation == NUM_GENERATIONS-1) {
clear_freelists();
}
[1] 處理unreachable鏈表中有finalizer的對象。即python中 實現了__del__魔法方法的對象
/* Move the objects in unreachable with tp_del slots into `finalizers`.
* Objects moved into `finalizers` have gc_refs set to GC_REACHABLE; the
* objects remaining in unreachable are left at GC_TENTATIVELY_UNREACHABLE.
*/
static void
move_legacy_finalizers(PyGC_Head *unreachable, PyGC_Head *finalizers)
{
PyGC_Head *gc;
PyGC_Head *next;
/* March over unreachable. Move objects with finalizers into
* `finalizers`.
*/
for (gc = unreachable->gc.gc_next; gc != unreachable; gc = next) {
PyObject *op = FROM_GC(gc);
assert(IS_TENTATIVELY_UNREACHABLE(op));
next = gc->gc.gc_next;
if (has_legacy_finalizer(op)) {
gc_list_move(gc, finalizers);
_PyGCHead_SET_REFS(gc, GC_REACHABLE);
}
}
}
遍歷unreachable鏈表,將擁有finalizer的實例對象移到finalizers鏈表中,並標示為GC_REACHABLE。
/* Return true if object has a pre-PEP 442 finalization method. */
static int
has_legacy_finalizer(PyObject *op)
{
return op->ob_type->tp_del != NULL;
}
擁有finalizer的實例對象指的就是實現了tp_del函數的對象。
/* Move objects that are reachable from finalizers, from the unreachable set
* into finalizers set.
*/
static void
move_legacy_finalizer_reachable(PyGC_Head *finalizers)
{
traverseproc traverse;
PyGC_Head *gc = finalizers->gc.gc_next;
for (; gc != finalizers; gc = gc->gc.gc_next) {
/* Note that the finalizers list may grow during this. */
traverse = Py_TYPE(FROM_GC(gc))->tp_traverse;
(void) traverse(FROM_GC(gc),
(visitproc)visit_move,
(void *)finalizers);
}
}
對finalizers鏈表中擁有finalizer的實例對象遍歷其引用對象,調用visit_move訪問者,這些被引用的對象也不應該被釋放。
/* A traversal callback for move_legacy_finalizer_reachable. */
static int
visit_move(PyObject *op, PyGC_Head *tolist)
{
if (PyObject_IS_GC(op)) {
if (IS_TENTATIVELY_UNREACHABLE(op)) {
PyGC_Head *gc = AS_GC(op);
gc_list_move(gc, tolist);
_PyGCHead_SET_REFS(gc, GC_REACHABLE);
}
}
return 0;
}
#define IS_TENTATIVELY_UNREACHABLE(o) ( \
_PyGC_REFS(o) == GC_TENTATIVELY_UNREACHABLE)
visit_move函數將引用對象還在unreachable鏈表的對象移到finalizers鏈表中。
[2] 統計unreachable鏈表數量。
[3] 處理弱引用。
[4] [5] 開始清除垃圾對象,我們先只看delete_garbage函數:
/* Break reference cycles by clearing the containers involved. This is
* tricky business as the lists can be changing and we don't know which
* objects may be freed. It is possible I screwed something up here.
*/
static void
delete_garbage(PyGC_Head *collectable, PyGC_Head *old)
{
inquiry clear;
while (!gc_list_is_empty(collectable)) {
PyGC_Head *gc = collectable->gc.gc_next;
PyObject *op = FROM_GC(gc);
if (_PyRuntime.gc.debug & DEBUG_SAVEALL) {
PyList_Append(_PyRuntime.gc.garbage, op);
}
else {
if ((clear = Py_TYPE(op)->tp_clear) != NULL) {
Py_INCREF(op);
clear(op);
Py_DECREF(op);
}
}
if (collectable->gc.gc_next == gc) {
/* object is still alive, move it, it may die later */
gc_list_move(gc, old);
_PyGCHead_SET_REFS(gc, GC_REACHABLE);
}
}
}
遍歷unreachable鏈表中的container對象,調用其類型對象的tp_clear指針指向的函數,我們以list對象為例:
static int
_list_clear(PyListObject *a)
{
Py_ssize_t i;
PyObject **item = a->ob_item;
if (item != NULL) {
/* Because XDECREF can recursively invoke operations on
this list, we make it empty first. */
i = Py_SIZE(a);
Py_SIZE(a) = 0;
a->ob_item = NULL;
a->allocated = 0;
while (--i >= 0) {
Py_XDECREF(item[i]);
}
PyMem_FREE(item);
}
/* Never fails; the return value can be ignored.
