本文是我有通俗的語言寫的如果有誤請指出。
先看bufio官方文檔
https://studygolang.com/pkgdoc文檔地址
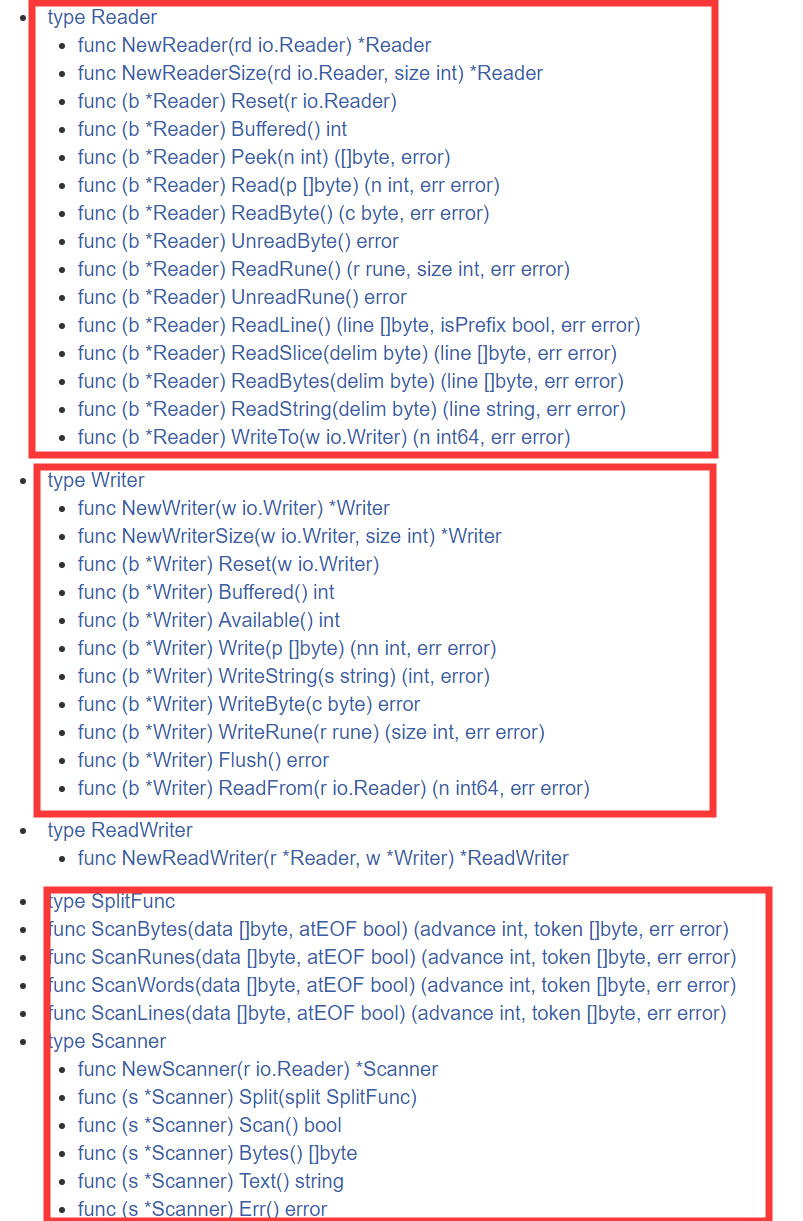
主要分三部分Reader、Writer、Scanner
分別是讀數據、寫數據和掃描器三種數據類型的相關操作 這個掃描後面會詳細說我開始也沒弄明白其實很簡單。
Reader
func
func NewReaderSize(rd ., size ) *
NewReaderSize創建一個具有最少有size尺寸的緩衝、從r讀取的*Reader。如果參數r已經是一個具有足夠大緩衝的* Reader類型值,會返回r。
解釋:看官方解釋這個方法可能不太容易懂,這個意思就是就是你可以給*Reader自定義一個size大小的緩衝區,*Reader每次從底層io.Reader(也就是你那個文件或者流)中預讀size大小的數據到緩衝區中(可能讀不滿),然後你每次讀數據實際是從這個緩衝區中拿數據。
下面是NewReaderSize源碼
func NewReaderSize(rd io.Reader, size int) *Reader {
// Is it already a Reader?
