大數據篇:一文讀懂@數據倉庫
1 網絡詞彙總結
- 人工智能層的:智慧地球、智慧城市、智慧社會
- 企業層面的:数字互聯網,数字經濟、数字平台、数字城市、数字政府;
- 平台層面的:物聯網,雲計算,大數據,5G,人工智能,機器智能,深度學習,知識圖譜
- 技術層面的:數據倉庫、數據集市、大數據平台、數據湖、數據中台、業務中台、技術中台等等
挑重點簡介
1.1 數據中台
-
數據中台是聚合和治理跨域數據,將數據抽象封裝成服務,提供給前台以業務價值的邏輯概念。
-
數據中台是一套可持續“讓企業的數據用起來”的機制,一種戰略選擇和組織形式,是依據企業特有的業務模式和組織架構,通過有形的產品和實施方法論支撐,構建一套持續不斷把數據變成資產並服務於業務的機制。
-
數據中台連接數據前台和後台,突破數據局限,為企業提供更靈活、高效、低成本的數據分析挖掘服務,避免企業為滿足具體某部門某種數據分析需求而投放大量高成本、重複性的數據開發成本。
-
數據中台是指通過數據技術,對海量數據進行採集、計算、存儲、加工,同時統一標準和口徑。數據中台把數據統一之後,會形成標準數據,再進行存儲,形成大數據資產層,進而為客戶提供高效服務。
-
數據中台,包括平台、工具、數據、組織、流程、規範等一切與企業數據資產如何用起來所相關的。
可以看出,數據中台是解決如何用好數據的問題,目前還缺乏一個標準,而說到數據中台一定會提及大數據,而大數據又是由數據倉庫發展起來的。
1.1.1 數據倉庫(Data WareHouse)
- 數據倉庫,按照傳統的定義,數據倉庫是一個面向主題的、集成的、非易失的、反映歷史變化(隨時間變化),用來支持管理人員決策的數據集合。
為企業所有決策制定過程,提供所有系統數據支持的戰略集合
- 面向主題
操作型數據庫的數據組織面向事務處理任務,各個業務系統之間各自分離,而數據倉庫中的數據是按照一定的主題域進行組織。
主題是一個抽象的概念,是數據歸類的標準,是指用戶使用數據倉庫進行決策時所關心的重點方面,一個主題通常與多個操作型信息系統相關。每一個主題基本對應一個宏觀的分析領域。
例如,銀行的數據倉庫的主題:客戶
客戶數據來源:從銀行儲蓄數據庫、信用卡數據庫、貸款數據庫等幾個數據庫中抽取的數據整理而成。這些客戶信息有可能是一致的,也可能是不一致的,這些信息需要統一整合才能完整體現客戶。
- 集成
面向事務處理的操作型數據庫通常與某些特定的應用相關,數據庫之間相互獨立,並且往往是異構的。而數據倉庫中的數據是在對原有分散的數據庫數據抽取、清理的基礎上經過系統加工、匯總和整理得到的,必須消除源數據中的不一致性,以保證數據倉庫內的信息是關於整個企業的一致的全局信息。
具體如下:
1:數據進入數據倉庫后、使用之前,必須經過加工與集成。
2:對不同的數據來源進行統一數據結構和編碼。統一原始數 據中的所有矛盾之處,如字段的同名異義,異名同義,單位不統一,字長不一致等。
3:將原始數據結構做一個從面嚮應用到面向主題的大轉變。
- 非易失即相對穩定的
操作型數據庫中的數據通常實時更新,數據根據需要及時發生變化。數據倉庫的數據主要供企業決策分析之用,所涉及的數據操作主要是數據查詢,一旦某個數據進入數據倉庫以後,一般情況下將被長期保留,也就是數據倉庫中一般有大量的查詢操作,但修改和刪除操作很少,通常只需要定期的加載、刷新。
數據倉庫中包括了大量的歷史數據。
數據經集成進入數據倉庫后是極少或根本不更新的。
- 隨時間變化即反映歷史變化
操作型數據庫主要關心當前某一個時間段內的數據,而數據倉庫中的數據通常包含歷史信息,系統記錄了企業從過去某一時點(如開始應用數據倉庫的時點)到目前的各個階段的信息,通過這些信息,可以對企業的發展歷程和未來趨勢做出定量分析和預測。企業數據倉庫的建設,是以現有企業業務系統和大量業務數據的積累為基礎。數據倉庫不是靜態的概念,只有把信息及時交給需要這些信息的使用者,供他們做出改善其業務經營的決策,信息才能發揮作用,信息才有意義。而把信息加以整理歸納和重組,並及時提供給相應的管理決策人員,是數據倉庫的根本任務。因此,從產業界的角度看,數據倉庫建設是一個工程,是一個過程
