環境資訊中心特約記者 陳文姿報導
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧

氫燃料電池目前已應用在汽車、公車甚至是列車中,為備受看好的化石燃料替代品,各國也紛紛將氫燃料交通運輸納入未來藍圖,像是全球首輛商業運行氫燃料列車已在德國漢諾威上路,除了為氫燃料列車立下新里程碑,也讓德國離減碳目標更進一步。
該氫燃料列車名為 CORADIA iLINT,由法商阿爾斯通(Alstom)一手開發,於 2016年首次亮相德國柏林 InnoTrans 貿易展,2017 年 3 月更在德國完成首航測試,漢諾威當地鐵路公司 LNVG 於在同年 9 月斥資 8,100 萬歐元訂購 14 輛 CORADIA iLINT。
目前德國漢諾威民眾已經可在下薩克森邦(Lower Saxony)鐵路系統乘坐世界第一批、共 2 輛氫燃料列車,預計 14 輛 CORADIA iLINT 將於 2021 年全面上路,並行駛於庫克斯港、不萊梅港、布雷梅爾弗爾德、布克斯特胡德之間的鐵路線。
CORADIA iLINT 可乘載 300 人,最高時速 140 公里,續航距離與柴油列車相同為 1,000 公里,每組氫燃料槽重達 94 公斤,而雖然氫燃料列車成本較高,但行駛途中只會排出水,沒有排放廢氣與二氧化碳問題,預估可在 10 年左右達成損益兩平。
圖片來源:
該氫燃料列車外觀跟傳統列車相差無幾,如果不是車體外觀滿滿的 H 與 O 化學鍵符號,乍看之下就是一般的藍色列車,但其實其中暗藏玄機,每節車輛頂部都設有氫燃料箱與氧燃料箱,透過燃料電池來產生電力,最後再由車底部的鋰離子電池驅動火車,多餘電力也可儲存起來增加能源使用效率。
該列車還搭載智慧電源管理系統,燃料電池會在列車行駛時穩定供應電力,而列車煞車或是停止時,會立刻停止燃料電池轉換,可節省氫氣消耗量。阿爾斯通開發人員 Jens Sprotte 表示,與傳統柴油火車相比,CORADIA iLINT 噪音降低 60%,乘客只會聽到車輪與風的聲音。
目前德國約有 40% 鐵路未實現電氣化,若是可將 4,000 輛柴油列車全部汰換成氫燃料電池列車,除了能減少 45% 排碳量,還可以免除鐵路電氣化所需的電纜、配電成本。
不過氫燃料列車也有許多挑戰待克服,由於氫燃料技術尚未成熟,能量轉換率還不高、最高時速只能達到每小時 140 公里,且氫氣製程仍無法擺脫化石燃料,純氫氣需要加工才可獲得,阿爾斯通公司表示,計劃之後使用下薩克森邦龐大風力發電系統的電力來製造所需的氫燃料。
德國推行節能減碳與再生能源不遺餘力,計劃在 2030 將再生能源發電比例提升至 65%,而阿爾斯通也有其雄心勃勃目標,望可在在未來 5-20 年間汰換掉德國所有的柴油列車,讓德國鐵路朝零碳邁進。
(首圖來源:。文/DaisyChuang)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

光陽(Kymco)日前宣布要進軍印度市場,現在揭曉將聯手印度電動車新創 22Motors。未來 22Motors 的 Flow scooter 車款將全面採用 Kymco Ionex 車能網,成為光陽插旗印度的夥伴。
2018 年以來電動機車市場就異常熱鬧,機車大廠光陽與 Gogoro 之間正面交鋒的態勢已經日漸明朗。雙方也各自找來友軍助陣,Gogoro 選擇和國產機車三雄之一的 Yamaha 結盟,光陽則在中國與阿里巴巴合作,如今又攜手印度的 22Motors。光陽這次與 22Motors 的合作也是著眼於印度政府在 2030 年前銷售新燃油車的調控政策,試圖在全球最大機車市場電動化的過程中搶得一席之地。
光陽指出印度新創電動車公司 22Motors 具有優異的技術能力,不僅解決了鋰離子電池開發和電池管理系統(BMS)等問題,還擁有高效率的快速充電系統,並開發 AI 和機器學習功能。光陽表示,在 3 月的 Ionex 東京發表會之後,22Motors 便前來積極接洽雙方的合作,打造一台會思考且有學習能力的 AI Scooter 智慧電動車。能夠跨足世界最大的機車市場無疑對光陽是一劑強心針,未來兩大陣營將會如何交手值得繼續觀察。
