一、jvm垃圾回收要做的事情
- 哪些內存需要回收
- 什麼時候回收
- 怎麼回收
二、如何判斷對象已經死亡,或者說確定為垃圾
- 引用計數法:
給對象中添加一個引用計數器,每當有一個地方引用它時,計數器的值就加1;當引用失效時,計數器值就減1;任何時刻計數器為0的對象就是不可能再被使用的。這也就是需要回收的對象,簡單地說,即一個對象如果沒有任何與之關聯的引用,即他們的引用計數都為 0,則說明對象不太可能再被用到,那麼這個對象就是可回收的對象。
引用計數法是對象記錄自己被多少程序引用,引用計數為零的對象將被清除。
計數器表示的是有多少程序引用了這個對象(被引用數)。計數器是無符號的整數。
- 根搜索算法:
通過一系列成為GC roots的點作為起點,向下搜索,當一個對象到任何GC Roots時沒有引用鏈相連,則說明對象已經死亡。
如果在GC roots和一個對象之間沒有可達路徑(引用鏈),則稱該對象是不可達的。要注意的是,不可達對象不等價於可回收對象,不可達對象變為可回收對象至少要經過兩次標記 過程。兩次標記后仍然是可回收對象,則將面臨回收。
jvm會將以下的對象定義為GC Roots:
- Java虛擬機棧中引用的對象:比如方法裏面定義這種局部變量 User user= new User();
- 方法區中的靜態屬性引用的對象:比如 private static User user = new User();
- 常量引用的對象:比如 private static final User user = new User();
- 本地方法棧(JNI)中引用的對象
三、垃圾回收算法
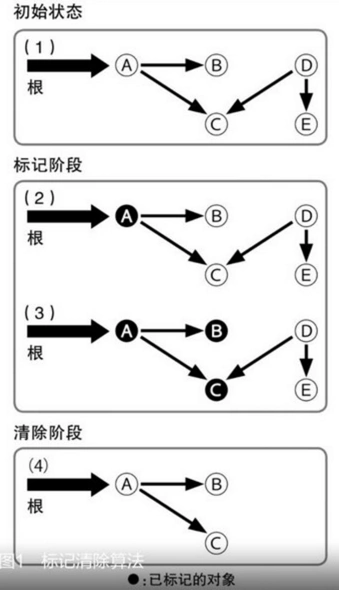
- 標記清除算法(Mark-Sweep)
是最基礎的垃圾回收算法,分為兩個階段,標註和清除。標記階段標記出所有需要回收的對象,清除階段回收被標記的對象所佔用的空間。首先從根開始將可能被引用的對象用遞歸的方式進行標記,然後將沒有標記到的對象作為垃圾進行回收。
從圖中我們就可以發現,該算法最大的問題是內存碎片化嚴重,後續可能發生大對象不能找到可利用空間的問題。
2. 複製算法(copying)
為了解決 Mark-Sweep 算法內存碎片化的缺陷而被提出的算法。按內存容量將內存劃分為等大小 的兩塊。每次只使用其中一塊,當這一塊內存滿后將尚存活的對象複製到另一塊上去,把已使用 的內存清掉,如圖:
這種算法雖然實現簡單,內存效率高,不易產生碎片,但是最大的問題是可用內存被壓縮到了原 本的一半。且存活對象增多的話,Copying 算法的效率會大大降低。
3.標記整理算法(Mark-Compact)
結合了以上兩個算法,為了避免缺陷而提出。標記階段和 Mark-Sweep 算法相同,標記后不是清 理對象,而是將存活對象移向內存的一端。然後清除端邊界外的對象。如圖:
四、分代收集算法
介紹:分代收集法是目前大部分 JVM 所採用的方法,其核心思想是根據對象存活的不同生命周期將內存 劃分為不同的域,一般情況下將 GC 堆劃分為老生代(Tenured/Old Generation)和新生代(Young Generation)。老生代的特點是每次垃圾回收時只有少量對象需要被回收,新生代的特點是每次垃圾回收時都有大量垃圾需要被回收,因此可以根據不同區域選擇不同的算法。
- 新生代與複製算法
目前大部分 JVM 的 GC 對於新生代都採取 Copying 算法,因為新生代中每次垃圾回收都要 回收大部分對象,即要複製的操作比較少,但通常並不是按照 1:1 來劃分新生代。一般將新生代 劃分為一塊較大的 Eden 空間和兩個較小的 Surviror 空間(From Space, To Space),每次使用 Eden 空間和其中的一塊 Survivor 空間,當進行回收時,將該兩塊空間中還存活的對象複製到另 一塊 Survivor 空間中。
假設from space為s0,to space 為s1
算法過程:
- Eden+S0可分配新生對象;
- 對Eden+S0進行垃圾收集,存活對象複製到S1。清理Eden+S0。一次新生代GC結束。
- Eden+S1可分配新生對象;