數據倉庫內的數據時限一般在5-10年以上,甚至永不刪除,這些數據的鍵碼都包含時間項,標明數據的歷史時期,方便做時間趨勢分析。
- 數據倉庫,並不是數據最終目的地,而是為數據最終的目的地做好準備:清洗、轉義、分類、重組、合併、拆分、統計等等
通過對數據倉庫中數據的分析,可以幫助企業,改進業務流程、控制、成本、提高產品質量等
- 主要解決問題:數據報表,數據沉澱,數據計算Join過多,數據查詢過慢等問題。
防止煙囪式開發,減少重複開發,開發通用中間層數據,減少重複計算;
將複雜問題簡單化,將複雜任務的多個步驟分解到各個層次中,每一層只處理較少的步驟,使單個任務更容易理解;
可進行數據血緣追蹤,便於快速定位問題;
整個數據層次清晰,每個層次的數據都有職責定位,便於使用和理解。
- 主要價值體現:企業數據模型,這些模型隨着前端業務系統的發展變化,不斷變革,不斷追加,不斷豐富和完善,即使系統不再了,也可以在短期內快速重建起來,這也是大數據產品能夠快速迭代起來的一個重要原因
總結:數據倉庫,即為企業數據的模型沉澱,為了能更快的發展大數據應用,提供可靠的模型來快速迭代。本文也主要為了講解數據倉庫
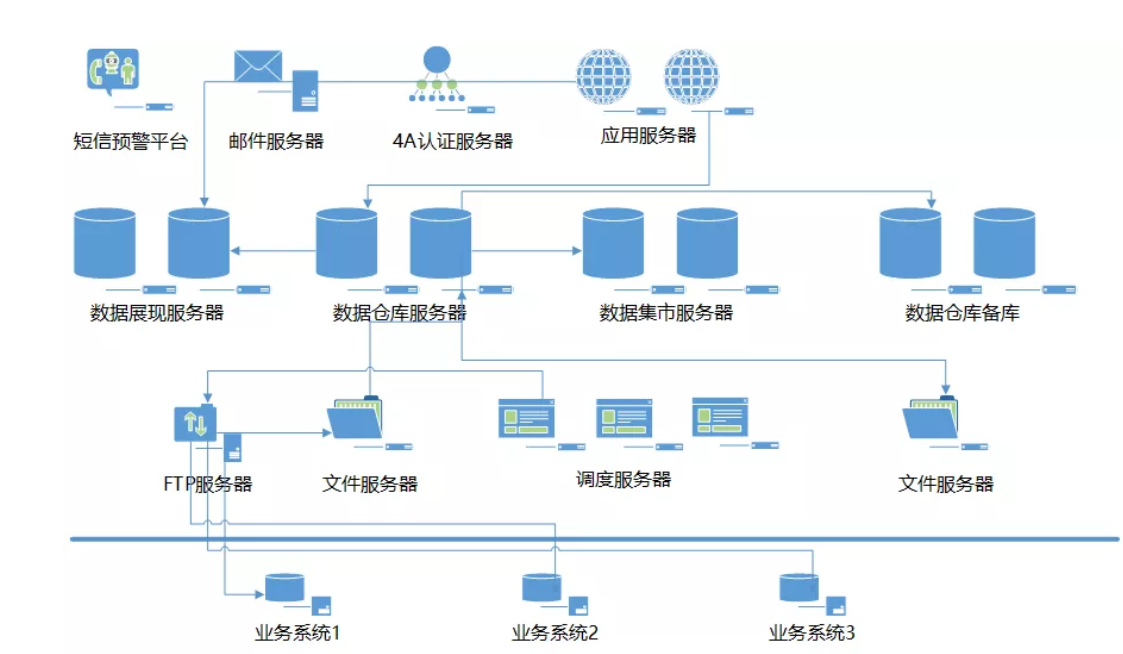
- 數倉硬件架構圖
- 數倉功能架構圖
- 數倉流程架構圖1
- 數倉流程架構圖2
- 實時數倉流程架構圖
1.1.2 大數據平台(DATA Platform)
-
大數據平台則是指以處理海量數據存儲、計算及流數據實時計算等場景為主的一套基礎設施,包括了統一的數據採集中心、數據計算和存儲中心、數據治理中心、運維管控中心、開放共享中心和應用中心。
-
大數據平台的建設出發點是節約投資降低成本,但實際上無論從硬件投資還是從軟件開發上都遠遠超過數據倉庫的建設,大量的硬件和各種開源技術的組合,增加了研發的難度、調測部署的周期、運維的複雜度,人力上的投入已是最初的幾倍;還有很多技術上的困難也非一朝一夕能夠突破。
-
首先是數據的應用問題,無論是數據倉庫還是大數據平台,裡面包含了接口層數據、存儲層數據、輕度匯總層、重度匯總層、模型層數據、報表層數據等等,各種各樣的表有成千上萬,這些表有的是中間處理過程,有些是一次性的報表,不同表之間的數據一致性和口徑也會不同,而且不同的表不同的字段對數據安全要求級別也不同。
-
此外還要考慮多租戶的資源安全管理,如何讓內部開發者快速獲取所需的數據資產目錄,如何閱讀相關數據的來龍去脈,如何快速的實現開發,這些在大數據平台建設初期沒有考慮周全。
-
另外一個問題是對外應用,隨着大數據平台的應用建設,每一個對外應用都採用單一的數據庫加單一應用建設模式,獨立考慮網絡安全、數據安全、共享安全,逐漸又走向了煙囪似的開發道路。
總結:大數據平台,即為數據一站式服務,提供可視化的數據展示,提取,計算任務安排,資源管理,數據治理,安全措施,共享應用等等。
- 平台數據流向圖
- 平台流程架構圖
1.1.3 數據中台(Data Middle Platform)
-
數據中台要解決什麼?數據如何安全的、快速的、最小權限的、且能夠溯源的被探測和快速應用的問題。
-
數據中台不應該被過度的承載平台的計算、存儲、加工任務,而是應該放在解決企業邏輯模型的搭建和存儲、數據標準的建立、數據目錄的梳理、數據安全的界定、數據資產的開放,知識圖譜的構建。
-
通過一系列工具、組織、流程、規範,實現數據前台和後台的連接,突破數據局限,為企業提供更靈活、高效、低成本的數據分析挖掘服務,避免企業為滿足具體某部門某種數據分析需求而投放大量高成本、重複性的數據開發成本。
總結:厚平台,大中台,小前台;沒有基礎厚實笨重的大數據平台,是不可能構建數據能力強大、功能強大的數據中台的;沒有大數據中台,要迅速搭建小快靈的小前台也只是理想化的。
- 中台架構圖
- 阿里數據中台架構圖
2 數據庫的”分家”
隨着關係數據庫理論的提出,誕生了一系列經典的RDBMS,如Oracle,MySQL,SQL Server等。這些RDBMS被成功推向市場,併為社會信息化的發展做出的重大貢獻。然而隨着數據庫使用範圍的不斷擴大,它被逐步劃分為兩大基本類型:
- 操作型數據庫(OLTP)
