前言
先拋一個問題給我聰明的讀者,如果你們使用微服務SpringCloud-Netflix進行業務開發,那麼線上註冊中心肯定也是用了集群部署,問題來了:
你了解Eureka註冊中心集群如何實現客戶端請求負載及故障轉移嗎?
可以先思考一分鐘,我希望你能夠帶着問題來閱讀此篇文章,也希望你看完文章後會有所收穫!
背景
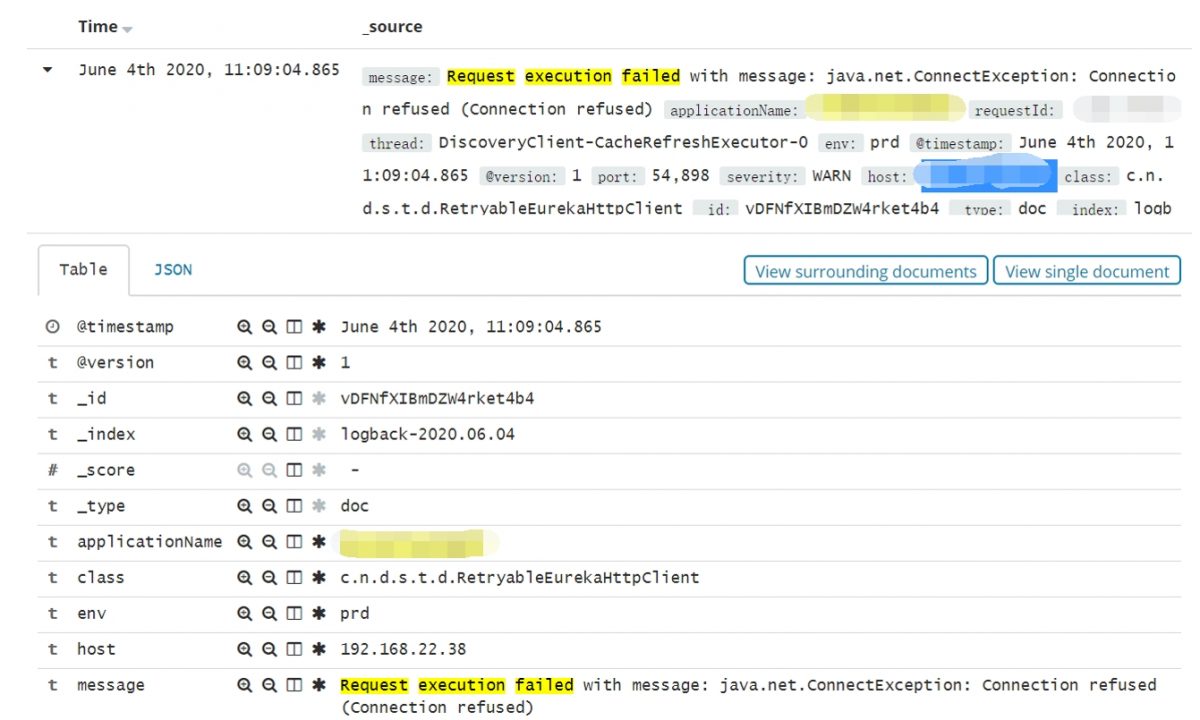
前段時間線上Sentry平台報警,多個業務服務在和註冊中心交互時,例如續約和註冊表增量拉取等都報了Request execution failed with message : Connection refused 的警告:
緊接着又看到 Request execution succeeded on retry #2 的日誌。
看到這裏,表明我們的服務在嘗試兩次重連后和註冊中心交互正常了。
一切都顯得那麼有驚無險,這裏報Connection refused 是註冊中心網絡抖動導致的,接着觸發了我們服務的重連,重連成功后一切又恢復正常。
這次的報警雖然沒有對我們線上業務造成影響,並且也在第一時間恢復了正常,但作為一個愛思考的小火雞,我很好奇這背後的一系列邏輯:Eureka註冊中心集群如何實現客戶端請求負載及故障轉移?