(合作媒體:。首圖來源:)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
作為一個數據庫愛好者,自己動手寫過簡單的SQL解析器以及存儲引擎,但感覺還是不夠過癮。<<事務處理-概念與技術>>誠然講的非常透徹,但只能提綱挈領,不能讓你玩轉某個真正的數據庫。感謝cmake,能夠讓我在mac上用xcode去debug MySQL,從而能去領略它的各種實現細節。
筆者一直對數據庫的隔離性很好奇,此篇博客就是我debug MySQL過程中的偶有所得。
(注:本文的MySQL採用的是MySQL-5.6.35版本)
隔離性也可以被稱作併發控制、可串行化等。談到併發控制首先想到的就是鎖,MySQL通過使用兩階段鎖的方式實現了更新的可串行化,同時為了加速查詢性能,採用了MVCC(Multi Version Concurrency Control)的機制,使得不用鎖也可以獲取一致性的版本。
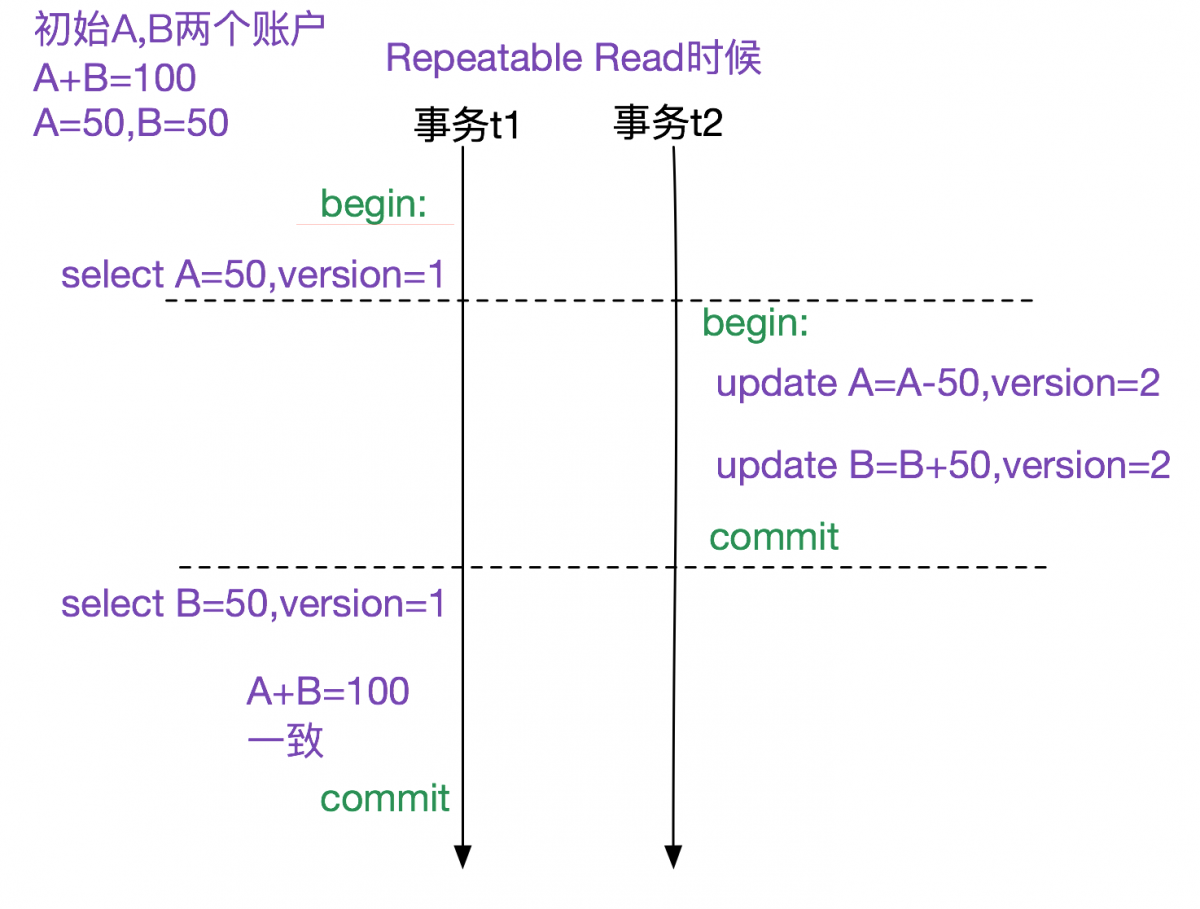
MySQL的通過MVCC以及(Next-Key Lock)實現了可重複讀(Repeatable Read),其思想(MVCC)就是記錄數據的版本變遷,通過精巧的選擇不同數據的版本從而能夠對用戶呈現一致的結果。如下圖所示:
上圖中,(A=50|B=50)的初始版本為1。
1.事務t1在select A時候看到的版本為1,即A=50
2.事務t2對A和B的修改將版本升級為2,即A=0,B=100
3.事務t1再此select B的時候看到的版本還是1, 即B=50
這樣就隔離了版本的影響,A+B始終為100。
而如果不通過版本控制機制,而是讀到最近提交的結果的話,則隔離級別是read commit,如下圖所示:
在這種情況下,就需要使用鎖機制(例如select for update)將此A,B記錄鎖住,從而獲得正確的一致結果,如下圖所示:
當我們要對一些數據做一些只讀操作來檢查一致性,例如檢查賬務是否對齊的操作時候,並不希望加上對性能損耗很大的鎖。這時候MVCC的一致性版本就有很大的優勢了。
本節就開始談談MVCC的實現機制,注意MVCC僅僅在純select時有效(不包括select for update,lock in share mode等加鎖操作,以及update\insert等)。
首先我們追蹤一下一條普通的查詢sql在mysql源碼中的運行過程,sql為(select * from test);
其運行棧為:
handle_one_connection MySQL的網絡模型是one request one thread
|-do_handle_one_connection
|-do_command
|-dispatch_command
|-mysql_parse 解析SQL
|-mysql_execute_command
|-execute_sqlcom_select 執行select語句
|-handle_select
...一堆parse join 等的操作,當前並不關心
|-*tab->read_record.read_record 讀取記錄
由於mysql默認隔離級別是repeatable_read(RR),所以read_record重載為
rr_sequential(當前我們並不關心select通過index掃描出row之後再通過condition過濾的過程)。繼續追蹤:
read_record
|-rr_sequential
|-ha_rnd_next
|-ha_innobase::rnd_next 這邊就已經到了innodb引擎了
|-general_fetch
|-row_search_for_mysql
|-lock_clust_rec_cons_read_sees 這邊就是判斷並選擇版本的地方
讓我們看下該函數內部:
bool lock_clust_rec_cons_read_sees(const rec_t* rec /*由innodb掃描出來的一行*/,....){
...
