文:宋瑞文
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
如果我們想要使用序列化器對應的是Django的模型類,DRF為我們提供了ModelSerializer模型類序列化器來幫助我們快速創建一個Serializer類。
ModelSerializer與常規的Serializer相同,但提供了:
比如我們創建一個BookInfoSerializer
class BookInfoSerializer(serializers.ModelSerializer):
"""圖書數據序列化器"""
class Meta:
model = BookInfo
fields = '__all__'
我們可以在python manage.py shell中查看自動生成的BookInfoSerializer的具體實現
>>> from booktest.serializers import BookInfoSerializer
>>> serializer = BookInfoSerializer()
>>> serializer
BookInfoSerializer():
id = IntegerField(label='ID', read_only=True)
btitle = CharField(label='名稱', max_length=20)
bpub_date = DateField(allow_null=True, label='發布日期', required=False)
bread = IntegerField(label='閱讀量', max_value=2147483647, min_value=-2147483648, required=False)
bcomment = IntegerField(label='評論量', max_value=2147483647, min_value=-2147483648, required=False)
image = ImageField(allow_null=True, label='圖片', max_length=100, required=False)
__all__表名包含所有字段,也可以寫明具體哪些字段,如class BookInfoSerializer(serializers.ModelSerializer):
"""圖書數據序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date')
class BookInfoSerializer(serializers.ModelSerializer):
"""圖書數據序列化器"""
class Meta:
model = BookInfo
exclude = ('image',)
class HeroInfoSerializer2(serializers.ModelSerializer):
class Meta:
model = HeroInfo
fields = '__all__'
depth = 1
形成的序列化器如下:
HeroInfoSerializer():
id = IntegerField(label='ID', read_only=True)
hname = CharField(label='名稱', max_length=20)
hgender = ChoiceField(choices=((0, 'male'), (1, 'female')), label='性別', required=False, validators=[<django.core.valators.MinValueValidator object>, <django.core.validators.MaxValueValidator object>])
hcomment = CharField(allow_null=True, label='描述信息', max_length=200, required=False)
hbook = NestedSerializer(read_only=True):
id = IntegerField(label='ID', read_only=True)
btitle = CharField(label='名稱', max_length=20)
bpub_date = DateField(allow_null=True, label='發布日期', required=False)
bread = IntegerField(label='閱讀量', max_value=2147483647, min_value=-2147483648, required=False)
bcomment = IntegerField(label='評論量', max_value=2147483647, min_value=-2147483648, required=False)
image = ImageField(allow_null=True, label='圖片', max_length=100, required=False)
class HeroInfoSerializer(serializers.ModelSerializer):
hbook = BookInfoSerializer()
class Meta:
model = HeroInfo
fields = ('id', 'hname', 'hgender', 'hcomment', 'hbook')
可以通過read_only_fields指明只讀字段,即僅用於序列化輸出的字段
class BookInfoSerializer(serializers.ModelSerializer):
"""圖書數據序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
read_only_fields = ('id', 'bread', 'bcomment')
我們可以使用extra_kwargs參數為ModelSerializer添加或修改原有的選項參數
class BookInfoSerializer(serializers.ModelSerializer):
"""圖書數據序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
extra_kwargs = {
'bread': {'min_value': 0, 'required': True},
'bcomment': {'min_value': 0, 'required': True},
}
# BookInfoSerializer():
# id = IntegerField(label='ID', read_only=True)
# btitle = CharField(label='名稱', max_length=20)
# bpub_date = DateField(allow_null=True, label='發布日期', required=False)
# bread = IntegerField(label='閱讀量', max_value=2147483647, min_value=0, required=True)
# bcomment = IntegerField(label='評論量', max_value=2147483647, min_value=0, required=True)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧

最近一直啥都沒寫,追個熱點都趕不上熱乎的,鄙視自己一下。
周董的新歌 「MOJITO」 發售(6 月 12 日的零點)至今大致過去了一周,翻開 B 站 MV 一看,播放量妥妥破千萬,彈幕破十萬,這人氣還真是杠杠的。
說實話, 「MOJITO」 這個名字對我來講有點超綱了,第一次見到完全不知道啥意思。
不過問題不大,沒有什麼是百度解決不了的,如果有,那就再加一個知乎。
MOJITO 的中文名是莫吉托,百度百科上是這麼介紹莫吉托的:
莫吉托(Mojito)是最有名的朗姆調酒之一。起源於古巴。傳統上,莫吉托是一種由五種材料製成的雞尾酒:淡朗姆酒、糖(傳統上是用甘蔗汁)、萊姆(青檸)汁、蘇打水和薄荷。最原始的古巴配方是使用留蘭香或古巴島上常見的檸檬薄荷。萊姆(青檸)與薄荷的清爽口味是為了與朗姆酒的烈性相互補,同時也使得這種透明無色的調酒成為夏日的熱門飲料之一。這種調酒有着相對低的酒精含量(大約10%)。
酒精度數在 10% 左右的話,姑且可以認為一種飲料吧。
當然,如果要開車的話就不能把 MOJITO 當成飲料了,酒精含量再低那也是酒精。
整個 MV 我翻來覆去的看了好幾遍, 「MOJITO」 這個東西除了在歌詞和名字中有出現,在 MV 當中一次都沒出現,毫無存在感。
彈幕數據的爬取比較簡單,我就不一步一步的抓請求給各位演示了,注意下面這幾個請求連接:
彈幕請求地址:
https://api.bilibili.com/x/v1/dm/list.so?oid=XXX
https://comment.bilibili.com/XXX.xml
第一個地址由於 B 站的網頁做了更換,現在在 Chrome 工具的 network 裏面已經找不到了,不過還可以用,這個是我之前找到的。
第二個地址來源於百度,我也不知道各路大神是從哪找出來這個地址的,供參考吧。
上面這兩個彈幕地址實際上都需要一個叫 oid 的東西,這個 oid 獲取方式如下:
首先可以找到一個目錄頁接口:
https://api.bilibili.com/x/player/pagelist?bvid=XXX&jsonp=jsonp
這個接口也是來源於 Chrome 的 network ,其中 bvid 這個參數來源於視頻地址,比如周董的這個 「MOJITO」 的 MV ,地址是 https://www.bilibili.com/video/BV1PK4y1b7dt ,那麼這個 bvid 的值就是最後那一部分 BV1PK4y1b7dt 。
接下來在 https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp 這個接口中,我們可以看到返回的 json 參數,如下:
{
"code":0,
"message":"0",
"ttl":1,
"data":[
{
"cid":201056987,
"page":1,
"from":"vupload",
"part":"JAY-MOJITO_完整MV(更新版)",
"duration":189,
"vid":"",
"weblink":"",
"dimension":{
"width":1920,
"height":1080,
"rotate":0
}
}
]
}
注意:由於這個 MV 只有一個完整的視頻,所以這裏只有一個 cid ,如果一個視頻是分不同小節發布的,這裏就會有多個 cid ,不同的 cid 代表不同的視頻。
當然,這裏的 cid 就是我們剛才想找的那個 oid ,把這個 cid 拼到剛才的鏈接上,可以得到 https://api.bilibili.com/x/v1/dm/list.so?oid=201056987 這樣一個地址,然後輸入到瀏覽器中,可以看到彈幕的返回數據,是一個 xml 格式的文本。
源代碼如下:
import requests
import re
# 獲取 cid
res = requests.get("https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp")
cid = res.json()['data'][0]['cid']
# 將彈幕 xml 通過正則取出,生成 list
danmu_url = f"https://api.bilibili.com/x/v1/dm/list.so?oid={cid}"
result = requests.get(danmu_url).content.decode('utf-8')
pattern = re.compile('<d.*?>(.*?)</d>')
danmu_list = pattern.findall(result)
# 將彈幕 list 保存至 txt 文件
with open("dan_mu.txt", mode="w", encoding="utf-8") as f:
for item in danmu_list:
f.write(item)
f.write("\n")
這裏我將獲取到的彈幕保存在了 dan_mu.txt 文件中,方便後續分析。
第一步先將剛才保存在 dan_mu.txt 文件中的彈幕讀取出來,放到了一個 list 當中:
# 讀取彈幕 txt 文件
with open("dan_mu.txt", encoding="utf-8") as f:
txt = f.read()
danmu_list = txt.split("\n")
然後使用分詞工具對彈幕進行分詞,我這裏使用的分詞工具是最好的 Python 中文分詞組件 jieba ,沒有安裝過 jieba 的同學可以使用以下命令進行安裝:
pip install jieba
使用 jieba 對剛才獲得的彈幕 list 進行分詞:
# jieba 分詞
danmu_cut = [jieba.lcut(item) for item in danmu_list]
這樣,我們獲得了分詞后的 danmu_cut ,這個同樣是一個 list 。
接着我們對分詞后的 danmu_cut 進行下一項操作,去除停用詞:
# 獲取停用詞
with open("baidu_stopwords.txt",encoding="utf-8") as f:
stop = f.read()
stop_words = stop.split()
# 去掉停用詞后的最終詞
s_data_cut = pd.Series(danmu_cut)
all_words_after = s_data_cut.apply(lambda x:[i for i in x if i not in stop])
這裏我引入了一個 baidu_stopwords.txt 文件,這個文件是百度停用詞庫,這裏我找到了幾個常用的中文停用詞庫,來源: https://github.com/goto456/stopwords 。
| 詞表文件 | 詞表名 |
|---|---|
| baidu_stopwords.txt | 百度停用詞表 |
| hit_stopwords.txt | 哈工大停用詞表 |
| scu_stopwords.txt | 四川大學機器智能實驗室停用詞庫 |
| cn_stopwords.txt | 中文停用詞表 |
這裏我使用的是百度停用詞表,大家可以根據自己的需要使用,也可以對這幾個停用詞表先做整合后再使用,主要的目的就是去除一些無需關注的詞,上面這幾個停用詞庫我都會提交到代碼倉庫,有需要的自取。
接着我們統計去除停用詞后的詞頻:
# 詞頻統計
all_words = []
for i in all_words_after:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
最後一步就是生成我們的最終結果,詞雲圖:
wordcloud.WordCloud(
font_path='msyh.ttc',
background_color="#fff",
max_words=1000,
max_font_size=200,
random_state=42,
width=900,
height=1600
).fit_words(word_count).to_file("wordcloud.png")
最終結果就是下面這個:
從上面這個詞雲圖中可以看到,粉絲對「MOJITO」這首歌是真愛啊,出現頻率最高的就是 啊啊啊 和 愛 還有 粉 。
當然哈,這個 粉 也有可能是說 MV 當中那台騷氣十足的粉色的老爺車。
還有一個出現頻率比較高的是 爺青回 ,我估計這個意思應該是 爺的青春回來啦 ,確實,周董伴隨着我這個年齡段的人一路走來,做為一位 79 年的人現在已經是 41 歲的「高齡」了,回首往昔,讓人唏噓不已。