- 對Eden+S1進行垃圾收集,存活對象複製到S0。清理Eden+S1。二次新生代GC結束。
- 循環1。
2.老年代與標記整理算法
老年代因為每次只回收少量對象,因而採用 Mark-Compact 算法。
1. JAVA 虛擬機提到過的處於方法區的永生代(Permanet Generation),它用來存儲 class 類, 常量,方法描述等。對永生代的回收主要包括廢棄常量和無用的類。
2. 對象的內存分配主要在新生代的 Eden Space 和 Survivor Space 的 From Space(Survivor 目 前存放對象的那一塊),少數情況會直接分配到老生代。
3. 當新生代的 Eden Space 和 From Space 空間不足時就會發生一次 GC,進行 GC 后,Eden Space 和 From Space 區的存活對象會被挪到 To Space,然後將 Eden Space 和 From Space 進行清理。
4. 如果 To Space 無法足夠存儲某個對象,則將這個對象存儲到老生代。
5. 在進行 GC 后,使用的便是 Eden Space 和 To Space 了,如此反覆循環。
6. 當對象在 Survivor 區躲過一次 GC 后,其年齡就會+1。默認情況下年齡到達 15 的對象會被 移到老生代中。
五、分區收集算法
分區算法則將整個堆空間劃分為連續的不同小區間, 每個小區間獨立使用, 獨立回收. 這樣做的 好處是可以控制一次回收多少個小區間 , 根據目標停頓時間, 每次合理地回收若干個小區間(而不是 整個堆), 從而減少一次 GC 所產生的停頓。
六、java中的四種引用
- 強引用
在 Java 中最常見的就是強引用,把一個對象賦給一個引用變量,這個引用變量就是一個強引 用。當一個對象被強引用變量引用時,它處於可達狀態,它是不可能被垃圾回收機制回收的,即 使該對象以後永遠都不會被用到 JVM 也不會回收。因此強引用是造成 Java 內存泄漏的主要原因之一,直接new的對象就是強引用的。
- 軟引用
軟引用需要用 SoftReference 類來實現,對於只有軟引用的對象來說,當系統內存足夠時它 不會被回收,當系統內存空間不足時它會被回收。軟引用通常用在對內存敏感的程序中。
- 弱引用
弱引用需要用 WeakReference 類來實現,它比軟引用的生存期更短,對於只有弱引用的對象 來說,只要垃圾回收機制一運行,不管 JVM 的內存空間是否足夠,總會回收該對象佔用的內存。
- 虛引用
虛引用需要 PhantomReference 類來實現,它不能單獨使用,必須和引用隊列聯合使用。虛 引用的主要作用是跟蹤對象被垃圾回收的狀態。
七、GC 垃圾收集器
Java 堆內存被劃分為新生代和年老代兩部分,新生代主要使用複製和標記-清除垃圾回收算法; 年老代主要使用標記-整理垃圾回收算法,因此 java 虛擬中針對新生代和年老代分別提供了多種不 同的垃圾收集器,JDK1.6 中 Sun HotSpot 虛擬機的垃圾收集器如下:
新生代:
- Serial 垃圾收集器(單線程、複製算法)
Serial(英文連續)是最基本垃圾收集器,使用複製算法,曾經是JDK1.3.1 之前新生代唯一的垃圾 收集器。Serial 是一個單線程的收集器,它不但只會使用一個 CPU 或一條線程去完成垃圾收集工 作,並且在進行垃圾收集的同時,必須暫停其他所有的工作線程,直到垃圾收集結束。 Serial 垃圾收集器雖然在收集垃圾過程中需要暫停所有其他的工作線程,但是它簡單高效,對於限 定單個 CPU 環境來說,沒有線程交互的開銷,可以獲得最高的單線程垃圾收集效率,因此 Serial 垃圾收集器依然是 java 虛擬機運行在 Client 模式下默認的新生代垃圾收集器。
2.ParNew 垃圾收集器(Serial+多線程)
ParNew 垃圾收集器其實是 Serial 收集器的多線程版本,也使用複製算法,除了使用多線程進行垃 圾收集之外,其餘的行為和 Serial 收集器完全一樣,ParNew 垃圾收集器在垃圾收集過程中同樣也 要暫停所有其他的工作線程。 ParNew 收集器默認開啟和 CPU 數目相同的線程數,可以通過-XX:ParallelGCThreads 參數來限 制垃圾收集器的線程數。ParNew雖然是除了多線程外和Serial 收集器幾乎完全一樣,但是ParNew垃圾收集器是很多 java 虛擬機運行在 Server 模式下新生代的默認垃圾收集器。