主要用於業務支撐。一個公司往往會使用並維護若干個數據庫,這些數據庫保存着公司的日常操作數據,比如商品購買、酒店預訂、打車下單、外賣訂購等;
- 分析型數據庫(OLAP)
主要用於歷史數據分析。這類數據庫作為公司的單獨數據存儲,負責利用歷史數據對公司各主題域進行統計分析;
- 總結
那麼為什麼要”分家”?在一起不合適嗎?能不能構建一個同樣適用於操作和分析的統一數據庫?
答案是NO。一個顯然的原因是它們會”打架”……如果操作型任務和分析型任務搶資源怎麼辦呢?再者,它們有太多不同,以致於早已”貌合神離”。接下來看看它們到底有哪些不同吧。
因為主導功能的不同(面向操作/面向分析),兩類數據庫就產生了很多細節上的差異。就好像玩LOL一个中單一個ADC,肯定有很多行為/觀念上的不同
2.1 OLAP 和 OLTP簡介
數據處理大致可以分成兩大類:
聯機事務處理OLTP(on-line transaction processing):是傳統的關係型數據庫的主要應用,主要是基本的、日常的事務處理,例如銀行交易。系統強調數據庫內存效率,強調內存各種指標的命令率,強調綁定變量,強調併發操作。
聯機分析處理OLAP(On-Line Analytical Processing):是數據倉庫系統的主要應用,支持複雜的分析操作,側重決策支持,並且提供直觀易懂的查詢結果。 系統則強調數據分析,強調SQL執行市場,強調磁盤I/O,強調分區等。
2.2 定義差別
| 對比內容 | 操作型數據庫(OLTP) | 分析型數據庫(OLAP) |
|---|---|---|
| 數據內容 | 當前值 | 歷史的、存檔的、歸納的、計算的數據 |
| 數據目標 | 面向業務操作程序,重複處理 | 面向主題域,分析應用,支持決策 |
| 數據特性 | 動態變化,按字段更新 | 靜態、不能直接更新,只能定時添加、刷新 |
| 數據結構 | 高度結構化、複雜,適合操作計算 | 簡單,適合分析 |
| 使用頻率 | 高 | 中到低 |
| 數據訪問量 | 每個事務只訪問少量記錄 | 有的事務可能需要訪問大量記錄 |
| 對響應時間的要求 | 以秒為單位計算 | 以秒、分鐘、甚至小時為計算單位 |
2.3 定位差別
| 對比屬性 | OLTP | OLAP |
|---|---|---|
| 代表 | Mysql | Hive |
| 讀特性 | 每次查詢只返回少量數據 | 對大量數據進行匯總 |
| 寫特性 | 隨機、低延遲寫入用戶的操作 | 批量導入 |
| 用戶 | 操作人員 | 決策人員 |
| DB設計 | 面嚮應用 | 面向主題 |
| 數據 | 當前的,最新的細節,二維表 | 歷史的,聚集的,多維表 |
| 工作單位 | 事務性保證 | 複雜查詢 |
| 用戶數 | 上千個 | 上百萬個 |
| DB大小 | 100MB-GB | 100GB-TB以上 |
| 時間要求 | 具有實時性 | 對時間的要求不嚴格 |
| 主要應用 | 數據庫:WEB項目 | 數據倉庫:分析師,挖掘師 |
2.4 組成差別
| 對比內容 | 操作型數據庫(OLTP) | 分析型數據庫(OLAP) |
|---|---|---|
| 數據時間範圍差別 | 只會存放一定天數的數據 | 存放的則是數年內的數據 |
| 數據細節層次差別 | 存放的主要是細節數據 也有匯總需求,但匯總數據本身不存儲而只存儲其生成公式。 這是因為操作型數據是動態變化的,因此匯總數據會在每次查詢時動態生成。 |
存放的既有細節數據,又有匯總數據,對於用戶來說,重點關注的是匯總數據部分。 因為匯總數據比較穩定不會發生改變,而且其計算量也比較大(因為時間跨度大),因此它的匯總數據可考慮事先計算好,以避免重複計算。 |
| 數據時間表示差別 | 通常反映的是現實世界的當前狀態 | 既有當前狀態,還有過去各時刻的快照。 可以綜合所有快照對各個歷史階段進行統計分析 |
2.5 技術差別
| 對比內容 | 操作型數據庫(OLTP) | 分析型數據庫(OLAP) |
|---|---|---|
| 數據更新差別 | 允許用戶進行增,刪,改,查 | 規範是只能進行查詢 |