// 從當前掃描的行中獲取其最後修改的版本trx_id(事務id)
trx_id = row_get_rec_trx_id(rec, index, offsets);
// 通過參數(一致性快照視圖和事務id)決定看到的行快照
return(read_view_sees_trx_id(view, trx_id));
}
我們先關注一致性視圖的創建過程,我們先看下read_view結構:
struct read_view_t{
// 由於是逆序排列,所以low/up有所顛倒
// 能看到當前行版本的高水位標識,>= low_limit_id皆不能看見
trx_id_t low_limit_id;
// 能看到當前行版本的低水位標識,< up_limit_id皆能看見
trx_id_t up_limit_id;
// 當前活躍事務(即未提交的事務)的數量
ulint n_trx_ids;
// 以逆序排列的當前獲取活躍事務id的數組
// 其up_limit_id<tx_id<low_limit_id
trx_id_t* trx_ids;
// 創建當前視圖的事務id
trx_id_t creator_trx_id;
// 事務系統中的一致性視圖鏈表
UT_LIST_NODE_T(read_view_t) view_list;
};
然後通過debug,發現創建read_view結構也是在上述的rr_sequential中操作的,繼續跟蹤調用棧:
rr_sequential
|-ha_rnd_next
|-rnd_next
|-index_first 在start_of_scan為true時候走當前分支index_first
|-index_read
|-row_search_for_mysql
|-trx_assign_read_view
我們看下row_search_for_mysql里的一個分支:
row_search_for_mysql:
// 這邊只有select不加鎖模式的時候才會創建一致性視圖
else if (prebuilt->select_lock_type == LOCK_NONE) { // 創建一致性視圖
trx_assign_read_view(trx);
prebuilt->sql_stat_start = FALSE;
}
上面的註釋就是select for update(in share model)不會走MVCC的原因。讓我們進一步分析trx_assign_read_view函數:
trx_assign_read_view
|-read_view_open_now
|-read_view_open_now_low
好了,終於到了創建read_view的主要階段,主要過程如下圖所示:
代碼過程為:
static read_view_t* read_view_open_now_low(trx_id_t cr_trx_id,mem_heap_t* heap)
{
read_view_t* view;
// 當前事務系統中max_trx_id(即尚未被分配的trx_id)設置為low_limit_no
view->low_limit_no = trx_sys->max_trx_id;
view->low_limit_id = view->low_limit_no;
// CreateView構造函數,會將非當前事務和已經在內存中提交的事務給剔除,即判斷條件為
// trx->id != m_view->creator_trx_id&& !trx_state_eq(trx, TRX_STATE_COMMITTED_IN_MEMORY)的
// 才加入當前視圖列表
ut_list_map(trx_sys->rw_trx_list, &trx_t::trx_list, CreateView(view));
if (view->n_trx_ids > 0) {
// 將當前事務系統中的最小id設置為up_limit_id,因為是逆序排列
view->up_limit_id = view->trx_ids[view->n_trx_ids - 1];
} else {
// 如果當前沒有非當前事務之外的活躍事務,則設置為low_limit_id
view->up_limit_id = view->low_limit_id;
}
// 忽略purge事務,purge時,當前事務id是0
if (cr_trx_id > 0) {
read_view_add(view);
}
// 返回一致性視圖
return(view);
}
由上面的lock_clust_rec_cons_read_sees可知,行版本可見性由read_view_sees_trx_id函數判斷:
/*********************************************************************//**
Checks if a read view sees the specified transaction.
@return true if sees */
UNIV_INLINE
bool
read_view_sees_trx_id(
/*==================*/
const read_view_t* view, /*!< in: read view */
trx_id_t trx_id) /*!< in: trx id */
{
if (trx_id < view->up_limit_id) {
return(true);
} else if (trx_id >= view->low_limit_id) {
return(false);
} else {
ulint lower = 0;
ulint upper = view->n_trx_ids - 1;
ut_a(view->n_trx_ids > 0);
do {
ulint mid = (lower + upper) >> 1;
trx_id_t mid_id = view->trx_ids[mid];
if (mid_id == trx_id) {
return(FALSE);
} else if (mid_id < trx_id) {
if (mid > 0) {
upper = mid - 1;
} else {
break;
}
} else {
lower = mid + 1;
}
} while (lower <= upper);
}
return(true);
}
其實上述函數就是一個二分法,read_view其實保存的是當前活躍事務的所有事務id,如果當前行版本對應修改的事務id不在當前活躍事務裏面的話,就返回true,表示當前版本可見,否則就是不可見,如下圖所示。
接上述lock_clust_rec_cons_read_sees的返回:
if (UNIV_LIKELY(srv_force_recovery < 5)
&& !lock_clust_rec_cons_read_sees(
rec, index, offsets, trx->read_view)){
// 當前處理的是當前版本不可見的情況
// 通過undolog來返回到一致的可見版本
err = row_sel_build_prev_vers_for_mysql(
trx->read_view, clust_index,
prebuilt, rec, &offsets, &heap,
&old_vers, &mtr);
} else{
// 可見,然後返回
}
我們現在考察一下row_sel_build_prev_vers_for_mysql函數:
row_sel_build_prev_vers_for_mysql
|-row_vers_build_for_consistent_read
主要是調用了row_ver_build_for_consistent_read方法返回可見版本:
dberr_t row_vers_build_for_consistent_read(...)