當年一首 「雙節棍」 火遍了中華大地,大街上的音像店整天都在循環這幾首歌,在學校上學的我這一代人,基本上是人人都能哼兩句,「快使用雙截棍,哼哼哈嘿」成了我們這一代人共有的回憶。
我們還可以對彈幕進行一次情感傾向分析,這裏我使用的是 「百度 AI 開放平台」 的情感傾向分析接口。
百度 AI 開放平台文檔地址:https://ai.baidu.com/ai-doc/NLP/zk6z52hds
首先是根據文檔接入 「百度 AI 開放平台」 ,獲取 access_token ,代碼如下:
# 獲取 Baidu API access_token
access_token_url = f'https://aip.baidubce.com/oauth/2.0/token?grant_type={grant_type}&client_id={client_id}&client_secret={client_secret}&'
res = requests.post(access_token_url)
access_token = res.json()['access_token']
# 通用情感接口
# sentiment_url = f'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token={access_token}'
# 定製化情感接口
sentiment_url = f'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify_custom?charset=UTF-8&access_token={access_token}'
百度 AI 開放平台有兩個情感分析接口,一個是通用的,還有一個是定製化的,我這裏使用的是經過訓練的定製化的接口,如果沒有定製化的接口,使用通用的接口也沒有問題。
上面使用到的 grant_type , client_id , client_secret 這幾個參數,大家註冊一下就能得到, 「百度 AI 開放平台」 上的這些接口都有調用數量的限制,不過我們自己使用已經足夠了。
然後讀取我們剛才保存的彈幕文本:
with open("dan_mu.txt", encoding="utf-8") as f:
txt = f.read()
danmu_cat = txt.split("\n")
在調用接口獲得情感傾向之前,我們還需要做一件事情,對彈幕進行一次處理,因為彈幕中會有一些 emoji 表情,而 emoji 直接請求百度的接口會返回錯誤,這裏我使用另一個工具包對 emoji 表情進行處理。
首先安裝工具包 emoji :
pip install emoji
使用是非常簡單的,我們對彈幕數據使用 emoji 進行一次處理:
import emoji
with open("dan_mu.txt", encoding="utf-8") as f:
txt = f.read()
danmu_list = txt.split("\n")
for item in danmu_list:
print(emoji.demojize(item))
我們的彈幕數據中是有這樣的 emoji 表情的:
# 處理后:
:red_heart::red_heart::red_heart::red_heart::red_heart::red_heart::red_heart:
然後,我們就可以調用百度的情感傾向分析接口,對我們的彈幕數據進行分析了:
# 情感計數器
optimistic = 0
neutral = 0
pessimistic = 0
for danmu in danmu_list:
# 因調用 QPS 限制,每次調用間隔 0.5s
time.sleep(0.5)
req_data = {
'text': emoji.demojize(danmu)
}
# 調用情感傾向分析接口
if len(danmu) > 0:
r = requests.post(sentiment_url, json = req_data)
print(r.json())
for item in r.json()['items']:
if item['sentiment'] == 2:
# 正向情感
optimistic += 1
if item['sentiment'] == 1:
# 中性情感
neutral += 1
if item['sentiment'] == 0:
# 負向情感
pessimistic += 1
print('正向情感:', optimistic)
print('中性情感:', neutral)
print('負向情感:', pessimistic)
attr = ['正向情感','中性情感','負向情感']
value = [optimistic, neutral, pessimistic]
c = (
Pie()
.add("", [list(attr) for attr in zip(attr, value)])
.set_global_opts(title_opts=opts.TitleOpts(title="「MOJITO」彈幕情感分析"))
.render("pie_base.html")
)
最後的結果圖長這樣:
從最後的結果上來看,正向情感佔比大約在 2/3 左右,而負向情感只有不到 1/4 ,看來大多數人看到周董的新歌還是滿懷激動的心情。
不過這個數據不一定準確,最多可以做一個參考。
需要源代碼的同學可以在公眾號後台回復「MOJITO」獲取。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧

 |
騰訊於2017年3月29日宣布以17.8億美金買下Tesla 5%股權,此投資顯示騰訊對Elon Musk事業遠見之信心。騰訊資金的投入也有助於預定2017年底上市的Model 3。除此之外,Elon Musk在推特上回應關於太陽能瓦片的上市時間。
外媒The Australian報導,汽車產業諮詢師Michael Dunne認為,騰訊旗下擁有中國最大的社群軟體微信(WeChat),如此有助於Tesla發展在中國生產製造的產線。Tesla過去曾和中國政府談論在中國建組裝廠一事,Elon Musk也表示若在中國建組裝廠不僅可以省下3分之1之成本,也可以省去進口關稅。
根據中國的調查機構JL Warren Capital資料顯示,光是2016,中國向Tesla進口了11,839輛電動車,和2015相比成長了近5倍。騰訊與鴻海投資的新創汽車公司知行(FMC)預計在2020生廠自家的電動車,擁有Tesla股份也對FMC未來電動車布局有益。
(首圖來源:Tesla)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧

 |
特斯拉(Tesla)電動車成功引領話題,各大車廠跟紛紛仿效,搶攻此一市場。原本力推燃料電池車的韓國車廠–現代汽車(Hyundai Motor),眼看市場風向轉變,也宣布要研發該公司首款電動車專屬的車用平台(car platform)。
路透社30日報導,車用平台意指外觀不同的汽車共享相通的設計、工程、生產流程,以及主要零件等,能夠壓低研發成本。現代汽車之前力推燃料電池車,如今轉攻電池車,突顯投資人施壓,要求該公司積極進軍新市場。
現代汽車的電動車平台,電池將位於汽車底部,以便容納大容量電池,並讓車內空間最大化。現代-起亞環保車主管Lee Ki-sang說,電動車平台初期投資費用高,但是他們必須替未來做準備。分析師說現代別無選擇,必須追隨特斯拉、通用汽車、Daimler AG旗下的賓士(Mercedes-Benz),打造單獨的電動車平台,才能留在此一市場。
Hi Investment & Securities分析師Ko Tae-bong表示,單獨平台初始時可能會造成虧損,但是現代若不研發長程電動車將落後對手,例如300、500、600公里車款。
電動車大廠特斯拉(Tesla Inc.)要價35,000美元的平價車種「Model 3」預計2017年稍晚就能開賣,摩根士丹利(通稱大摩)認為,這款電動車的安全度會是一般車輛的10倍之多,發生死亡車禍的機率有望比其他車種低90%。