| 數據冗餘差別 | 減少數據冗餘,避免更新異常 | 沒有更新操作。因此,減少數據冗餘也就沒那麼重要了 |
2.6 功能差別
| 對比內容 | 操作型數據庫(OLTP) | 分析型數據庫(OLAP) |
|---|---|---|
| 數據讀者差別 | 使用者是業務環境內的各個角色,如用戶,商家,進貨商等 | 只被少量用戶(高級管理者)用來做綜合性決策 |
| 數據定位差別 | 是為了支撐具體業務創建的,因此也被稱為”面嚮應用型數據庫” | 是針對各特定業務主題域的分析任務創建的,因此也被稱為”面向主題型數據庫” |
2.7 OLTP數據庫三範式介紹
- 定義:範式可以理解為設計一張數據表的表結構,符合的標準級別。 規範和要求
- 優點:關係型數據庫設計時,遵照一定的規範要求,目的在於降低數據的冗餘性。
- 十幾年前,磁盤很貴,為了減少磁盤存儲。
- 以前沒有分佈式系統,都是單機,只能增加磁盤,磁盤個數也是有限的
- 一次修改,需要修改多個表,很難保證數據一致性
- 缺點:範式的缺點是獲取數據時,需要通過 Join 拼接出最後的數據。
目前業界範式有:第一範式(1NF)、第二範式(2NF)、第三範式(3NF)、巴斯-科德範式 (BCNF)、第四範式(4NF)、第五範式(5NF)。
2.7.1 函數依賴
| 學號 | 姓名 | 系名 | 班主任 | 課名 | 分數 |
|---|---|---|---|---|---|
| 001 | 張三 | 古文系 | 李白 | 文言文 | 89 |
| 001 | 張三 | 古文系 | 李白 | 古詩詞 | 78 |
| 001 | 張三 | 古文系 | 李白 | 現代漢語 | 65 |
| 002 | 李四 | 古文系 | 李白 | 文言文 | 45 |
| 002 | 李四 | 古文系 | 李白 | 古詩詞 | 78 |
| 002 | 李四 | 古文系 | 李白 | 甲骨文 | 98 |
| 003 | 王五 | 數學系 | 牛頓 | 高等數學 | 88 |
| 003 | 王五 | 數學系 | 牛頓 | 數學基礎 | 88 |
- 完全函數依賴:
通過 AB 能推出 C,但是 AB 單獨得不到 C,那麼可以說:C 完全依賴於 AB
(學號,課名)推出 分數,但是 單獨用學號 推不出 分數,那麼可以說:分數 完全依賴於(學號,課名)
- 部分函數依賴:
通過 AB 能推出 C,通過 單獨的A 或者 單獨的B 也能推出 C,那麼可以說:C 部分依賴於 AB
(學號,課名)推出 姓名,而還可以通過 學號 直接推出 姓名,那麼可以說:姓名 部分依賴於(學號,課名)
- 傳遞函數依賴:
通過 A 得到 B,通過 B 得到 C,但是通過 C 不能得到 A,那麼可以說:C 傳遞依賴於 A
通過 學號 推出 系名,系名 推出 系主任,但是 系主任 不能推出 學號,那麼可以說:系主任 專遞依賴於 學號
2.7.2 三範式區分
2.7.2.1 第一範式:屬性不可切割
- 不符合第一範式表設計
| ID | 商品 | 商家ID | 用戶ID |
|---|---|---|---|
| 001 | 5台電腦 | 小米_001 | 00001 |
如上表格不符合第一範式,商品列中的數據不是原子數據項,是可以進行分割的。
- 符合第一範式表設計
| ID | 商品 | 數量 | 商家ID | 用戶ID |
|---|---|---|---|---|
| 001 | 電腦 | 5 | 小米_001 | 00001 |
1NF是所有關係數據庫的最基本要求
2.7.2.2 第二範式:不能存在”部分函數依賴”
- 不符合第二範式表設計
| 學號 | 姓名 | 系名 | 班主任 | 課名 | 分數 |
|---|---|---|---|---|---|
| 001 | 張三 | 古文系 | 李白 | 文言文 | 89 |
| 001 | 張三 | 古文系 | 李白 | 古詩詞 | 78 |
| 001 | 張三 | 古文系 | 李白 | 現代漢語 | 65 |
| 002 | 李四 | 古文系 | 李白 | 文言文 | 45 |