註冊中心集群負載測試
線上註冊中心是由三台機器組成的集群,都是4c8g的配置,業務端配置註冊中心地址如下(這裏的peer來代替具體的ip地址):
eureka.client.serviceUrl.defaultZone=http://peer1:8080/eureka/,http://peer2:8080/eureka/,http://peer3:8080/eureka/
我們可以寫了一個Demo進行測試:
註冊中心集群負載測試
1、本地通過修改EurekaServer服務的端口號來模擬註冊中心集群部署,分別以8761和8762兩個端口進行啟動
2、啟動客戶端SeviceA,配置註冊中心地址為:http://localhost:8761/eureka,http://localhost:8762/eureka
3、啟動SeviceA時在發送註冊請求的地方打斷點:AbstractJerseyEurekaHttpClient.register(),如下圖所示:
這裏看到請求註冊中心時,連接的是8761這個端口的服務。
4、更改ServiceA中註冊中心的配置:http://localhost:8762/eureka,http://localhost:8761/eureka
5、重新啟動SeviceA然後查看端口,如下圖所示:
此時看到請求註冊中心是,連接的是8762這個端口的服務。
註冊中心故障轉移測試
以兩個端口分別啟動EurekaServer服務,再啟動一個客戶端ServiceA。啟動成功后,關閉一個8761端口對應的服務,查看此時客戶端是否會自動遷移請求到8762端口對應的服務:
1、以8761和8762兩個端口號啟動EurekaServer
2、啟動ServiceA,配置註冊中心地址為:http://localhost:8761/eureka,http://localhost:8762/eureka
3、啟動成功后,關閉8761端口的EurekaServer
4、在EurekaClient端發送心跳請求的地方打上斷點:AbstractJerseyEurekaHttpClient.sendHeartBeat()
5、查看斷點處數據,第一次請求的EurekaServer是8761端口的服務,因為該服務已經關閉,所以返回的response是null
6、第二次會重新請求8762端口的服務,返回的response為狀態為200,故障轉移成功,如下圖:
思考
通過這兩個測試Demo,我以為EurekaClient每次都會取defaultZone配置的第一個host作為請求EurekaServer的請求的地址,如果該節點故障時,會自動切換配置中的下一個EurekaServer進行重新請求。
那麼疑問來了,EurekaClient每次請求真的是以配置的defaultZone配置的第一個服務節點作為請求的嗎?這似乎也太弱了!!?
EurekaServer集群不就成了偽集群!!?除了客戶端配置的第一個節點,其它註冊中心的節點都只能作為備份和故障轉移來使用!!?
真相是這樣嗎?NO!我們眼見也不一定為實,源碼面前毫無秘密!
翠花,上乾貨!
客戶端請求負載原理
原理圖解
還是先上結論,負載原理如圖所示:
這裡會以EurekaClient端的IP作為隨機的種子,然後隨機打亂serverList,例如我們在商品服務(192.168.10.56)中配置的註冊中心集群地址為:peer1,peer2,peer3,打亂后的地址可能變成peer3,peer2,peer1。
用戶服務(192.168.22.31)中配置的註冊中心集群地址為:peer1,peer2,peer3,打亂后的地址可能變成peer2,peer1,peer3。
EurekaClient每次請求serverList中的第一個服務,從而達到負載的目的。
代碼實現
我們直接看最底層負載代碼的實現,具體代碼在
com.netflix.discovery.shared.resolver.ResolverUtils.randomize() 中:
這裏面random 是通過我們EurekaClient端的ipv4做為隨機的種子,生成一個重新排序的serverList,也就是對應代碼中的randomList,所以每個EurekaClient獲取到的serverList順序可能不同,在使用過程中,取列表的第一個元素作為server端host,從而達到負載的目的。
思考
原來代碼是通過EurekaClient的IP進行負載的,所以剛才通過DEMO程序結果就能解釋的通了,因為我們做實驗都是用的同一個IP,所以每次都是會訪問同一個Server節點。
既然說到了負載,這裏肯定會有另一個疑問:
通過IP進行的負載均衡,每次請求都會均勻分散到每一個Server節點嗎?