MarketWatch、Business Insider等外電報導,大摩分析師Adam Jonas 23日發表研究報告指出,特斯拉為每台車安裝超級電腦後,車子安全性提升至其他車輛兩倍已經不夠看,他相信Model 3的安全度會是其他車輛的十倍之多,這會讓死亡車禍的發生機會降低90%。
Jonas認為,缺少特斯拉駕車輔助科技的二手車價值將因而猛掉,未來甚至會被禁止上路。特斯拉蒐集資料的能力超群,還能將先進的安全輔助技術應用到電動車,還未推出類似科技的傳統車廠,競爭力堪虞。
(本文內容由授權使用。圖片出處:Hyundai)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧

 |
特斯拉(Tesla Inc)正在加速趕工,希望能在2017年9月讓平價電動車「Model 3」如期投產,但執行長馬斯克(Elon Musk)為了達標、在生產策略上背負不小風險,未來可能會面臨召回、維修等龐大成本。
路透社24日報導(),大多數的汽車製造商都會先訂購較便宜的原型設備來測試新車款的生產線,一旦成功打造出合適的車門、儀表板等零組件,就會把這些便宜的設備報廢。
然而,特斯拉在打造Model 3時卻跳過這項程序,直接訂購較為昂貴的永久設備加速趕工,目標就是趕上自己設定的9月量產期限。不過,用來量產數百萬輛汽車的設備假如無法順利製造出合適的零件,想要修正或直接替代,都得花費大把資金。特斯拉現有的車種產量雖少,卻已在品質方面出現問題,Model 3預設的年產量多達50萬台,一旦需要召回或進行保固期維修,都會拉高公司成本。
馬斯克3月份在一場法說會曾討論過這個問題。他當時說,利用「先進的分析技術」(即電腦模擬科技的代稱),就能幫助特斯拉直接進入安裝設備的階段。
的確,福斯(Volkswagen AG)旗下的奧迪(Audi)部門,已經領先業界在墨西哥新建廠房採用生產工具的電腦模擬科技,讓初步投產的時間,比一般流程快了30%。當時參與奧迪墨西哥廠投產流程的經理Peter Hochholdinger,如今已成為特斯拉生產部門的副總裁。除此之外,特斯拉在2015年收購一家密西根設備業者後,也學到更佳的設備修整技術,不但讓製造大型機具的速度加快30%、成本還能壓得更低。
話雖如此,特斯拉自2003年成立以來就面臨龐大的金融壓力,雖然3月的12億美元募資行動、以及將5%股權賣給騰訊(Tencent Holdings Ltd),讓公司喘了一口氣,但若是Model 3生產不順,後果堪慮。
CNET、路透社等多家外電報導,特斯拉甫於4月20日宣布在全球召回53,000輛Model S、Model X電動車,以便修正電子手煞車的問題。
特斯拉在聲明中表示,受到影響的是在2016年2月至10月期間生產的Model S與Model X,這些汽車的電子手煞車當中,有一款由第三方廠商供應的小型零組件因製造不當而容易裂開,會讓手煞車無法解除。
特斯拉強調,上述瑕疵至今並未引發任何車禍、也未導致人員死傷,估計這些車輛中,只有不到5%有問題,更換手煞車的時間僅需不到45分鐘。根據聲明,特斯拉正在跟義大利供應商Freni Brembo SpA合作,取得需要更替的零組件。
(本文內容由授權使用。圖片出處:Tesla)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧

 |
特斯拉(Tesla Inc.)負責自動化、工程專業的主管Klaus Grohmann,傳出因理念和執行長馬斯克(Elon Musk)不合,已經在3月份離職。市場擔憂,這恐怕會影響特斯拉電動車的量產計畫。
路透社27日獨家報導(),特斯拉在2016年11月收購Grohmann創辦的Grohmann Engineering,原本打算靠著這家企業的自動化、工程專長,在2018年將電動車年產量拉升至50萬台。
不過,消息人士透露,Grohmann跟馬斯克在如何對待現有客戶的問題上衝突不斷,是促使Grohmann離職的主因。據傳,馬斯克要求Grohmann把重心擺到特斯拉專案,將Grohmann Engineering原有客戶(如戴姆勒和BMW)的利益放到後頭。
消息稱,特斯拉仍計畫運用Grohmann留下的技術和人員拉高產能,但部分人在創辦人離開後,對只仰賴一家客戶(也就是特斯拉)的作法感到相當不安。
特斯拉正在加速趕工,希望能在2017年9月讓平價電動車「Model 3」如期投產,但馬斯克為了達標、在生產策略上背負不小風險,未來可能會面臨召回、維修等龐大成本。
路透社4月24日報導,大多數的汽車製造商都會先訂購較便宜的原型設備來測試新車款的生產線,一旦成功打造出合適的車門、儀表板等零組件,就會把這些便宜的設備報廢。
然而,特斯拉在打造Model 3時卻跳過這項程序,直接訂購較為昂貴的永久設備加速趕工,目標就是趕上自己設定的9月量產期限。不過,用來量產數百萬輛汽車的設備假如無法順利製造出合適的零件,想要修正或直接替代,都得花費大把資金。Model 3預設的年產量多達50萬台,一旦需要召回或進行保固期維修,都會拉高公司成本。
CNET、路透社等多家外電報導,特斯拉甫於4月20日宣布在全球召回53,000輛Model S、Model X電動車,以便修正電子手煞車的問題。
特斯拉在聲明中表示,受到影響的是在2016年2月至10月期間生產的Model S與Model X,這些汽車的電子手煞車當中,有一款由第三方廠商供應的小型零組件因製造不當而容易裂開,會讓手煞車無法解除。
特斯拉強調,上述瑕疵至今並未引發任何車禍、也未導致人員死傷,估計這些車輛中,只有不到5%有問題,更換手煞車的時間僅需不到45分鐘。根據聲明,特斯拉正在跟義大利供應商Freni Brembo SpA合作,取得需要更替的零組件。
(本文內容由授權使用。圖片出處:public domain CC0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
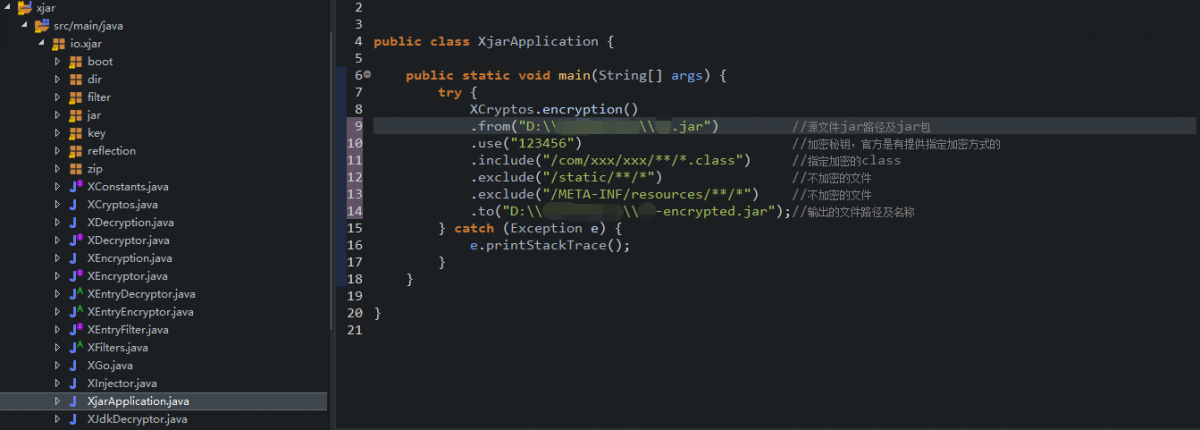
Java的 Jar包中的.class文件可以通過反彙編得到源碼。這樣一款應用的安全性就很難得到保證,別人只要得到你的應用,不需花費什麼力氣,就可以得到源碼。
這時候就需要對jar進行加密處理。
GitHub:https://github.com/core-lib/xjar
碼雲:https://gitee.com/core-lib/xjar?_from=gitee_search
GitHub:https://github.com/core-lib/xjar-maven-plugin
碼雲:https://gitee.com/core-lib/xjar-maven-plugin?_from=gitee_search
xjar-agent-hibernate
GitHub:https://github.com/core-lib/xjar-agent-hibernate
碼雲:https://gitee.com/core-lib/xjar-agent-hibernate?_from=gitee_search
文檔可以到github、碼雲上去了解,這裏只描述使用過程,親測可用!
這裏使用的maven版本是:apache-maven-3.6.3,低版本的沒測試過
1-1.在github或碼雲上下載該項目,導入eclipse,然後新建一個main類,填入參數,直接運行得到一個xjar.go 和 加密后的jar包【xx-encrypted.jar】。
注意:這種直接在項目中跑mian,不提倡,會導致jar包中包含這段代碼,導緻密碼泄露,所以要通過命令行的方式來執行這段代碼。
1-2.這時候可以用反編譯軟件 jb-gui 打開jar看看加密的效果,這時候反編譯軟件已經看不到.class文件的源碼了
1-3.加密后的jar包,不能直接用原來的java 命令來執行,需要用到同時生成的xjar.go文件,執行命令 go build xjar.go
這裏要等待一小會,等待編譯出目標文件xjar.exe
1-4. 最後執行命令,xjar java -jar /path/to/encrypted.jar,即可運行加密后的jar包