{
......
for(;;){
err = trx_undo_prev_version_build(rec, mtr,version,index,*offsets, heap,&prev_version);
......
trx_id = row_get_rec_trx_id(prev_version, index, *offsets);
// 如果當前row版本符合一致性視圖,則返回
if (read_view_sees_trx_id(view, trx_id)) {
......
break;
}
// 如果當前row版本不符合,則繼續回溯上一個版本(回到for循環的地方)
version = prev_version;
}
......
}
整個過程如下圖所示:
至於undolog怎麼恢復出對應版本的row記錄就又是一個複雜的過程了,由於篇幅原因,在此略過不表。
在創建一致性視圖的row_search_for_mysql的代碼中
// 只有非鎖模式的select才創建一致性視圖
else if (prebuilt->select_lock_type == LOCK_NONE) { // 創建一致性視圖
trx_assign_read_view(trx);
prebuilt->sql_stat_start = FALSE;
}
trx_assign_read_view中由這麼一段代碼
// 一致性視圖在一個事務只創建一次
if (!trx->read_view) {
trx->read_view = read_view_open_now(
trx->id, trx->global_read_view_heap);
trx->global_read_view = trx->read_view;
}
所以綜合這兩段代碼,即在一個事務中,只有第一次運行select(不加鎖)的時候才會創建一致性視圖,如下圖所示:
筆者構造了此種場景模擬過,確實如此。
MySQL是通過MVCC和二階段鎖(2PL)來兼顧性能和一致性的,但是由於MySQL僅僅在select時候才創建一致性視圖,而在update等加鎖操作的時候並不做如此操作,所以就會產生一些詭異的現象。如下圖所示:
如果理解了update不走一致性視圖(read_view),而select走一致性視圖(read_view),就可以很好解釋這個現象。
如下圖所示:
MySQL為了兼顧性能和ACID使用了大量複雜的機制,2PL(兩階段鎖)和MVCC就是其實現的典型。幸好可以通過xcode等IDE進行方便的debug,這樣就可以非常精確加便捷的追蹤其各種機制的實現。希望這篇文章能夠幫助到喜歡研究MySQL源碼的讀者們。
關注筆者公眾號,獲取更多乾貨文章:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

需求:遍歷文件夾下的所有pdf文件,對每個pdf文件根據二維碼進行分割,再對分割后的文件的內容進行識別。
可以拆分為以下幾個關鍵方法:
1.GetFileList方法:遍歷文件,獲取源文件動態數組(這裏假設3個文件夾,每個文件夾下有3個文件,則源文件個數為9),耗時忽略不計
1 static List<string> GetFileList(string strFilefolder) 2 { 3 List<string> list_file = new List<string>(); 4 5 for (int i = 0; i <= 2; i++) 6 { 7 for (int j = 0; j <= 2; j++) 8 list_file.Add("File" + i + j); 9 } 10 11 return list_file; 12 }
View Code
2.SplitProcess方法:分割原始pdf文件,識別二維碼(假設耗時500ms),將一個pdf文件分割為N(這裏假設個數為6)個子文件
1 static void SplitProcess(string sourcefile) 2 { 3 Console.WriteLine("SplitFile Start:" + sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 4 for (int i = 0; i <= 5; i++) 5 { 6 //模擬分割單個文件的過程,花費500ms 7 Thread.Sleep(500); 8 string split_file = sourcefile + i; 9 Console.WriteLine("file ready:" + split_file + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 10 RecognizeProcess(split_file); 11 } 12 Console.WriteLine("SplitFile Completed:" + sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 13 }
View Code
3.RecognizeProcess方法:識別子文件的內容:加載識別庫,設置識別參數,截取識別區域圖像,圖像處理(如縮放,降噪,灰度轉換等),識別(假設耗時5000ms)
1 static void RecognizeProcess(string split_file) 2 { 3 //模擬識別的過程,花費5000ms 4 Thread.Sleep(5000); 5 Console.WriteLine("ocrFile Completed:" + split_file + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 6 }
View Code
單線程處理:
1 static void Main(string[] args) 2 { 3 Console.WriteLine("Enter Main" + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 4 string strFilefolder = ""; 5 OcrProcess(strFilefolder); 6 Console.WriteLine("Main Completed" + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 7 Console.ReadKey(); 8 } 9 10 static void OcrProcess(string strFilefolder) 11 { 12 List<string> list_sourcefile = GetFileList(strFilefolder); 13 list_sourcefile.ForEach((sourcefile) => 14 { 15 Console.WriteLine(sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 16 //這裏對文件進行分割 17 SplitProcess(sourcefile); 18 }); 19 }