比如第一次訪問Peer1,第二次訪問Peer2,第三次訪問Peer3,第四次繼續訪問Peer1等,循環往複……
我們可以繼續做個試驗,假如我們有10000個EurekaClient節點,3個EurekaServer節點。
Client節點的IP區間為:192.168.0.0 ~ 192.168.255.255,這裏面共覆蓋6w多個ip段,測試代碼如下:
/**
* 模擬註冊中心集群負載,驗證負載散列算法
*
* @author 一枝花算不算浪漫
* @date 2020/6/21 23:36
*/
public class EurekaClusterLoadBalanceTest {
public static void main(String[] args) {
testEurekaClusterBalance();
}
/**
* 模擬ip段測試註冊中心負載集群
*/
private static void testEurekaClusterBalance() {
int ipLoopSize = 65000;
String ipFormat = "192.168.%s.%s";
TreeMap<String, Integer> ipMap = Maps.newTreeMap();
int netIndex = 0;
int lastIndex = 0;
for (int i = 0; i < ipLoopSize; i++) {
if (lastIndex == 256) {
netIndex += 1;
lastIndex = 0;
}
String ip = String.format(ipFormat, netIndex, lastIndex);
randomize(ip, ipMap);
System.out.println("IP: " + ip);
lastIndex += 1;
}
printIpResult(ipMap, ipLoopSize);
}
/**
* 模擬指定ip地址獲取對應註冊中心負載
*/
private static void randomize(String eurekaClientIp, TreeMap<String, Integer> ipMap) {
List<String> eurekaServerUrlList = Lists.newArrayList();
eurekaServerUrlList.add("http://peer1:8080/eureka/");
eurekaServerUrlList.add("http://peer2:8080/eureka/");
eurekaServerUrlList.add("http://peer3:8080/eureka/");
List<String> randomList = new ArrayList<>(eurekaServerUrlList);
Random random = new Random(eurekaClientIp.hashCode());
int last = randomList.size() - 1;
for (int i = 0; i < last; i++) {
int pos = random.nextInt(randomList.size() - i);
if (pos != i) {
Collections.swap(randomList, i, pos);
}
}
for (String eurekaHost : randomList) {
int ipCount = ipMap.get(eurekaHost) == null ? 0 : ipMap.get(eurekaHost);
ipMap.put(eurekaHost, ipCount + 1);
break;
}
}
private static void printIpResult(TreeMap<String, Integer> ipMap, int totalCount) {
for (Map.Entry<String, Integer> entry : ipMap.entrySet()) {
Integer count = entry.getValue();
BigDecimal rate = new BigDecimal(count).divide(new BigDecimal(totalCount), 2, BigDecimal.ROUND_HALF_UP);
System.out.println(entry.getKey() + ":" + count + ":" + rate.multiply(new BigDecimal(100)).setScale(0, BigDecimal.ROUND_HALF_UP) + "%");
}
}
}
負載測試結果如下:
可以看到第二個機器會有50%的請求,最後一台機器只有17%的請求,負載的情況並不是很均勻,我認為通過IP負載並不是一個好的方案。
還記得我們之前講過Ribbon默認的輪詢算法RoundRobinRule,【一起學源碼-微服務】Ribbon 源碼四:進一步探究Ribbon的IRule和IPing 。
這種算法就是一個很好的散列算法,可以保證每次請求都很均勻,原理如下圖:
故障轉移原理
原理圖解
還是先上結論,如下圖:
我們的serverList按照client端的ip進行重排序后,每次都會請求第一個元素作為和Server端交互的host,如果請求失敗,會嘗試請求serverList列表中的第二個元素繼續請求,這次請求成功后,會將此次請求的host放到全局的一個變量中保存起來,下次client端再次請求 就會直接使用這個host。
這裏最多會重試請求兩次。
代碼實現
直接看底層交互的代碼,位置在
com.netflix.discovery.shared.transport.decorator.RetryableEurekaHttpClient.execute() 中:
我們來分析下這個代碼:
- 第101行,獲取
client上次成功server端的host,如果有值則直接使用這個host
- 第105行,
getHostCandidates()是獲取client端配置的serverList數據,且通過ip進行重排序的列表
- 第114行,
candidateHosts.get(endpointIdx++),初始endpointIdx=0,獲取列表中第1個元素作為host請求
- 第120行,獲取返回的
response結果,如果返回的狀態碼是200,則將此次請求的host設置到全局的delegate變量中
- 第133行,執行到這裏說明第120行執行的
response返回的狀態碼不是200,也就是執行失敗,將全局變量delegate中的數據清空
- 再次循環第一步,此時
endpointIdx=1,獲取列表中的第二個元素作為host請求
- 依次執行,第100行的循環條件
numberOfRetries=3,最多重試2次就會跳出循環
我們還可以第123和129行,這也正是我們業務拋出來的日誌信息,所有的一切都對應上了。
總結
感謝你看到這裏,相信你已經清楚了開頭提問的問題。
上面已經分析完了Eureka集群下Client端請求時負載均衡的選擇以及集群故障時自動重試請求的實現原理。
如果還有不懂的問題,可以添加我的微信或者給我公眾號留言,我會單獨和你討論交流。
本文首發自:一枝花算不算浪漫 公眾號,如若轉載請在文章開頭標明出處,如需開白可直接公眾號回復即可。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心