| 002 | 李四 | 古文系 | 李白 | 古詩詞 | 78 |
| 002 | 李四 | 古文系 | 李白 | 甲骨文 | 98 |
| 003 | 王五 | 數學系 | 牛頓 | 高等數學 | 88 |
| 003 | 王五 | 數學系 | 牛頓 | 數學基礎 | 88 |
如上表格不符合第二範式,比如:這張表主鍵(學號,課名),分數完全依賴於(學號和課名),但是姓名並不完全依賴於(學號和課名)
- 符合第二範式表設計
| 學號 | 課名 | 分數 |
|---|---|---|
| 001 | 文言文 | 89 |
| 001 | 古詩詞 | 78 |
| 001 | 現代漢語 | 65 |
| 002 | 文言文 | 45 |
| 002 | 古詩詞 | 78 |
| 002 | 甲骨文 | 98 |
| 003 | 高等數學 | 88 |
| 003 | 數學基礎 | 88 |
| 學號 | 姓名 | 系名 | 班主任 |
|---|---|---|---|
| 001 | 張三 | 古文系 | 李白 |
| 002 | 李四 | 古文系 | 李白 |
| 003 | 王五 | 數學系 | 牛頓 |
2.7.2.3 第三範式:不能存在”傳遞函數依賴”
- 不符合第三範式表設計
| 學號 | 姓名 | 系名 | 班主任 |
|---|---|---|---|
| 001 | 張三 | 古文系 | 李白 |
| 002 | 李四 | 古文系 | 李白 |
| 003 | 王五 | 數學系 | 牛頓 |
如上表格不符合第三範式,比如:學號–>系名–>系主任,但是系主任推不出學號
- 符合第三範式表設計
| 學號 | 姓名 | 系名 |
|---|---|---|
| 001 | 張三 | 古文系 |
| 002 | 李四 | 古文系 |
| 003 | 王五 | 數學系 |
| 系名 | 班主任 |
|---|---|
| 古文系 | 李白 |
| 古文系 | 李白 |
| 數學系 | 牛頓 |
2.8 OLAP典型架構
OLAP有多種實現方法,根據存儲數據的方式不同可以分為ROLAP、MOLAP、HOLAP
| 名稱 | 描述 | 細節數據存儲位置 | 聚合后的數據存儲位置 |
|---|---|---|---|
| ROLAP(Relational OLAP) | 基於關係數據庫的OLAP實現 | 關係型數據庫 | 關係型數據庫 |
| MOLAP(Multidimensional OLAP) | 基於多維數據組織的OLAP實現 | 數據立方體 | 數據立方體 |
| HOLAP(Hybrid OLAP) | 基於混合數據組織的OLAP實現 | 關係型數據庫 | 數據立方體 |
- ROLAP(Relational Online Analytical Processing)
ROLAP架構並不會生成實際的多維數據集,而是使用雪花模式以及多個關係表對數據立方體進行模擬,它的OLAP引擎就是將用戶的OLAP操作,如上鑽下鑽過濾合併等,轉換成SQL語句提交到數據庫中執行,並且提供聚集導航功能,根據用戶操作的維度和度量將SQL查詢定位到最粗粒度的事實表上去
這種架構下的查詢沒有MOLAP快速。因為ROLAP中,所有的查詢都是被轉換為SQL語句執行的。而這些SQL語句的執行會涉及到多個表之間的JOIN操作,沒有MOLAP速度快,往往都是通過內存計算實現。(內存的昂貴大家是知道的)
- MOLAP(Multidimensional Online Analytical Processing)
MOLAP架構會生成一個新的多維數據集,也可以說是構建了一個實際數據立方體。事先將匯總數據計算好,存放在自己特定的多維數據庫中,用戶的OLAP操作可以直接映射到多維數據庫的訪問,不通過SQL訪問。(空間換時間,典型代表Kylin)
在該立方體中,每一格對應一個直接地址,且常用的查詢已被預先計算好。因此每次的查詢都是非常快速的,但是由於立方體的更新比較慢,所以是否使用這種架構得具體問題具體分析。
- HOLAP(Hybrid Online Analytical Processing)