View Code
這個單線程處理的執行結果我們可以預估一下,應該大於 9 * 6 * (0.5 + 5) = 297 秒。
實際結果:
……
開始時間 2020-06-17 15:22:28 6104 結束時間 2020-06-17 15:27:26 1541
由於是線性處理,整個過程耗費的時間約5分鐘,所以必須要進行優化,所以考慮用多線程來提高效率。
優化方向:
1.多線程,使用Task并行對源文件進行分割
1 static void OcrProcess(string strFilefolder) 2 { 3 List<Task> tasks = new List<Task>(); 4 List<string> list_sourcefile = GetFileList(strFilefolder); 5 list_sourcefile.ForEach((sourcefile) => 6 { 7 Task task = Task.Factory.StartNew( () => 8 { 9 Console.WriteLine(sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 10 //這裏對文件進行分割 11 SplitProcess(sourcefile); 12 }); 13 tasks.Add(task); 14 }); 15 Task.WaitAll(tasks.ToArray()); 16 }
View Code
……
開始時間 2020-06-17 15:51:54 5458 結束時間 2020-06-17 15:52:35 3144
整個過程耗費的時間約41秒,優化效果明顯。
2.每分割出來一個文件,開啟子線程,進行識別
1 static void SplitProcess(string sourcefile) 2 { 3 List<Task> tasks = new List<Task>(); 4 Console.WriteLine("SplitFile Start:" + sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 5 for (int i = 0; i <= 5; i++) 6 { 7 //模擬分割單個文件的過程,花費500ms 8 Thread.Sleep(500); 9 string split_file = sourcefile + i; 10 Console.WriteLine("file ready:" + split_file + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 11 Task task = Task.Factory.StartNew(() => 12 { 13 RecognizeProcess(split_file); 14 }); 15 tasks.Add(task); 16 } 17 Task.WaitAll(tasks.ToArray()); 18 Console.WriteLine("SplitFile Completed:" + sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 19 }
View Code
……
開始時間 2020-06-17 15:58:59 2591 結束時間 2020-06-17 15:59:28 9051
整個過程耗費的時間約29秒,運行時間進一步縮短。
然而,最後再思考一下,如果把多線程發揮到極致,理想狀態應該是多少秒執行完畢?
以源文件sourcefile=File00為例,
第一個分割子文件split_file=File000,ReadyTime 500ms,Ocr Completed Time 應該為5500ms
第二個分割子文件split_file=File001,ReadyTime 1000ms,Ocr Completed Time 應該為6000ms
第三個分割子文件split_file=File002,ReadyTime 1500ms,Ocr Completed Time 應該為6500ms
第四個分割子文件split_file=File003,ReadyTime 2000ms,Ocr Completed Time 應該為7000ms
第五個分割子文件split_file=File004,ReadyTime 2500ms,Ocr Completed Time 應該為7500ms
第六個分割子文件split_file=File005,ReadyTime 3000ms,Ocr Completed Time 應該為8000ms
File00 Split Completed!
每一個源文件(sourcefile)被逐個分割為6個拆分子文件(split_file)並識別完成,都需要8000ms時間,如果使用線程同步的話,那麼後續源文件也同步被分割並識別完成。
所以,理想情況下,應該是8秒,而與29秒差距太大了,應該還有優化空間!
3.怎麼優化?向什麼方向優化?我們不妨不用Task,回歸到Thread本身來試試。
可是Thread運行時沒有Task.WaitAll()這樣的控制方法,因此,我們還要引入WaitHandle和ManualResetEvent來進行多線程管理。
1 class Program 2 { 3 static void Main(string[] args) 4 { 5 Console.WriteLine("Enter Main" + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 6 string strFilefolder = ""; 7 OcrProcess(strFilefolder); 8 Console.WriteLine("Main Completed" + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 9 Console.ReadKey(); 10 } 11 12 static void OcrProcess(string strFilefolder) 13 { 14 List<ManualResetEvent> split_waits = new List<ManualResetEvent>(); 15 List<string> list_sourcefile = GetFileList(strFilefolder); 16 list_sourcefile.ForEach((sourcefile) => 17 { 18 Thread m_thread = new Thread(() => 19 { 20 ManualResetEvent mre = new ManualResetEvent(false); 21 split_waits.Add(mre); 22 Console.WriteLine(sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 