本文始發於個人公眾號:TechFlow,原創不易,求個關注
今天是Numpy專題的第5篇文章,我們來繼續學習Numpy當中一些常用的數學和統計函數。
基本統計方法
在日常的工作當中,我們經常需要通過一系列值來了解特徵的分佈情況。比較常用的有均值、方差、標準差、百分位數等等。前面幾個都比較好理解,簡單介紹一下這個百分位數,它是指將元素從小到大排列之後,排在第x%位上的值。我們一般常用的是25%,50%和75%這三個值,通過這幾個值,我們很容易對於整個特徵的分佈有一個大概的了解。
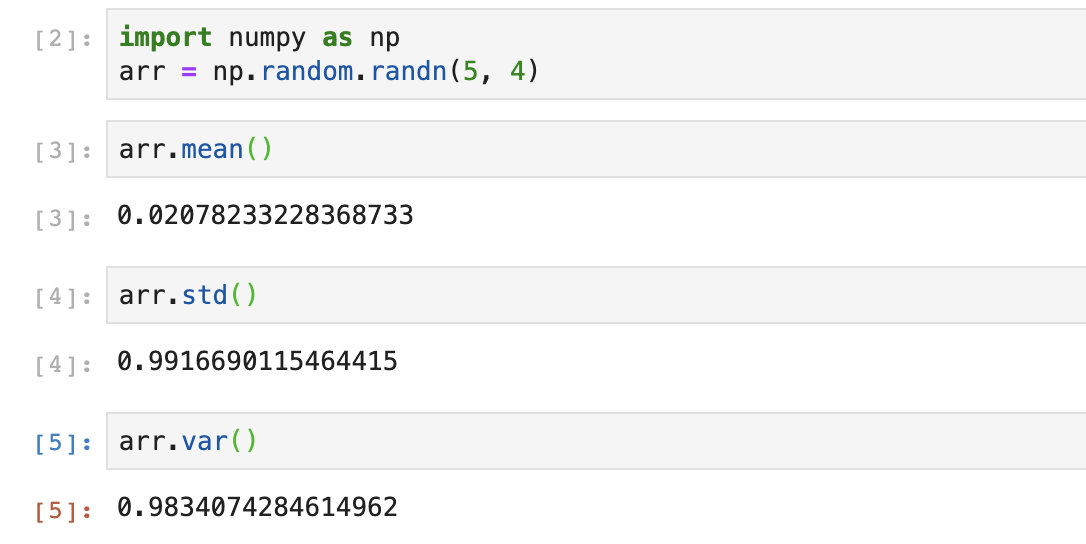
前面三個指標:均值、方差、標準差都很好理解,我們直接看代碼就行。
median和percentile分別是求中位數與百分位數,它們不是Numpy當中array的函數,而是numpy的庫函數。所以我們需要把array當做參數傳入。percentile這個函數還需要額外傳入一個int,表示我們想要得到的百分位數,比如我們想要知道50%位置上的數,則輸入50。
除了這些之外,我們還會經常用到sum,min,max,argmin,argmax這幾個函數。sum,min,max很好理解,argmin和argmax的意思是獲取最小值和最大值的索引。
這裏返回的索引有點奇怪,和我們想的不同,居然不是一個二維的索引而是一維的。實際上numpy的內部會將高維數組轉化成一維之後再進行這個操作,我們可以reshape一下數組來進行驗證:
這些只是api的基本用法,numpy當中支持的功能不僅如此。我們觀察一下這些函數會發現,它們的作用域都是一組數據,返回的是一組數據通過某種運算得到的結果。舉個例子,比如sum,是對一組數據的價格。std計算的是一組數據的標準差,這樣的函數我們稱為聚合函數。
numpy當中的聚合函數在使用的時候允許傳入軸這個參數,限制它聚合的範圍。我們通過axis這個參數來控制,axis=0表示對列聚合,axis=1表示對行聚合。我們死記的話總是會搞混淆,實際上axis傳入的也是一個索引,表示第幾個索引的索引。我們的二維數組的shape是[行, 列],其中的第0位是行,第1位是列,可以認為axis是這個索引向量的一個索引。
我們可以來驗證一下:
可以看到axis=0和axis=1返回的向量的長度是不同的,因為以列為單位聚合只有4列,所以得到的是一個1 x 4的結果。而以行為單位聚合有5行,所以是一個1 x 5的向量。
除了上面介紹的這些函數之外,還有cumsum和cumprod這兩個api。其中cumsum是用來對數組進行累加運算,而cumprod是進行的累乘運算。只是在實際工作當中,很少用到,我就不展開細講了,感興趣的同學可以查閱api文檔了解一下。
bool數組的方法
我們之前在Python的入門文章當中曾經提到過,在Python中True和False完全等價於1和0。那麼在上面這些計算的方法當中,如果存在bool類型的值,都會被轉化成1和0進行的計算。
我們靈活運用這點會非常方便,舉個例子,假設我們要統計一批數據當中有多少條大於0。我們利用sum會非常方便:
bool數組除了可以應用上面這些基本的運算api之外,還有專門的兩個api,也非常方便。一個叫做any,一個叫做all。any的意思是只要數組當中有一個是True,那麼結果就是True。可以認為是Is there any True in the array的意思,同樣,all就是說只有數組當中都是True,結果才是True。對應的英文自然是Are the values in the array all True。
這個只要理解了,基本上很難忘記。
排序
Python原生的數組可以排序,numpy當中的數組自然也不例外。我們只需要調用sort方法就可以排序了,不過有一點需要注意,numpy中的sort默認是一個inplace的方法。也就是說我們調用完了sort之後,原數組的值就自動變化了。
如果寫成了arr = arr.sort()會得到一個None,千萬要注意。
同樣,我們也可以通過傳入軸這個參數來控制它的排序範圍,可以做到對每一列排序或者是對每一行排序,我們來看個例子:
這個是對列排序,如果傳入0則是對行排序,這個應該不難理解。
集合api
numpy當中還提供了一些面向集合的api,相比於針對各種計算的api,這些方法用到的情況比較少。常用的一般只有unique和in1d。
unique顧名思義就是去重的api,可以返回一維array去重且排序之後的結果。我們來看個例子:
它等價於:
set(sorted(arr))
in1d是用來判斷集合內的元素是否在另外一個集合當中,函數會返回一個bool型的數組。我們也可以來看個例子:
除了這兩個api之外,還有像是計算並集並排序的union1d,計算差集的setdiff1d,計算兩個集合交集並排序的intersect1d等等。這些api的使用頻率實在是不高,所以就不贅述了。用到的時候再去查閱即可。
總結
今天我們聊了numpy當中很多常用的計算api,這些api在我們日常做機器學習和數據分析的時候經常用到。比如分析特徵分佈的時候,如果數據量很大是不適合作圖或者是可視化觀察的。這個時候可以從中位數、均值、方差和幾個關鍵百分位點入手,再比如在我們使用softmax多分類的時候,也會用到argmax來獲取分類的結果。
總之,今天的內容非常關鍵,在numpy整體的應用當中佔比很高,希望大家都能熟悉它們的基本用法。這樣即使以後忘記,用到的時候再查閱也還來得及。
今天的文章就是這些,如果喜歡本文,可以的話請點個關注,給我一點鼓勵,也方便獲取更多文章。
本文使用 mdnice 排版
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?