這種架構綜合參考MOLAP和ROLAP而採用一種混合解決方案,將某些需要特別提速的查詢放到MOLAP引擎,其他查詢則調用ROLAP引擎。上述MOLAP和ROLAP的結合。它提供了更大的靈活度,MOLAP提供提供了更加快速的響應速度。但是帶來的問題是,數據裝載的效率非常低,因為其實就是將多維的數據預先填好,但是隨着數據量過大維度成本越高,容易引起“數據爆炸”。
2.9 OLAP數據立方體(Data Cube)
OLAP(online analytical processing)是一種軟件技術,它使分析人員能夠迅速、一致、交互地從各個方面觀察信息,以達到深入理解數據的目的。從各方面觀察信息,也就是從不同的維度分析數據,因此OLAP也稱為多維分析。
很多年前,當我們要手工從一堆數據中提取信息時,我們會分析一堆數據報告。通常這些數據報告採用二維表示,是行與列組成的二維表格。但在真實世界里我們分析數據的角度很可能有多個,數據立方體可以理解為就是維度擴展后的二維表格。下圖展示了一個三維數據立方體:
更多時候數據立方體是N維的。它的實現有兩種方式。其中星形模式就是其中一種,該模式其實是一種連接關係表與數據立方體的橋樑。但對於大多數純OLAP使用者來講,數據分析的對象就是這個邏輯概念上的數據立方體,其具體實現不用深究。對於這些OLAP工具的使用者來講,基本用法是首先配置好維表、事實表,然後在每次查詢的時候告訴OLAP需要展示的維度和事實字段和操作類型即可。
最常見的五大操作:切片,切塊,旋轉,上卷,下鑽。
2.9.1 切片和切塊(Slice and Dice)
在數據立方體的某一維度上選定一個維成員的操作叫切片,而對兩個或多個維執行選擇則叫做切塊。下圖邏輯上展示了切片和切塊操作:
2.9.2 旋轉(Pivot)
旋轉就是指改變報表或頁面的展示方向。對於使用者來說,就是個視圖操作,而從SQL模擬語句的角度來說,就是改變SELECT後面字段的順序而已。下圖邏輯上展示了旋轉操作:
2.9.3 上卷和下鑽(Rol-up and Drill-down)
上卷可以理解為”無視”某些維度;下鑽則是指將某些維度進行細分。下圖邏輯上展示了上卷和下鑽操作:
2.9.4 Cube 和 Cuboid
Cube(或 Data Cube),即數據立方體,是一種常用於數據分析與索引的技術;它可以對原始數據建立多維度索引。通過 Cube 對數據進行分析,可以大大加快數據的查詢效率。
Cuboid 特指在某一種維度組合下所計算的數據。 給定一個數據模型,我們可以對其上的所有維度進行組合。對於 N 個維度來說,組合的所有可能性共有 2 的 N 次方種。對於每一種維度的組合,將度量做 聚合運算,然後將運算的結果保存為一個物化視圖,稱為 Cuboid。
所有維度組合的 Cuboid 作為一個整體,被稱為 Cube。所以簡單來說,一個 Cube 就是許多按維度聚合的物化視圖的集合。
下面來列舉一個具體的例子:
假定有一個電商的銷售數據集,其中維度包括 時間(Time)、商品(Item)、地點(Location)和供應商(Supplier),度量為銷售額(GMV)。
- 那麼所有維度的組合就有 2 的 4 次方 =16 種
- 一維度(1D) 的組合有[Time]、[Item]、[Location]、[Supplier]4 種
- 二維度(2D)的組合 有[Time,Item]、[Time,Location]、[Time、Supplier]、[Item,Location]、 [Item,Supplier]、[Location,Supplier]6 種
- 三維度(3D)的組合也有 4 種
- 零維度(0D)的組合有 1 種
- 四維度(4D)的組合有 1 種
3 數據倉庫的演進
4 數據倉庫主要用途
大家應該已經意識到這個問題:既然分析型數據庫中的操作都是查詢,因此也就不需要嚴格滿足完整性/參照性約束以及範式設計要求,而這些卻正是分析型數據庫精華所在。這樣的情況下再將它歸為數據庫會很容易引起大家混淆,畢竟在絕大多數人心裏數據庫是可以關係型數據庫畫上等號的。
- 那麼為什麼不幹脆叫”面向分析的存儲系統”呢?