23 //這裏對文件進行分割 24 SplitProcess(sourcefile); 25 mre.Set(); 26 }); 27 m_thread.Start(); 28 }); 29 WaitHandle.WaitAll(split_waits.ToArray()); 30 } 31 32 static void SplitProcess(string sourcefile) 33 { 34 Console.WriteLine("SplitFile Start:" + sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 35 var ocr_waits = new List<EventWaitHandle>(); 36 for (int i = 0; i <= 5; i++) 37 { 38 //模擬分割單個文件的過程,花費500ms 39 Thread.Sleep(500); 40 string split_file = sourcefile + i; 41 Console.WriteLine("file ready:" + split_file + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 42 ManualResetEvent mre_child = new ManualResetEvent(false); 43 ocr_waits.Add(mre_child); 44 Thread m_child_thread = new Thread(() => 45 { 46 Console.WriteLine("m_child_thread enter:" + split_file + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 47 RecognizeProcess(split_file); 48 mre_child.Set(); 49 Console.WriteLine("m_child_thread after set:" + split_file + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 50 }); 51 m_child_thread.Start(); 52 } 53 WaitHandle.WaitAll(ocr_waits.ToArray()); 54 Console.WriteLine("SplitFile Completed:" + sourcefile + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 55 } 56 57 static void RecognizeProcess(string split_file) 58 { 59 //模擬識別的過程,花費5000ms 60 Thread.Sleep(5000); 61 Console.WriteLine("ocrFile Completed:" + split_file + DateTime.Now.ToString(" yyyy-MM-dd HH:mm:ss ffff")); 62 } 63 64 static List<string> GetFileList(string strFilefolder) 65 { 66 List<string> list_file = new List<string>(); 67 for (int i = 0; i <= 2; i++) 68 { 69 for (int j = 0; j <= 2; j++) 70 list_file.Add("File" + i + j); 71 } 72 return list_file; 73 } 74 }
View Code
……
開始時間 2020-06-17 15:28:17 2397 結束時間 2020-06-17 16:28:27 9151
整個過程耗費的時間約10秒,運行時間與理論的8秒已經十分接近(因為Thread創建以及運行時需要切換上下文,Console.WriteLine都有一定的耗時,PC性能好的話應該更接近8秒),可以說目標已經達成。
Tips:
ManualResetEvent初始狀態為false表示不將線程信號量初始值置為signal,線程會自動往下執行,執行Set()方法時,將線程信號量置為signal。
WaitHandle.WaitAll(split_waithandle1,split_waithandle2); //一直等待,直到split_waithandle1,split_waithandle2信號量均被置為signal才會往下執行。
不足之處:
開啟Thread要受到系統的限制,所以本例線程數必須考慮操作系統線程最大值限制。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
目錄
這是模式識別與機器學習筆記專欄的第一篇,我會持續更新。
在所有的生活場景中,我們無時無刻不在進行着模式識別。比如你看見迎面走來一個人,根據他的長相來辨認出他好像是你一年前某個活動小組的組長,然後你開始決策要不要和他打個招呼。或者你走進水果店,把西瓜拍了個遍來決定最後買哪一個。或者你突然被捂上眼睛,聽着背後人的聲音來辨別是不是你的親愛的。
模式(pattern) 可以理解成某種特徵,也就是你可以獲取到的某種原始數據,而 模式識別(pattern recognition) 就是根據輸入原始數據來判斷其類別並採取相應行為的能力。它對我們至關重要,但我們常常希望可以有機器幫我們來做這個工作,讓機器執行預定的程序來進行分類從而決策。比如一個短信攔截系統,幫我們分辨哪些是騷擾短信,哪些是有用的信息。
在這個問題上,貝恭弘=叶 恭弘斯決策理論是最最經典而基本的分類方法了。那麼,何為貝恭弘=叶 恭弘斯分類決策?
首先,我們熟悉的貝恭弘=叶 恭弘斯公式
\[P(\omega_i|x)=\frac{p(x|\omega_i)P(\omega_i)}{p(x)} \]
在模式識別問題中,用 \(d\) 維向量 \(x\) 來表示希望分類對象的特徵,它一般是從傳感器獲取,並且抽象化出來。\(\omega\) 來表示可能分類的類別。\(\omega_i\) 對應着第 \(i\) 類,如果是一個兩類問題,\(i=1,2\) ,如果是 \(c\) 類問題,則 \(i=1,2,…,c\)
\(P(\omega_i|x)\) 是由特徵 \(x\) 預測的結果,也就是后驗概率,\(p(x|\omega_i)\) 是類條件概率,或者叫似然概率,就是特徵 \(x\) 這個隨機變量分佈情況,它是取決於類別 \(\omega\) 的狀態的。\(P(\omega_i)\)是類先驗信息,是根據先前知識經驗給定的,並且因為總共就c類,所以很容易得到\(\sum^{c}_{j=1}P(\omega_j)=1\)。\(p(x)\)是歸一化因子,並不重要:
\[p(x)=\sum^{c}_{j=1}p(x|\omega_j)P(\omega_j) \]