注意:Spring Boot + JPA(Hibernate) 啟動會報錯
1-5:沒有採用 Spring Boot + JPA(Hibernate) 技術的可以略過以下步驟。
a、到碼雲、GitHub上下載 xjar-agent-hibernate 項目
b、導入eclipse 打包出jar包
c、然後執行命令 xjar java -javaagent:xjar-agent-hibernate-v1.0.0.jar -jar path\wx-encrypted.jar,即可正常運行
2、maven集成 XJar
第二種方式就比較簡單了,直接在項目中引入xjar-maven-plugin,然後打包就可以了,其他操作方式和第一種類似
注意:密碼最好採用命令行方式
<pluginRepositories>
<pluginRepository>
<id>jitpack.io</id>
<url>https://jitpack.io</url>
</pluginRepository>
</pluginRepositories>
<plugin> <groupId>com.github.core-lib</groupId> <artifactId>xjar-maven-plugin</artifactId> <version>4.0.0</version> <executions> <execution> <goals> <goal>build</goal> </goals> <phase>install</phase> <configuration> <password>1233445</password> <includes>
<!----> <include>/com/xxx/xxx/**/*.class</include> </includes> <!-- 無需加密的資源路徑表達式 --> <excludes> <exclude>static/**</exclude> <exclude>META-INF/resources/**</exclude> </excludes> <!-- 源jar所在目錄 --> <sourceDir>path\</sourceDir> <!-- 源jar名稱 --> <sourceJar>xxx.jar</sourceJar> <!-- 目標jar存放目錄 --> <targetDir>path\test2</targetDir> <!-- 目標jar名稱 --> <targetJar>xxx-encrypted.jar</targetJar> </configuration> </execution> </executions> </plugin>
其實所有軟件,都可以被破解,只是破解過程是簡單還是複雜、以及破解成本的高低。
最關鍵的還是自己軟件要更新迭代的快,這樣才能把模仿者遠遠甩在身後。
轉發請註明出處!!!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧
一個大型的應用系統,往往需要眾多進程協作,進程(Linux進程概念見附1)間通信的重要性顯而易見。本系列文章闡述了 Linux 環境下的幾種主要進程間通信手段。
進程隔離是為保護操作系統中進程互不干擾而設計的一組不同硬件和軟件的技術。這個技術是為了避免進程A寫入進程B的情況發生。 進程的隔離實現,使用了虛擬地址空間。進程A的虛擬地址和進程B的虛擬地址不同,這樣就防止進程A將數據信息寫入進程B。
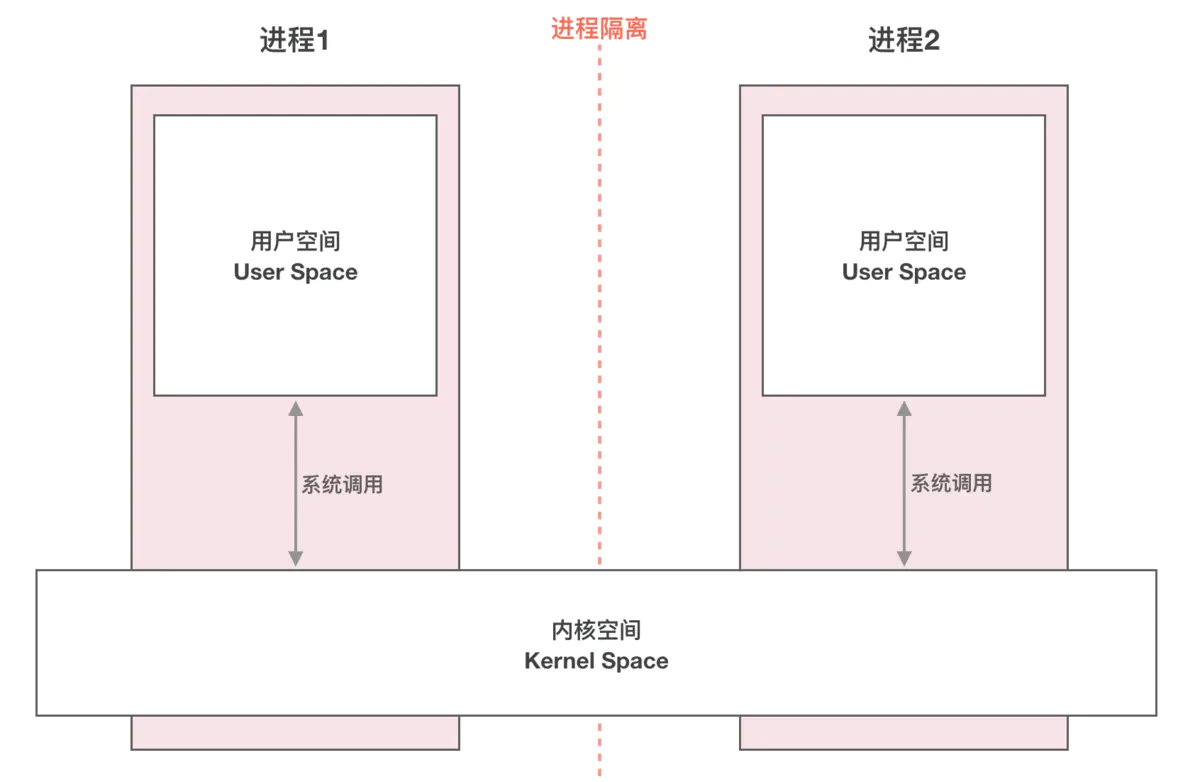
當創建一個進程時,操作系統會為該進程分配一個 4GB 大小的虛擬進程地址空間。之所以是 4GB ,是因為在 32 位的操作系統中,一個指針長度是 4 字節,而 4 字節指針的尋址能力是從 0x00000000~0xFFFFFFFF ,最大值 0xFFFFFFFF 表示的即為 4GB 大小的容量。與虛擬地址空間相對的,還有一個物理地址空間,這個地址空間對應的是真實的物理內存。要注意的是這個 4GB 的地址空間是“虛擬”的,並不是真實存在的,而且每個進程只能訪問自己虛擬地址空間中的數據,無法訪問別的進程中的數據,通過這種方法實現了進程間的地址隔離。
針對 Linux 操作系統,將最高的1G字節(從虛擬地址 0xC0000000 到 0xFFFFFFFF )供內核使用,稱為內核空間,而較低的 3G 字節(從虛擬地址 0x00000000 到0xBFFFFFFF),供各個進程使用,稱為用戶空間。每個進程都可以通過系統調用進入到內核。其中在 Linux 系統中,進程的用戶空間是獨立的,而內核空間是共有的,進程切換時,用戶空間切換,內核空間不變。
創建虛擬地址空間目的是為了解決進程地址空間隔離的問題。但程序要想執行,必須運行在真實的內存上,所以,必須在虛擬地址與物理地址間建立一種映射關係。這樣,通過映射機制,當程序訪問虛擬地址空間上的某個地址值時,就相當於訪問了物理地址空間中的另一個值。人們想到了一種分段、分頁的方法,它的思想是在虛擬地址空間和物理地址空間之間做一一映射。這種思想理解起來並不難,操作系統保證不同進程的地址空間被映射到物理地址空間中不同的區域上,這樣每個進程最終訪問到的物理地址空間都是彼此分開的。通過這種方式,就實現了進程間的地址隔離。
雖然從邏輯上抽離出用戶空間和內核空間;但是不可避免的的是,總有那麼一些用戶空間需要訪問內核的資源;比如應用程序訪問文件,網絡是很常見的事情,怎麼辦呢?
用戶空間訪問內核空間的唯一方式就是系統調用;通過這個統一入口接口,所有的資源訪問都是在內核的控制下執行,以免導致對用戶程序對系統資源的越權訪問,從而保障了系統的安全和穩定。用戶軟件良莠不齊,要是它們亂搞把系統玩壞了怎麼辦?因此對於某些特權操作必須交給安全可靠的內核來執行。
當一個任務(進程)執行系統調用而陷入內核代碼中執行時,我們就稱進程處於內核運行態(或簡稱為內核態)此時處理器處於特權級最高的(0級)內核代碼中執行。當進程在執行用戶自己的代碼時,則稱其處於用戶運行態(用戶態)。即此時處理器在特權級最低的(3級)用戶代碼中運行。處理器在特權等級高的時候才能執行那些特權CPU指令。
理解了上面的幾個概念,我們再來看看進程之間是如何實現通信的。
通常的做法是消息發送方將要發送的數據存放在內存緩存區中,通過系統調用進入內核態。然後內核程序在內核空間分配內存,開闢一塊內核緩存區,調用 copy_from_user() 函數將數據從用戶空間的內存緩存區拷貝到內核空間的內核緩存區中。同樣的,接收方進程在接收數據時在自己的用戶空間開闢一塊內存緩存區,然後內核程序調用 copy_to_user() 函數將數據從內核緩存區拷貝到接收進程的內存緩存區。這樣數據發送方進程和數據接收方進程就完成了一次數據傳輸,我們稱完成了一次進程間通信。如下圖:
Linux 進程間基本的通信方式主要有:管道(pipe) (包括匿名管道和命名管道)、信號(signal)、消息隊列(queue)、共享內存、信號量和套接字。
管道的實質是一個內核緩衝區(調用 pipe 函數來開闢),管道的作用正如其名,需要通信的兩個進程在管道的兩端,進程利用管道傳遞信息。管道對於管道兩端的進程而言,就是一個文件,但是這個文件比較特殊,它不屬於文件系統並且只存在於內存中。 Linux一切皆文件,操作系統為管道提供操作的方法:文件操作,用 fork 來共享管道原理。
管道依據是否有名字分為匿名管道和命名管道(有名管道),這兩種管道有一定的區別。
匿名管道有幾個重要的限制:
命名管道允許沒有親緣關係的進程進行通信。命名管道不同於匿名管道之處在於它提供了一個路徑名與之關聯,這樣一個進程即使與創建有名管道的進程不存在親緣關係,只要可以訪問該路徑,就能通過有名管道互相通信。
pipe 函數接受一個參數,是包含兩個整數的數組,如果調用成功,會通過 pipefd[2] 傳出給用戶程序兩個文件描述符,需要注意 pipefd[0] 指向管道的讀端, pipefd[1] 指向管道的寫端,那麼此時這個管道對於用戶程序就是一個文件,可以通過 read(pipefd [0]);或者 write(pipefd [1]) 進行操作。pipe 函數調用成功返回 0,否則返回 -1.