這就是關於數據倉庫最貼切的定義了。事實上數據倉庫不應讓傳統關係數據庫來實現,因為關係數據庫最少也要求滿足第1範式,而數據倉庫里的關係表可以不滿足第1範式。也就是說,同樣的記錄在一個關係表裡可以出現N次。但由於大多數數據倉庫內的表的統計分析還是用SQL,因此很多人把它和關係數據庫搞混了。
4.1 支持數據提取
數據提取可以支撐來自企業各業務部門的數據需求。
由之前的不同業務部門給不同業務系統提需求轉變為不同業務系統統一給數據倉庫提需求,避免煙囪式開發
4.2 支持報表系統
基於企業的數據倉庫,向上支撐企業的各部門的統計報表需求,輔助支撐企業日常運營決策。
4.3 支持數據分析
從許多來自不同的企業業務系統的數據中提取出有用的數據並進行清理,以保證數據的正確性,然後經過抽取、轉換和裝載,即ETL過程,合併到一個企業級的數據倉庫里,從而得到企業數據的一個全局視圖;
在此基礎上利用合適的查詢和分析工具、數據挖掘工具、OLAP工具等對其進行分析和處理(這時信息變為輔助決策的知識);
最後將知識呈現給管理者,為管理者的決策過程提供支持 。
4.4 支持數據挖掘
數據挖掘也稱為數據庫知識發現(Knowledge Discovery in Databases, KDD),就是將高級智能計算技術應用於大量數據中,讓計算機在有人或無人指導的情況下從海量數據中發現潛在的,有用的模式(也叫知識)。
Jiawei Han在《數據挖掘概念與技術》一書中對數據挖掘的定義:數據挖掘是從大量數據中挖掘有趣模式和知識的過程,數據源包括數據庫、數據倉庫、Web、其他信息存儲庫或動態地流入系統的數據。
4.5 支持數據應用
物聯網基於位置數據的旅遊客流分析及人群畫像
通信基於位置數據的人流監控和預警
銀行基於用戶交易數據的金融畫像應用
電商根據用戶瀏覽和購買行為的用戶標籤體系及推薦系統
徵信機構根據用戶信用記錄的信用評估
出行基於位置數據的車流量分析,調度預測
5 數據集市
數據集市可以理解為是一種”小型數據倉庫”,它只包含單個主題,且關注範圍也非全局。
數據集市可以分為兩種,一種是獨立數據集市(independent data mart),這類數據集市有自己的源數據庫和ETL架構;另一種是非獨立數據集市(dependent data mart),這種數據集市沒有自己的源系統,它的數據來自數據倉庫。當用戶或者應用程序不需要/不必要/不允許用到整個數據倉庫的數據時,非獨立數據集市就可以簡單為用戶提供一個數據倉庫的”子集”。
- 簡單理解:
- 數據集市:部門級別的數據倉庫,能為某個局部範圍內的管理人員提供服務。
- 數據倉庫:企業級別的數據倉庫,能為企業各個部門的運行提供決策支持。
6 建模的基本概念
6.1 關係建模
上圖為web應用中的一個建模片段,遵循三範式建模,可以看出,較為鬆散、零碎, 物理表數量多,而數據冗餘程度低。由於數據分佈於眾多的表中,這些數據可以更為靈活地 被應用,功能性較強。關係模型主要應用與 OLTP 系統中,為了保證數據的一致性以及避免 冗餘,所以大部分業務系統的表都是遵循第三範式的。
6.2 維度建模
維度建模(dimensional modeling)是專門用於分析型數據庫、數據倉庫、數據集市建模的方法
上圖為維度模型建模片段,主要應用於 OLAP 系統中,通常以某一個事實表為中心進行表的 組織,主要面向業務,特徵是可能存在數據的冗餘,但是能方便的得到數據。
關係模型雖然冗餘少,但是在大規模數據,跨表分析統計查詢過程中,會造成多表關聯,這會大大降低執行效率。所以通常我們採用維度模型建模,把相關各種表整理成兩種: 事實表和維度表兩種
6.3 維度建模的三種模式
- 星形模式
星形模式(Star Schema)是最常用的維度建模方式
可以看出,星形模式的維度建模由一個事實表和一組維表成,且具有以下特點:
- 維表只和事實表關聯,維表之間沒有關聯;
- 每個維表的主碼為單列,且該主碼放置在事實表中,作為兩邊連接的邏輯外鍵;
- 以事實表為核心,維表圍繞核心呈星形分佈;
- 雪花模式
雪花模式(Snowflake Schema)是對星形模式的擴展,每個維表可繼續向外連接多個子維表。(三範式代表作)
星形模式中的維表相對雪花模式來說要大,而且不滿足規範化設計。雪花模型相當於將星形模式的大維表拆分成小維表,滿足了規範化設計。然而這種模式在實際應用中很少見,因為這樣做會導致開發難度增大,而數據冗餘問題在數據倉庫里並不嚴重。
- 星座模式
星座模式(Fact Constellations Schema)也是星型模式的擴展。
前面兩種維度建模方法都是多維表對應單事實表,但在很多時候維度空間內的事實表不止一個,而一個維表也可能被多個事實表用到。在業務發展後期,星座模式將作為最主要的維度建模。
6.4 維度表和事實表
- 維度表(dimension)
表示對分析主題所屬類型的描述。比如”昨天早上張三在京東花費200元購買了一個皮包”。那麼以購買為主題進行分析,可從這段信息中提取三個維度:時間維度(昨天早上),地點維度(京東), 商品維度(皮包)。通常來說維度表信息比較固定,且數據量小。
- 事實表(fact table)
表示對分析主題的度量。比如上面那個例子中,200元就是事實信息。事實表包含了與各維度表相關聯的邏輯外鍵,並通過JOIN方式與維度表關聯。事實表的度量通常是數值類型,且記錄數會不斷增加,表規模迅速增長。