目的就是使得所有后驗概率之和為1。
貝恭弘=叶 恭弘斯公式提供了一個后驗概率的重要計算依據:從似然概率和先驗概率得到。
首先簡化問題為二分類問題,比如短信分類問題,\(\omega=\omega_1\) 是將短信分為有用短信,\(\omega=\omega_2\) 是將短信分類為垃圾短信。假設我們現在對這兩類的先驗概率和特徵 \(x\) 的類條件概率分佈都知道了。那麼通過一個短信提取到的特徵 \(x\) ,就可以利用貝恭弘=叶 恭弘斯公式計算后驗概率,也就是對可能的兩類做出的概率判斷。
\[P(\omega_1|x)=p(x|\omega_1)P(\omega_1)\\ P(\omega_2|x)=p(x|\omega_2)P(\omega_2) \]
很自然的來比較后驗概率來進行決策,哪一類的后驗概率大,就判定為哪一類,先驗是給定的,歸一化因子不重要,實質上比的就是類條件概率分佈。
\[P(error|x)= \begin{cases} P(\omega_1|x)& \text{如果判定為}\omega_2 \\ P(\omega_2|x)& \text{如果判定為}\omega_1 \end{cases} \]
如果\(P(\omega_1|x)>P(\omega_2|x)\),判定為 \(\omega_1\);否則判定為 \(\omega_2\)
——這就是最小錯誤率貝恭弘=叶 恭弘斯決策,也就是哪一類后驗概率大,判為哪一類
如果\(p(x|\omega_1)P(\omega_1)>p(x|\omega_2)P(\omega_2)\),判定為 \(\omega_1\);否則判定為 \(\omega_2\)
下面把判決規則升級一下。
再回想一下短信分類的問題。假如預測成有用短信和騷擾短信的后驗概率接近的時候,這時候誤判的可能性還是比較高的。如果誤判,可能會把有用的分成垃圾,把垃圾短信分成有用的。可以想象這兩者的錯誤率是此消彼長的,但對哪種的錯誤率容忍度更高呢?把有用的分成垃圾的看起來更加難以接受。這時候可能就希望那種模稜兩可的情況還是判定成有用的好。那麼如何來體現這種對錯誤率容忍度的不同呢?下面就引入損失函數。
對每一種判斷以及真實情況定義一個損失函數\(\lambda(\alpha_i|\omega_j)\),以下面的兩類問題為例
| \(\lambda(\alpha_i\vert\omega_j)\) | \(\omega_1\) | \(\omega_2\) |
|---|---|---|
| \(\alpha_1\) | 0 | 1 |
| \(\alpha_2\) | 2 | 0 |
\(\omega_j\) 表示要分類對象的真實類別是 \(\omega_j\) ,\(\alpha_i\) 表示要採取的行為,即判定為 \(\omega_i\)
以短信分類為例,假如真實是\(\omega_1\) ,有用短信,採取\(\alpha_1\) ,判斷為有用,也就是判斷正確了,可以定義損失就是0。假如真實是\(\omega_2\) ,垃圾短信,採取\(\alpha_1\) ,判斷為有用,也就是判斷錯誤了,可以定義損失函數為1。假如真實是\(\omega_1\) ,有用短信,採取\(\alpha_2\) ,判斷為垃圾,同樣是判斷錯誤了,而這種錯誤我們的容忍度更低,那麼可以定義損失函數為2。
\[R(\alpha_1|x)=\lambda(\alpha_1|\omega_1)P(\omega_1|x) +\lambda(\alpha_1|\omega_2)P(\omega_2|x)\\ R(\alpha_2|x)=\lambda(\alpha_2|\omega_1)P(\omega_1|x) + \lambda(\alpha_2|\omega_2)P(\omega_2|x) \]
理解起來就是:\(\alpha_i\)行為的風險=每種 \(\omega\) 情況下採取\(\alpha_i\)行為的損失x是這種 \(\omega\) 的后驗概率
如果\(R(\alpha_1|x) < R(\omega_2|x)\),採取行為\(\alpha_1\) ,也就是判定為 \(\omega_1\);否則採取行為\(\alpha_2\) ,也就是判定為 \(\omega_2\)
因此決策的方式就是採取風險\(R(\alpha_i|x)\)最小的行為\(\alpha_i\)——這是最小風險貝恭弘=叶 恭弘斯決策
如果\((\lambda_{11}-\lambda_{21})p(x|\omega_1)P(\omega_1) < (\lambda_{22}-\lambda_{12})p(x|\omega_2)P(\omega_2)\),採取行為\(\alpha_1\) ,也就是判定為 \(\omega_1\);否則採取行為\(\alpha_2\) ,也就是判定為 \(\omega_2\)
如果\(\frac{p(x|\omega_1)}{p(x|\omega_2)}<\frac{(\lambda_{22}-\lambda_{12})}{(\lambda_{11}-\lambda_{21})}\frac{P(\omega_2)}{P(\omega_1)}\) ,採取行為\(\alpha_1\) ,也就是判定為 \(\omega_1\);否則採取行為\(\alpha_2\) ,也就是判定為 \(\omega_2\)
這樣寫的好處是,不等式右邊的損失函數和先驗概率都是給定的,是一個常數,左邊就是似然概率之比,所以只需要算出似然概率之比就可以進行分類預測
| \(\lambda(\alpha_i\vert\omega_j)\) | \(\omega_1\) | \(\omega_2\) |
|---|---|---|
| \(\alpha_1\) | 0 | 1 |
| \(\alpha_2\) | 1 | 0 |
\[R(\alpha_1|x)=\lambda(\alpha_1|\omega_1)P(\omega_1|x)+\lambda(\alpha_1|\omega_2)P(\omega_2|x)=P(\omega_2|x)\\ R(\alpha_2|x)=\lambda(\alpha_2|\omega_1)P(\omega_1|x) + \lambda(\alpha_2|\omega_2)P(\omega_2|x)=P(\omega_1|x) \]
\[R(\alpha_i|x)=\sum^c_{j=1}\lambda(\alpha_i|\omega_j)P(\omega_j|x) \]
決策行為\(\alpha^*=argminR(\alpha_i|x)\) ,也就是採取的行為\(\alpha_i\) 是使得風險\(R(\alpha_i|x)\) 最小的那個\(\alpha_i\)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
摘錄自2018年8月27日中央社報導
德國總理梅克爾今天(27日)表示,世界各地極端天候頻傳,充分證明氣候變遷已是事實。不過她反對為保護氣候拉高減少溫室氣體排放門檻,指此舉沒太大意義。
路透社報導,北半球今夏的炙熱高溫,引發外界憂心氣候變遷的現象正加速發生,歐洲數十個國家都呼籲,減少溫室氣體排放量的速度,應要比原訂目標更快。