那麼再來看看通過管道進行通信的步驟:
只能單向通信
兩個文件描述符,用一個,另一個不用,不用的文件描述符就要 close
只能血緣關係的進程進行通信
依賴於文件系統
生命周期隨進程
面向字節流的服務
面向字節流:數據無規則,沒有明顯邊界,收發數據比較靈活:對於用戶態,可以一次性發送也可以分次發送,當然接受數據也如此;而面向數據報:數據有明顯邊界,數據只能整條接受
管道內部提供了同步機制
臨界資源: 大家都能訪問到的共享資源
臨界區: 對臨界資源進行操作的代碼
同步: 臨界資源訪問的可控時序性(一個操作完另一個才可以操作)
互斥: 對臨界資源同一時間的唯一訪問性(保護臨界資源安全)
說明:因為管道通信是單向的,在上面的例子中我們是通過子進程寫父進程來讀,如果想要同時父進程寫而子進程來讀,就需要再打開另外的管道;
管道的讀寫端通過打開的文件描述符來傳遞,因此要通信的兩個進程必須從它們的公共祖先那裡繼承管道的件描述符。 上面的例子是父進程把文件描述符傳給子進程之後父子進程之 間通信,也可以父進程fork兩次,把文件描述符傳給兩個子進程,然後兩個子進程之間通信, 總之 需要通過fork傳遞文件描述符使兩個進程都能訪問同一管道,它們才能通信。
如果所有指向管道寫端的文件描述符都關閉了,而仍然有進程從管道的讀端讀數據,那麼管道中剩餘的數據都被讀取后,再次read會返回0,就像讀到文件末尾一樣
如果有指向管道寫端的文件描述符沒關閉,而持有管道寫端的進程也沒有向管道中寫數據,這時有進程從管道讀端讀數據,那麼管道中剩餘的數據都被讀取后,再次read會阻塞,直到管道中有數據可讀了才讀取數據並返回。
如果所有指向管道讀端的文件描述符都關閉了,這時有進程指向管道的寫端write,那麼該進程會收到信號SIGPIPE,通常會導致進程異常終止。
如果有指向管道讀端的文件描述符沒關閉,而持有管道寫端的進程也沒有從管道中讀數據,這時有進程向管道寫端寫數據,那麼在管道被寫滿時再write會阻塞,直到管道中有空位置了才寫入數據並返回。
在管道中,只有具有血緣關係的進程才能進行通信,對於後來的命名管道,就解決了這個問題。FIFO 不同於管道之處在於它提供一個路徑名與之關聯,以 FIFO 的文件形式存儲於文件系統中。命名管道是一個設備文件,因此,即使進程與創建FIFO的進程不存在親緣關係,只要可以訪問該路徑,就能夠通過 FIFO 相互通信。值得注意的是, FIFO (first input first output) 總是按照先進先出的原則工作,第一個被寫入的數據將首先從管道中讀出。
命名管道的創建
創建命名管道的系統函數有兩個: mknod 和 mkfifo。兩個函數均定義在頭文件 sys/stat.h,
函數原型如下:
#include <sys/types.h> #include <sys/stat.h> int mknod(const char *path,mode_t mod,dev_t dev); int mkfifo(const char *path,mode_t mode);
函數 mknod 參數中 path 為創建的命名管道的全路徑名: mod 為創建的命名管道的模指明其存取權限; dev 為設備值,該值取決於文件創建的種類,它只在創建設備文件時才會用到。這兩個函數調用成功都返回 0,失敗都返回 -1。
命名管道打開特性:
如果用只讀打開命名管道,open 函數將阻塞等待直至有其他進程以寫的方式打開這個命名管道,如果沒有進程以寫的方式發開這個命名管道,程序將停在此處
如果用只寫打開命名管道,open 函數將阻塞等到直至有其他進程以讀的方式打開這個命名管道,如果沒有進程以讀的方式發開這個命名管道,程序將停在此處;
如果用讀寫打開命名管道,則不會阻塞(但是管道是單向)
IPC(Inter-Process Communication)是指多個進程之間相互通信,交換信息的方法,System V 是 Unix 操作系統最早的商業發行版,由 AT&T(American Telephone & Telegraph)開發。System V IPC 是指 Linux 引入自 System V 的進程通信機制,一共有三種:
信號量,用來管理對共享資源的訪問;
共享內存,用來高效地實現進程間的數據共享;
消息隊列,用來實現進程間數據的傳遞。
這三種統稱 IPC 資源,每個 IPC 資源都是請求時動態創建的,都是永駐內存,除非被進程显示釋放,都是可以被任一進程使用。每個 IPC 資源都使用一個 32 位的 IPC 關鍵字和 32 位的 IPC 標識符,前者類似文件系統中的路徑名,由程序自由定製,後者類似打開文件的文件描述符,由內核統一分配,在系統內部是唯一的,當多個進程使用同一個IPC資源通信時需要該資源的 IPC 標識符。
創建新的 IPC 資源時需要指定 IPC 關鍵字,如果沒有與之關聯的 IPC 資源,則創建一個新的 IPC 資源;如果已經存在,則判斷當前進程是否具有訪問權限,是否超過資源使用限制等,如果符合條件則返回該資源的 IPC 標識符。為了避免兩個不同的 IPC 資源使用相同的 IPC 關鍵字,創建時可以指定IPC關鍵字為 IPC_PRIVATE,由內核負責生成一個唯一的關鍵字。
創建新的 IPC 資源時最後一個參數可以包括三個標誌,PC_CREAT 說明如果IPC資源不存在則必須創建它,IPC_EXCL 說明如果資源已經存在且設置了 PC_CREAT 標誌則創建失敗,IPC_NOWAIT 說明訪問 IPC 資源時進程從不阻塞。
信號量(semaphore)是一種用於提供不同進程之間或者一個給定的不同線程間同步手段的原語。信號量多用於進程間的同步與互斥,簡單的說一下同步和互斥的意思:
同步:處理競爭就是同步,安排進程執行的先後順序就是同步,每個進程都有一定的先後執行順序。
互斥:互斥訪問不可共享的臨界資源,同時會引發兩個新的控制問題(互斥可以說是特殊的同步)。
競爭:當併發進程競爭使用同一個資源的時候,我們就稱為競爭進程。
共享資源通常分為兩類:一類是互斥共享資源,即任一時刻只允許一個進程訪問該資源;另一類是同步共享資源,即同一時刻允許多個進程訪問該資源;信號量是解決互斥共享資源的同步問題而引入的機制。
下面說一下信號量的工作機制,可以直接理解成計數器(當然其實加鎖的時候肯定不能這麼簡單,不只只是信號量了),信號量會有初值(>0),每當有進程申請使用信號量,通過一個 P 操作來對信號量進行-1操作,當計數器減到 0 的時候就說明沒有資源了,其他進程要想訪問就必須等待(具體怎麼等還有說法,比如忙等待或者睡眠),當該進程執行完這段工作(我們稱之為臨界區)之後,就會執行 V 操作來對信號量進行 +1 操作。
臨界區:臨界區指的是一個訪問共用資源(例如:共用設備或是共用存儲器)的程序片段,而這些共用資源又無法同時被多個線程訪問的特性。
臨界資源:只能被一個進程同時使用(不可以多個進程共享),要用到互斥。
我們可以說信號量也是進程間通信的一種方式,比如互斥鎖的簡單實現就是信號量,一個進程使用互斥鎖,並通知(通信)其他想要該互斥鎖的進程,阻止他們的訪問和使用。
當有進程要求使用共享資源時,需要執行以下操作:
系統首先要檢測該資源的信號量;
若該資源的信號量值大於 0,則進程可以使用該資源,此時,進程將該資源的信號量值減1;
若該資源的信號量值為 0,則進程進入休眠狀態,直到信號量值大於 0 時進程被喚醒,訪問該資源;
當進程不再使用由一個信號量控制的共享資源時,該信號量值增加 1,如果此時有進程處於休眠狀態等待此信號量,則該進程會被喚醒
每個信號量集都有一個與其相對應的結構,該結構定義如下:
/* Data structure describing a set of semaphores. */ struct semid_ds { struct ipc_perm sem_perm; /* operation permission struct */ struct sem *sem_base; /* ptr to array of semaphores in set */ unsigned short sem_nsems; /* # of semaphores in set */ time_t sem_otime; /* last-semop() time */ time_t sem_ctime; /* last-change time */ }; /* Data structure describing each of semaphores. */ struct sem { unsigned short semval; /* semaphore value, always >= 0 */ pid_t sempid; /* pid for last successful semop(), SETVAL, SETALL */ unsigned short semncnt; /* # processes awaiting semval > curval */ unsigned short semzcnt; /* # processes awaiting semval == 0 */ };
信號量集的結構圖如下所示:
消息隊列,是消息的鏈接表,存放在內核中。一個消息隊列由一個標識符(即隊列 ID)來標識。其具有以下特點:
消息隊列是面向記錄的,其中的消息具有特定的格式以及特定的優先級。
消息隊列獨立於發送與接收進程。進程終止時,消息隊列及其內容並不會被刪除。
消息隊列可以實現消息的隨機查詢,消息不一定要以先進先出的次序讀取,也可以按消息的類型讀取。
1 #include <sys/msg.h> 2 // 創建或打開消息隊列:成功返回隊列ID,失敗返回-1 3 int msgget(key_t key, int flag); 4 // 添加消息:成功返回0,失敗返回-1 5 int msgsnd(int msqid, const void *ptr, size_t size, int flag); 6 // 讀取消息:成功返回消息數據的長度,失敗返回-1 7 int msgrcv(int msqid, void *ptr, size_t size, long type,int flag); 8 // 控制消息隊列:成功返回0,失敗返回-1 9 int msgctl(int msqid, int cmd, struct msqid_ds *buf);