b, ok := rd.(*Reader)
if ok && len(b.buf) >= size {
return b
}
if size < minReadBufferSize { //minReadBufferSize==16
size = minReadBufferSize
}
r := new(Reader)
r.reset(make([]byte, size), rd)
return r
}
r.reset 初始化了一個*Reader 返回大小是size。
func
func NewReader(rd .) *
NewReader創建一個具有默認大小緩衝、從r讀取的*Reader。
解釋:那這個NewReader就很好解釋了 和NewReaderSize基本一樣就是緩衝區大小是默認設置好的
func (*Reader)
func (b *) Peek(n ) ([], )
解釋:Peek就是返回緩存的一個切片,該切片引用緩存中的前N個字節的數據,如果n大於總大小,則返回能讀到的字節數的數據。
func (*Reader)
func (b *) Read(p []) (n , err )
Read讀取數據寫入p。本方法返回寫入p的字節數。本方法一次調用最多會調用下層Reader接口一次Read方法,因此返回值n可能小於len(p)。讀取到達結尾時,返回值n將為0而err將為io.EOF。
解釋:如果緩存不為空則直接從緩存中讀數據不會從底層io.Reader讀,如果緩存為空len(p)>緩存大小,則直接從底層io.Reader讀數據到p。
如果len(p)<緩存大小,則先從底層io.Reader中讀數據到緩存再到p。
主要就這幾個 還有幾個文檔寫的都很清楚易懂我就不多寫了。
Writer類型的方法和Reader類型的方法差不多也很易懂主要就一個Flush要注意。
func (*Writer)
func (b *) Flush()
Flush方法將緩衝中的數據寫入下層的io.Writer接口。
和Reader是倒過來的,Writer每次寫數據是先寫入緩衝區的,進程緩衝區填滿后,通過進程緩衝寫入到內核緩衝再寫入到磁盤,使用Flush就不等填滿直接走寫入流程了,保證你的數據及時寫入文件。
解釋:scanner類型掃描器 官方的說法很複雜,我也沒太看懂找了很多資料,其實就是你在數據傳輸的時候時候使用“分隔符”,scanner類型可以通過分隔符逐個迭代你的數據。
上面4個函數func Scan…… 就是分隔符的判斷函數這4個是給你預設好的,你也可以按照自己的需求改寫。
怎麼改寫呢,看下面
func (*Scanner)
func (s *) Split(split )
這個Split方法就是設置你這個scanner的用哪個SplitFunc類型的函數
在看下面這個SpliFunc類型的函數簽名
type SplitFunc func(data [], atEOF ) (advance , token [], err )
照着這個格式寫一個不就得了么,當然具體寫法給出了但是你不會?沒關係咱看一下官方是咋寫的。
https://github.com/golang/go/blob/master/src/bufio/scan.go?name=release#57官方源碼地址
func ScanLines(data []byte, atEOF bool) (advance int, token []byte, err error) {
if atEOF && len(data) == 0 {
return 0, nil, nil
}
if i := bytes.IndexByte(data, '\n'); i >= 0 {
// We have a full newline-terminated line.
return i + 1, dropCR(data[0:i]), nil
}
// If we're at EOF, we have a final, non-terminated line. Return it.
if atEOF {
return len(data), dropCR(data), nil
}
// Request more data.
return 0, nil, nil
}
看bytes.IndexByte(data, ‘\n’);這段不就是在找行尾嘛 比如你想改成以“;”為分隔符的就改成bytes.IndexByte(data, ‘;’);不就得了么
func main(){
scanner:=bufio.NewScanner(
strings.NewReader("abcdefg\nhigklmn"),
)
scanner.Split(ScanLines) //這裏可以隨意選擇用哪個函數也可以自定義,可以不指定默認為\n做分隔符
for scanner.Scan(){
fmt.Println(scanner.Text())
}
}
到此為止拉~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!