Note that there is no guarantee that the list is actually empty
at this point, because XDECREF may have populated it again! */
return 0;
}
_list_clear函數對container對象的每個元素進行引用數減量操作並釋放container對象內存。
delete_garbage在對container對象進行clear操作之後,還會檢查是否成功,如果該container對象沒有從unreachable鏈表上摘除,表示container對象還不能銷毀,需要放回到老一“代”中,並標記GC_REACHABLE。
[6] 統計finalizers鏈表數量。
[7] 處理finalizers鏈表的對象。
/* Handle uncollectable garbage (cycles with tp_del slots, and stuff reachable
* only from such cycles).
* If DEBUG_SAVEALL, all objects in finalizers are appended to the module
* garbage list (a Python list), else only the objects in finalizers with
* __del__ methods are appended to garbage. All objects in finalizers are
* merged into the old list regardless.
* Returns 0 if all OK, <0 on error (out of memory to grow the garbage list).
* The finalizers list is made empty on a successful return.
*/
static int
handle_legacy_finalizers(PyGC_Head *finalizers, PyGC_Head *old)
{
PyGC_Head *gc = finalizers->gc.gc_next;
if (_PyRuntime.gc.garbage == NULL) {
_PyRuntime.gc.garbage = PyList_New(0);
if (_PyRuntime.gc.garbage == NULL)
Py_FatalError("gc couldn't create gc.garbage list");
}
for (; gc != finalizers; gc = gc->gc.gc_next) {
PyObject *op = FROM_GC(gc);
if ((_PyRuntime.gc.debug & DEBUG_SAVEALL) || has_legacy_finalizer(op)) {
if (PyList_Append(_PyRuntime.gc.garbage, op) < 0)
return -1;
}
}
gc_list_merge(finalizers, old);
return 0;
}
遍歷finalizers鏈表,將擁有finalizer的實例對象放到一個名為garbage的PyListObject對象中,可以通過gc模塊查看。
>>> import gc
>>> gc.garbage
並把finalizers鏈表晉陞到老一“代”。
注意:__del__給gc帶來的影響, gc模塊唯一處理不了的是循環引用的類都有__del__方法,所以項目中要避免定義__del__方法 官方警告
3.4 小結
-
GC的流程:
-> 發現超過閾值了
-> 觸發垃圾回收
-> 將所有可達對象鏈表放到一起
-> 遍歷, 計算有效引用計數
-> 分成 有效引用計數=0 和 有效引用計數 > 0 兩個集合
-> 大於0的, 放入到更老一代
-> =0的, 執行回收
-> 回收遍歷容器內的各個元素, 減掉對應元素引用計數(破掉循環引用)
-> 執行-1的邏輯, 若發現對象引用計數=0, 觸發內存回收
-> 由python底層內存管理機制回收內存
-
觸發GC的條件
-
主動調用gc.collect(),
-
當gc模塊的計數器達到閥值的時候
-
程序退出的時候
4. GC閾值
分代回收 以空間換時間
重要思想:將系統中的所有內存塊根據其存活的時間劃分為不同的集合, 每個集合就成為一個”代”, 垃圾收集的頻率隨着”代”的存活時間的增大而減小(活得越長的對象, 就越不可能是垃圾, 就應該減少去收集的頻率)
弱代假說
分代垃圾回收算法的核心行為:垃圾回收器會更頻繁的處理新對象。一個新的對象即是你的程序剛剛創建的,而一個來的對象則是經過了幾個時間周期之後仍然存在的對象。Python會在當一個對象從零代移動到一代,或是從一代移動到二代的過程中提升(promote)這個對象。
為什麼要這麼做?這種算法的根源來自於弱代假說(weak generational hypothesis)。這個假說由兩個觀點構成:
首先是年親的對象通常死得也快,而老對象則很有可能存活更長的時間。
假定我們創建了一個Python創建:
n1 = Node("ABC")
根據假說,我的代碼很可能僅僅會使用ABC很短的時間。這個對象也許僅僅只是一個方法中的中間結果,並且隨着方法的返回這個對象就將變成垃圾了。大部分的新對象都是如此般地很快變成垃圾。然而,偶爾程序會創建一些很重要的,存活時間比較長的對象-例如web應用中的session變量或是配置項。
通過頻繁的處理零代鏈表中的新對象,Python的垃圾收集器將把時間花在更有意義的地方:它處理那些很快就可能變成垃圾的新對象。同時只在很少的時候,當滿足閾值的條件,收集器才回去處理那些老變量。
5. Python中的gc模塊使用
gc模塊默認是開啟自動回收垃圾的,gc.isenabled()=True
常用函數:
gc.set_debug(flags) 設置gc的debug日誌,一般設置為gc.DEBUG_LEAK
"""
DEBUG_STATS - 在垃圾收集過程中打印所有統計信息
DEBUG_COLLECTABLE - 打印發現的可收集對象
DEBUG_UNCOLLECTABLE - 打印unreachable對象(除了uncollectable對象)
DEBUG_SAVEALL - 將對象保存到gc.garbage(一個列表)裏面,而不是釋放它
DEBUG_LEAK - 對內存泄漏的程序進行debug (everything but STATS).