在以下兩種情況下,msgget 將創建一個新的消息隊列:
如果沒有與鍵值key相對應的消息隊列,並且flag中包含了IPC_CREAT標誌位。
key參數為IPC_PRIVATE。
函數msgrcv在讀取消息隊列時,type參數有下面幾種情況:
type == 0,返回隊列中的第一個消息;
type > 0,返回隊列中消息類型為 type 的第一個消息;
type < 0,返回隊列中消息類型值小於或等於 type 絕對值的消息,如果有多個,則取類型值最小的消息。
可以看出,type 值非 0 時用於以非先進先出次序讀消息。也可以把 type 看做優先級的權值。
共享內存是 System V 版本的最後一個進程間通信方式。共享內存,顧名思義就是允許兩個不相關的進程訪問同一個邏輯內存,共享內存是兩個正在運行的進程之間共享和傳遞數據的一種非常有效的方式。不同進程之間共享的內存通常為同一段物理內存。進程可以將同一段物理內存連接到他們自己的地址空間中,所有的進程都可以訪問共享內存中的地址。如果某個進程向共享內存寫入數據,所做的改動將立即影響到可以訪問同一段共享內存的任何其他進程。
特別提醒:共享內存並未提供同步機制,也就是說,在第一個進程結束對共享內存的寫操作之前,並無自動機制可以阻止第二個進程開始對它進行讀取,所以我們通常需要用其他的機制來同步對共享內存的訪問,例如信號量。
共享內存的通信原理
在 Linux 中,每個進程都有屬於自己的進程控制塊(PCB)和地址空間(Addr Space),並且都有一個與之對應的頁表,負責將進程的虛擬地址與物理地址進行映射,通過內存管理單元(MMU)進行管理。兩個不同的虛擬地址通過頁表映射到物理空間的同一區域,它們所指向的這塊區域即共享內存。
共享內存的通信原理示意圖:
對於上圖我的理解是:當兩個進程通過頁表將虛擬地址映射到物理地址時,在物理地址中有一塊共同的內存區,即共享內存,這塊內存可以被兩個進程同時看到。這樣當一個進程進行寫操作,另一個進程讀操作就可以實現進程間通信。但是,我們要確保一個進程在寫的時候不能被讀,因此我們使用信號量來實現同步與互斥。
對於一個共享內存,實現採用的是引用計數的原理,當進程脫離共享存儲區后,計數器減一,掛架成功時,計數器加一,只有當計數器變為零時,才能被刪除。當進程終止時,它所附加的共享存儲區都會自動脫離。
為什麼共享內存速度最快?
藉助上圖說明:Proc A 進程給內存中寫數據, Proc B 進程從內存中讀取數據,在此期間一共發生了兩次複製
(1)Proc A 到共享內存 (2)共享內存到 Proc B
因為直接在內存上操作,所以共享內存的速度也就提高了。
共享內存的接口函數以及指令
查看系統中的共享存儲段
ipcs -m
刪除系統中的共享存儲段
ipcrm -m [shmid]
shmget ( ):創建共享內存
int shmget(key_t key, size_t size, int shmflg);
[參數key]:由ftok生成的key標識,標識系統的唯一IPC資源。
[參數size]:需要申請共享內存的大小。在操作系統中,申請內存的最小單位為頁,一頁是4k字節,為了避免內存碎片,我們一般申請的內存大小為頁的整數倍。
[參數shmflg]:如果要創建新的共享內存,需要使用IPC_CREAT,IPC_EXCL,如果是已經存在的,可以使用IPC_CREAT或直接傳0。
[返回值]:成功時返回一個新建或已經存在的的共享內存標識符,取決於shmflg的參數。失敗返回-1並設置錯誤碼。
shmat ( ):掛接共享內存
void *shmat(int shmid, const void *shmaddr, int shmflg);
[參數shmid]:共享存儲段的標識符。
[參數*shmaddr]:shmaddr = 0,則存儲段連接到由內核選擇的第一個可以地址上(推薦使用)。
[參數shmflg]:若指定了SHM_RDONLY位,則以只讀方式連接此段,否則以讀寫方式連接此段。
[返回值]:成功返回共享存儲段的指針(虛擬地址),並且內核將使其與該共享存儲段相關的shmid_ds結構中的shm_nattch計數器加1(類似於引用計數);出錯返回-1。
shmdt ( ):去關聯共享內存:當一個進程不需要共享內存的時候,就需要去關聯。該函數並不刪除所指定的共享內存區,而是將之前用shmat函數連接好的共享內存區脫離目前的進程。
int shmdt(const void *shmaddr);
[參數*shmaddr]:連接以後返回的地址。
[返回值]:成功返回0,並將shmid_ds結構體中的 shm_nattch計數器減1;出錯返回-1。
shmctl ( ):銷毀共享內存
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
[參數shmid]:共享存儲段標識符。
[參數cmd]:指定的執行操作,設置為IPC_RMID時表示可以刪除共享內存。
[參數*buf]:設置為NULL即可。
[返回值]:成功返回0,失敗返回-1。
POSIX 消息隊列是 POSIX 標準在 2001 年定義的一種 IPC 機制,與 System V 中的消息隊列相比有如下差異:
更簡單的基於文件的應用接口,Linux 通過 mqueue 的特殊文件系統來實現消息隊列,隊列名跟文件名類似,必須以”/”開頭,每個消息隊列在文件系統內都有一個對應的索引節點,返回的隊列描述符實際是一個文件描述符
完全支持消息優先級,消息在隊列中是按照優先級倒序排列的(即0表示優先級最低)。當一條消息被添加到隊列中時,它會被放置在隊列中具有相同優先級的所有消息之後。如果一個應用程序無需使用消息優先級,那麼只需要將msg_prio指定為0即可。
完全支持消息到達的異步通知,當新消息到達且當前隊列為空時會通知之前註冊過表示接受通知的進程。在任何一個時刻都只有一個進程能夠向一個特定的消息隊列註冊接收通知。如果一個消息隊列上已經存在註冊進程了,那麼後續在該隊列上的註冊請求將會失敗。可以給進程發送信號或者另起一個線程調用通知函數完成通知。當通知完成時,註冊即被撤銷,進程需要繼續接受通知則必須重新註冊。
用於阻塞發送與接收操作的超時機制,可以指定阻塞的最長時間,超時自動返回
套接字是更為基礎的進程間通信機制,與其他方式不同的是,套接字可用於不同機器之間的進程間通信。
有兩種類型的套接字:基於文件的和面向網絡的。
Unix 套接字是基於文件的,並且擁有一個“家族名字”–AF_UNIX,它代表地址家族 (address family):UNIX。
第二類型的套接字是基於網絡的,它也有自己的家族名字–AF_INET,代表地址家族 (address family):INTERNET
不管採用哪種地址家族,都有兩種不同的套接字連接:面向連接的和無連接的。
這意味着每條信息可以被拆分成多個片段,並且每個片段都能確保到達目的地,然後在目的地將信息拼接起來。
實現這種連接類型的主要協議是傳輸控制協議 (TCP)。
然而,數據報確實保存了記錄邊界,這就意味着消息是以整體發送的,而並非首先分成多個片段。
由於面向連接的套接字所提供的保證,因此它們的設置以及對虛擬電路連接的維護需要大量的開銷。然而,數據報不需要這些開銷,即它的成本更加“低廉”
實現這種連接類型的主要協議是用戶數據報協議 (UDP)。
信號是軟件層次上對中斷機制的一種模擬,是一種異步通信方式,進程不必通過任何操作來等待信號的到達。信號可以在用戶空間進程和內核之間直接交互,內核可以利用信號來通知用戶空間的進程發生了哪些系統事件。
信號來源:
信號事件的發生有兩個來源:硬件來源,比如我們按下了鍵盤或者其它硬件故障;軟件來源,最常用發送信號的系統函數是 kill, raise, alarm 和 setitimer 以及 sigqueue 函數,軟件來源還包括一些非法運算等操作。
進程對信號的響應:
進程可以通過三種方式來響應信號:
忽略信號,即對信號不做任何處理,但是有兩個信號是不能忽略的:SIGKLL 和 SIGSTOP;
捕捉信號,定義信號處理函數,當信號發生時,執行相應的處理函數;
執行缺省操作,Linux 對每種信號都規定了默認操作。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
本文致力於介紹K8s一些基礎概念與串聯部署應用的主體流程,使用Minikube實操
溫故而知新,上一節【K8S學習筆記】初識K8S 及架構組件 我們學習了K8s的發展歷史、基礎架構概念及用途,本節講的內容建立在其上,有必要把之前的架構小節提出來回顧下:
K8s架構分為控制平台(位於的Master節點)與執行節點Node
控制平台包含:
kube-apiserver(訪問入口,接收命令)
etcd(KV數據庫,保存集群狀態與數據)
kube-scheduler(監控節點狀態,調度容器部署)
kube-controller-manager(監控集群狀態,控制節點、副本、端點、賬戶與令牌)
cloud-controller-manager(控制與雲交互的節點、路由、服務、數據卷)
執行節點包含:
kubelet(監控與實際操作容器)
kube-proxy(每個節點上運行的網絡代理,維護網絡轉發規則,實現了Service)
容器運行時環境CRI(支持多種實現K8s CRI的容器技術)
接下來需要引入 Pod 與 Service 的概念,這也是在上一篇文章中未給出的
Pod 是 K8s最重要的基本概念,官網給出概念:Pod是Kubernates可調度的最小的、可部署的單元。怎麼理解呢?最簡單的理解是,Pod是一組容器。
再詳細些,Pod是一組容器組成的概念,這些容器都有共同的特點:
下邊是Pod的組成示意圖:
為什麼Kubernetes會設計出一個全新的概念與Pod會有這樣特殊的結構呢?