3.Parallel Scavenge 收集器(多線程複製算法、高效)
Parallel Scavenge 收集器也是一個新生代垃圾收集器,同樣使用複製算法,也是一個多線程的垃 圾收集器,它重點關注的是程序達到一個可控制的吞吐量(Thoughput,CPU 用於運行用戶代碼 的時間/CPU 總消耗時間,即吞吐量=運行用戶代碼時間/(運行用戶代碼時間+垃圾收集時間)), 高吞吐量可以最高效率地利用 CPU 時間,儘快地完成程序的運算任務,主要適用於在後台運算而 不需要太多交互的任務。自適應調節策略也是 ParallelScavenge 收集器與 ParNew 收集器的一個 重要區別。
老年代:
4.Serial Old 收集器(單線程標記整理算法 )
Serial Old 是 Serial 垃圾收集器年老代版本,它同樣是個單線程的收集器,使用標記-整理算法, 這個收集器也主要是運行在 Client 默認的 java 虛擬機默認的年老代垃圾收集器。 在 Server 模式下,主要有兩個用途:
1. 在 JDK1.5 之前版本中與新生代的 Parallel Scavenge 收集器搭配使用。
2. 作為年老代中使用 CMS 收集器的後備垃圾收集方案。
新生代 Parallel Scavenge 收集器與 ParNew 收集器工作原理類似,都是多線程的收集器,都使 用的是複製算法,在垃圾收集過程中都需要暫停所有的工作線程。
5.Parallel Old 收集器(多線程標記整理算法)
Parallel Old 收集器是Parallel Scavenge的年老代版本,使用多線程的標記-整理算法,在 JDK1.6 才開始提供。 在 JDK1.6 之前,新生代使用 ParallelScavenge 收集器只能搭配年老代的 Serial Old 收集器,只 能保證新生代的吞吐量優先,無法保證整體的吞吐量,Parallel Old 正是為了在年老代同樣提供吞 吐量優先的垃圾收集器,如果系統對吞吐量要求比較高,可以優先考慮新生代 Parallel Scavenge 和年老代 Parallel Old 收集器的搭配策略。
6.Parallel Old 收集器(多線程標記整理算法)
Parallel Old 收集器是Parallel Scavenge的年老代版本,使用多線程的標記-整理算法,在 JDK1.6 才開始提供。 在 JDK1.6 之前,新生代使用 ParallelScavenge 收集器只能搭配年老代的 Serial Old 收集器,只 能保證新生代的吞吐量優先,無法保證整體的吞吐量,Parallel Old 正是為了在年老代同樣提供吞 吐量優先的垃圾收集器,如果系統對吞吐量要求比較高,可以優先考慮新生代 Parallel Scavenge 和年老代 Parallel Old 收集器的搭配策略。
7.CMS 收集器(多線程標記清除算法)
Concurrent mark sweep(CMS)收集器是一種年老代垃圾收集器,其最主要目標是獲取最短垃圾 回收停頓時間,和其他年老代使用標記-整理算法不同,它使用多線程的標記-清除算法。 最短的垃圾收集停頓時間可以為交互比較高的程序提高用戶體驗。
8.G1 收集器
Garbage first 垃圾收集器是目前垃圾收集器理論發展的最前沿成果,相比與 CMS 收集器,G1 收 集器兩個最突出的改進是:
1. 基於標記-整理算法,不產生內存碎片。
2. 可以非常精確控制停頓時間,在不犧牲吞吐量前提下,實現低停頓垃圾回收。 G1 收集器避免全區域垃圾收集,它把堆內存劃分為大小固定的幾個獨立區域,並且跟蹤這些區域 的垃圾收集進度,同時在後台維護一個優先級列表,每次根據所允許的收集時間,優先回收垃圾 最多的區域。區域劃分和優先級區域回收機制,確保 G1 收集器可以在有限時間獲得最高的垃圾收 集效率。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案