"""
-
gc.collect([generation]) 顯式進行垃圾回收,可以輸入參數,0代表只檢查第一代的對象,1代表檢查一,二代的對象,2代表檢查一,二,三代的對象,如果不傳參數,執行一個full collection,也就是等於傳2。 返回不可達(unreachable objects)對象的數目
-
gc.get_threshold() 獲取的gc模塊中自動執行垃圾回收的頻率
-
gc.get_stats()查看每一代的具體信息
-
gc.set_threshold(threshold0[, threshold1[, threshold2]) 設置自動執行垃圾回收的頻率
-
gc.get_count() 獲取當前自動執行垃圾回收的計數器,返回一個長度為3的列表
例如(488,3,0),其中488是指距離上一次一代垃圾檢查,Python分配內存的數目減去釋放內存的數目,注意是內存分配,而不是引用計數的增加。
3是指距離上一次二代垃圾檢查,一代垃圾檢查的次數,同理,0是指距離上一次三代垃圾檢查,二代垃圾檢查的次數。
計數器和閾值關係解釋:
當計數器從(699,3,0)增加到(700,3,0),gc模塊就會執行gc.collect(0),即檢查一代對象的垃圾,並重置計數器為(0,4,0)
當計數器從(699,9,0)增加到(700,9,0),gc模塊就會執行gc.collect(1),即檢查一、二代對象的垃圾,並重置計數器為(0,0,1)
當計數器從(699,9,9)增加到(700,9,9),gc模塊就會執行gc.collect(2),即檢查一、二、三代對象的垃圾,並重置計數器為(0,0,0)
6. 工作中如何避免循環引用?
To avoid circular references in your code, you can use weak references, that are implemented in the weakref module. Unlike the usual references, the weakref.ref doesn’t increase the reference count and returns None if an object was destroyed. rushter
import weakref
class Node():
def __init__(self, value):
self.value = value
self._parent = None
self.children = []
def __repr__(self):
return 'Node({!r:})'.format(self.value)
@property
def parent(self):
return None if self._parent is None else self._parent()
@parent.setter
def parent(self, node):
self._parent = weakref.ref(node)
def add_child(self, child):
self.children.append(child)
child.parent = self
if __name__ == '__main__':
a = Data()
del a
a = Node()
del a
a = Node()
a.add_child(Node())
del a
弱引用消除了引用循環的這個問題,本質來講,弱引用就是一個對象指針,它不會增加它的引用計數
弱引用的主要用途是實現保存大對象的高速緩存或映射,但又並希望大對象僅僅因為它出現在高速緩存或映射中而保持存活
為了訪問弱引用所引用的對象,你可以像函數一樣去調用它即可。如果那個對象還存在就會返回它,否則就返回一個None。 由於原始對象的引用計數沒有增加,那麼就可以去刪除它了
並非所有對象都可以被弱引用;可以被弱引用的對象包括類實例,用 Python(而不是用 C)編寫的函數,實例方法、集合、凍結集合,某些 文件對象,生成器,類型對象,套接字,數組,雙端隊列,正則表達式模式對象以及代碼對象等。
幾個內建類型如 list 和 dict 不直接支持弱引用,但可以通過子類化添加支持:
class Dict(dict):
pass
obj = Dict(red=1, green=2, blue=3) # this object is weak referenceable
其他內置類型例如 tuple 和 int 不支持弱引用,即使通過子類化也不支持
python Cookbook 書中推薦弱引用來處理循環引用
假設我們想創建一個類,用它的實例來代表臨時目錄。 當以下事件中的某一個發生時,這個目錄應當與其內容一起被刪除:
- 對象被作為垃圾回收,
- 對象的
remove() 方法被調用,或
- 程序退出。
原本用__del__()方法
class TempDir:
def __init__(self):
self.name = tempfile.mkdtemp()
def __remove(self):
if self.name is not None:
shutil.rmtree(self.name)
self.name = None
@property
def removed(self):
return self.name is None
def __del__(self):
self.__remove()
更健壯的替代方式可以是定義一個終結器,只引用它所需要的特定函數和對象,而不是獲取對整個對象狀態的訪問權:
class TempDir:
def __init__(self):
self.name = tempfile.mkdtemp()
self._finalizer = weakref.finalize(self, shutil.rmtree, self.name)
def remove(self):
self._finalizer()
@property
def removed(self):
return not self._finalizer.alive
像這樣定義后,我們的終結器將只接受一個對其完成正確清理目錄任務所需細節的引用。 如果對象一直未被作為垃圾回收,終結器仍會在退出時被調用.weakref
參考文章和書籍:
- visualizing garbage collection in ruby and python
- 膜拜的大佬-Junnplus’blog
- wklken前輩
- The Garbage Collector
- Garbage collection in Python: things you need to know
- Python-CookBook-循環引用數據結構的內存管理
- 《python源碼剖析》
- Python-3.8.3/Modules/gcmodule.c
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益