K8s為每個Pod都分配了唯一的IP地址,稱為Pod IP,一個Pod里的多個容器共享Pod IP地址。需要牢記的一點是:在 kubernetes 里,一個 Pod 里的容器與另外主機上的 Pod 容器能夠直接通信。
當一個普通的Pod被創建,就會被放入etcd中存儲,隨後被 K8s Master節點調度到某個具體的Node上並進行綁定(Binding),隨後該Pod被對應的Node上的kubelet進程實例化成一組相關的Docker容器並啟動。
當Pod中有容器停止時,K8s 會自動檢測到這個問題並重啟這個 Pod(Pod里所有容器);如果Pod所在的Node宕機,就會將這個Node上的所有Pod重新調度到其他節點上。
細心的讀者是否發現:
當Pod越來越多,Pod IP 也越來越多,那是如何從茫茫IP地址中找到需要的服務呢?換句話來說,是否有一種提供唯一入口的機制,來完成對Pod的訪問,而無需關心訪問到具體是哪個Pod(who care :happy:)?
Kubernetes 提供了這種機制,稱之為 Service。
Service服務是Kubernetes里的核心資源對象之一,從名稱上來看,理解其為一個”服務“也不為過,Service的作用是為相同標識的一系列Pod提供唯一的訪問地址。
Service使用的唯一地址稱為ClusterIP,僅當在集群內的容器才能通過此IP訪問到Service
它具體實現對一系列Pod綁定,需要再引入Label的概念,才能做出解答。
Kubernetes 提供了Label(標籤)來對Pod、Service、RC、Node等進行標記。相當於打標籤,Label可以是一組KV鍵值對,也可以是一個set
一個資源對象可以定義任意數量的Label,同一個Label可以添加到任意數量的資源對象上。通常由定義資源對象時添加,創建后亦可動態添加或刪除。
原來,在定義 Pod 時,設置一系列 Label 標籤,Service 創建時定義了 Label Selector(Label Selector 可以類比為對 Label 進行 SQL 的 where 查詢),kube-proxy 進程通過 Service的Label Selector 來選擇對應的 Pod,自動建立每個 Service 到對應 Pod 的請求轉發路由表,從而實現 Service 的智能負載均衡機制。
小結:Pod是K8s最小的執行單元,包含一個Pause容器與多個業務容器,每個Pod中容器共享Pod IP,容器之間可直接作用Pod IP通信;Label是一種標籤,它將標籤打在Pod上時,Service可以通過定義Label Selector(Label查詢規則)來選擇Pod,具體實現路由表建立的是kube-proxy
安裝kubectl需要安裝成本地服務,這裡是debian10,更多參考https://developer.aliyun.com/mirror/kubernetes
sudo su -
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubectl
exit
下載安裝Minikube(阿里雲修改版):
curl -Lo minikube-linux-amd64-1.11.0-aliyuncs http://kubernetes.oss-cn-hangzhou.aliyuncs.com/minikube/releases/v1.11.0/minikube-linux-amd64
sudo install minikube-linux-amd64-1.11.0-aliyuncs /usr/local/bin/minikube
使用魔改版是因為官方代碼里有些地方寫死了地址,而國內無法訪問
部署k8s集群:
minikube start --driver docker --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --kubernetes-version v1.18.3
本地有docker時使用此driver,其他可選的虛擬化技術參考https://minikube.sigs.k8s.io/docs/drivers/ 選擇
#部署一個Pod,Pod的deployment是一種默認的無狀態多備份的部署類型
kubectl create deployment hello-minikube --image=registry.cn-hangzhou.aliyuncs.com/google_containers/echoserver:1.4
#查看集群中當前的Pod列表
kubectl get pods
#創建的NodePort類型Service,將所有Node開放一個端口號,通過這個端口將流量轉發到Service以及下游Pods
kubectl expose deployment hello-minikube --type=NodePort --port=8080
#獲取暴露 Service 的 URL 以查看 Service 的詳細信息:
minikube service hello-minikube --url
#minikube提供的特色功能,直接通過瀏覽器打開剛才創建的Service的外部訪問地址
minikube service hello-minikube
自動打開瀏覽器訪問服務(Minikube特色功能)
提示:這張圖中的request-uri的解釋是不正確的,但是與
<minikube這個唯一Node的IP>:<NodePort>與<Service的ClusterIP>:<ServicePort>都不是完全匹配的,不大理解這塊提示,有緣人希望可解我所惑,在此先行感謝
查看Pod的描述信息
kubectl describe pod hello-minikube
最下方可以清楚得看到K8s集群default-scheduler成功指派我們要求的Pod在節點minikube上創建,kubelet收到信息后,拉取鏡像並啟動了容器
kubectl 發送創建 deployment 類型、名為hello-minikube的Pod 請求到 kube-apiserverkube-apiserver 將這條描述信息存到 etcdkube-scheduler 監控 etcd 得到描述信息,監測Node負載情況,創建Pod部署描述信息到etcdkubelet監聽到 etcd 中有自己的部署Pod信息,取出信息並按圖拉取業務鏡像,創建pause容器與業務容器(此時集群外部無法訪問)kubectl 執行expose命令,同時將創建Service與NodePort信息存到etcd中kube-proxy監聽到etcd變化,創建邏輯上的Service與路由信息,開闢NodePort<任意Node節點IP>:<NodePort> 時,根據路由錶轉發到指定的Service上,負載均衡到Pod,提供服務集群外部訪問:
參考
行文過程中難免出現錯誤,還請讀者評論幫忙改正,大家共同進步,在此感謝
轉載請註明出處,文章中概念引入《Kubernetes權威指南》很多,侵權改。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