- 事實維度舉例
昨天我去菜市場買了一隻蝙蝠,然後我就被隔離了。
事實:訂單==>買蝙蝠這個事
維度:
- 時間==>昨天
- 用戶==>我
- 商品==>蝙蝠
- 地理==>菜市場
6.4.1 維度表
維度表:一般是對事實的描述信息。每一張維表對應現實世界中的一個對象或者概念。 例如:用戶、商品、日期、地區等。
常用於一個客觀世界的維度描述,往往列比較多。
審視數據的角度
- 維表的特徵:
- 維表的範圍很寬(具有多個屬性、列比較多)
- 跟事實表相比,行數相對較小:通常< 10 萬條
- 靜態表示的,名詞性質的表
6.4.2 事實表
事實表用於正確的記錄既定的已經發生的事實,常用於存儲ID和度量值,各種維度外鍵
事實表中的每行數據代表一個業務事件(下單、支付、退款、評價等)。“事實”這 個術語表示的是業務事件的度量值(可統計次數、個數、件數、金額等),例如,訂單事件中的下單金額。
每一個事實表的行包括:具有可加性的數值型的度量值、與維表相連接的外鍵、通常具 有兩個和兩個以上的外鍵、外鍵之間表示維表之間多對多的關係。
- 事實表的特徵:
- 非常的大
- 內容相對的窄:列數較少
- 經常發生變化,每天會新增加很多
- 動態表示的,動詞性質的表
- 事務型事實表(每天導入新增)
- 以每個事務或事件為單位,例如一個銷售訂單記錄,一筆支付記錄等,作為事實表裡的 一行數據。一旦事務被提交,事實表數據被插入,數據就不再進行更改,其更新方式為增量 更新
- 周期型快照事實表(每日全量)
- 周期型快照事實表中不會保留所有數據,只保留固定時間間隔的數據,例如每天或者 每月的銷售額,或每月的賬戶餘額等
- 累積型快照事實表(每天導入新增及變化)
- 累計快照事實表用於跟蹤業務事實的變化。例如,數據倉庫中可能需要累積或者存儲 訂單從下訂單開始,到訂單商品被打包、運輸、和簽收的各個業務階段的時間點數據來跟蹤 訂單聲明周期的進展情況。當這個業務過程進行時,事實表的記錄也要不斷更新。
6.5 數據分層
- 為什麼分層:
- 簡單化:把複雜的任務分解為多層來完成,每層處理各自的任務,方便定位問題。
- 減少重複開發:規範數據分層,通過中間層數據,能夠極大的減少重複計算,增加結果復用性。
- 隔離數據:不論是數據異常還是數據敏感性,使真實數據和統計數據解耦。
下面列舉常見電商表的分層結構
6.5.1 ODS層
- 保持數據原貌不做任何修改,起到備份數據的作用。
- 數據採用壓縮,減少磁盤存儲空間(例如:原始數據 100G,可以壓縮到 10G 左 右)
- 創建分區表,防止後續的全表掃描
6.5.2 DWD層
DWD 層需構建維度模型,一般採用星型模型,呈現的狀態一般為星座模型。
-
維度建模一般按照四個步驟: 選擇業務過程→聲明粒度→確認維度→確認事實
-
選擇業務過程
- 在業務系統中,挑選我們感興趣的業務線,比如下單業務,支付業務,退款業務,物流 業務,一條業務線對應一張事實表。
-
聲明粒度
-
數據粒度指數據倉庫的數據中保存數據的細化程度或綜合程度的級別。
-
聲明粒度意味着精確定義事實表中的一行數據表示什麼,應該盡可能選擇最小粒度,以 此來應各種各樣的需求。
-
典型的粒度聲明如下:
- 訂單中,每個商品項作為下單事實表中的一行,粒度為每次下單
- 每周的訂單次數作為一行,粒度就是每周下單。
- 每月的訂單次數作為一行,粒度就是每月下單
-
-
確定維度
- 維度的主要作用是描述業務是事實,主要表示的是“誰,何處,何時”等信息。
-
確定事實
- 此處的“事實”一詞,指的是業務中的度量值,例如訂單金額、下單次數等。
- 在 DWD 層,以業務過程為建模驅動,基於每個具體業務過程的特點,構建最細粒度的 明細層事實表。事實表可做適當的寬表化處理。
| 事實/維度 | 時間 | 用戶 | 地區 | 商品 | 優惠卷 | 活動 | 編碼 | 度量 |
|---|---|---|---|---|---|---|---|---|
| 訂單 | √ | √ | √ | √ | 件數/金額 | |||
| 訂單詳情 | √ | √ | √ | 件數/金額 | ||||
| 支付 | √ | √ | 次數/金額 | |||||
| 加入購物車 | √ | √ | √ | 件數/金額 | ||||
| 收藏 | √ | √ | √ | 個數 | ||||
| 評價 | √ | √ | √ | 個數 | ||||
| 退款 | √ | √ | √ | 件數/金額 | ||||
| 優惠卷領用 | √ | √ | √ | 個數 |
6.5.3 DWS層
- 統計各個主題對象的當天行為,服務於 DWT 層的主題寬表,以及一些業務明細數據, 應對特殊需求(例如,購買行為,統計商品復購率)。
6.5.4 DWT層
- 以分析的主題對象為建模驅動,基於上層的應用和產品的指標需求,構建主題對象的全 量寬表。(就是按照維度來決定分析者的角度,如用戶->什麼時間->下了什麼單,支付了什麼,加入購物車了什麼)
6.5.5 ADS層
對系統各大主題指標分別進行分析。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!