歐洲聯盟(EU)執委會主管氣候行動與能源事務執委卡尼特(Miguel Arias Canete)呼籲將2030年之前溫室氣體減量目標,從40%提高至45%。
但梅克爾(Angela Merkel)表示,加速減少有害的二氧化碳排放量恐適得其反,況且歐洲各國此際對達成原訂目標都很吃力,再要拉高門檻沒有道理。
她說:「我對這些新提議尤其不怎麼高興。我認為應先堅守既定目標。我不認為一直設定新目標有任何意義。」
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
摘錄自2018年8月30日世界日報報導
加州州議會29日準備將一項畫時代的法案送交州長簽署,這項法案規定,加州在2045年前將電力供應全面變為清潔能源,不再使用煤和石油發電,100%改用太陽能、風力和其他再生能源。
由州參議會議長德利昂提出的SB100號法案,先獲州參議會通過,29日再獲州眾議會以43票對32票通過;州眾議會進行了修改,所以須再送回州參議會通過,就可以送交州長簽署。州議會今年的會期,將於本周結束,所以SB100估計可於周末前送交州長。
加州的公用事業公司包括太平洋瓦電和聖地牙哥瓦電,都反對SB100。美西各州石油協會和其他組織也反對。
布朗州長對SB100保持沉默,沒有說是否簽署,雖然他是加州反暖運動的先鋒。明年可能接替布朗做州長的紐森,曾說要以100%清潔能源作為加州的目標,但是他也沒有對SB100表態。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
ZooKeeper是一個分佈式的,開源的分佈式應用程序協調服務,是Hadoop的子項目之一。它是一個為分佈式應用提供一致性服務的軟件,提供的功能包括:配置維護、域名服務、分佈式同步、組服務等。
| 操作系統 | 客戶端 | 服務端 | 原生客戶端 | 附加組件 |
|---|---|---|---|---|
| GNU/Linux | 開發/生產 | 開發/生產 | 開發/生產 | 開發/生產 |
| Solaris | 開發/生產 | 開發/生產 | 不支持 | 不支持 |
| FreeBSD | 開發/生產 | 開發/生產 | 不支持 | 不支持 |
| Windows | 開發/生產 | 開發/生產 | 不支持 | 不支持 |
| Mac OS X | 開發 | 開發 | 不支持 | 不支持 |
Java 8及Java 11以上版本(Java 9和10不支持)
此硬件資源為官網推薦的配置,實際開發過程中不需要這麼大,筆者測試1核1G內存20G硬盤的虛擬機即可運行。
apache-zookeeper-3.6.1/conf/zoo_sample.cfg複製一份並重命名為zoo.cfg,沒什麼特殊需要裡邊的配置項默認即可,筆者因為是在windows下使用,所以將datadir修改了。配置文件項說明如下:| 配置項 | 說明 |
|---|---|
tickTime |
ZooKeeper使用的時間,單位毫秒,一般用於心跳檢測,而ZooKeeper中的最小session超時時間是此項的兩倍 |
dataDir |
保留內存數據庫快照的地址,如果不單獨指定,事務日誌也會記錄在此 |
clientPort |
服務端監聽的端口號 |
initLimit |
集群中的follower服務器與leader服務器之間初始連接時的最大心跳數 |
syncLimit |
集群中follower服務器與leader服務器之間通訊時的最大心跳數 |
zkServer.bat,Linux下為zkServer.sh。bin目錄下自帶的客戶端進行訪問,Windows下為zkCli.bat,Linux下為zkCli.sh。localhost:2181,如果有需要連接遠程或其他端口的情況,可以如下添加參數:zkCli.sh -server IP:Port
進入客戶端后執行help(此處是一個隨意的指令,只要不是zkCli支持的操作都可以)可查看其支持的操作,關於所有操作的介紹請參考官方頁面:https://zookeeper.apache.org/doc/current/zookeeperCLI.html
常用操作介紹:
ls /
ls /zookeeper
create /test
create /test/testa
stat /test
stat /test/testa
# 刪除單個空節點
delete /test/testa
delete /test
# 級聯刪除
deleteall /test
*退出客戶端
quit
因為筆者的第一開發語言是Java,這裏以Java為例。常用的ZooKeeper Java客戶端用zkclient和Apache Curator兩種。zkclient是github上的一個開源項目,該項目在2018年10月2日後停止更新;Apache Curator是Apache基金會的開源項目,目前持續更新,推薦使用。常用的分佈式RPC框架DUBBO也在2019年1月份推出的2.7.0版本中將默認的ZooKeeper客戶端由zkclient切換為Apache Curator,此文中的示例也使用Apache Curator。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>apache-curator</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.curator/curator-recipes -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.6.2</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
src\test\java\目錄創建com\aotian\curator\test\Tester.java,文件基本框架如下,主要是創建一個空的測試類public class Tester {
@Test
public void testCurator() {
}
}
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient("localhost:2181", retryPolicy);
curatorFramework.start();
Stat對象,不存在則返回nullcuratorFramework.checkExists().forPath("/localhost/aotian");
forPath第二個參數可以指定節點內容,不設置時創建空節點curatorFramework.create().creatingParentContainersIfNeeded().forPath("/localhost/aotian", message.getBytes());
curatorFramework.setData().forPath("/localhost/aotian", message.getBytes());
result對象。Stat result = new Stat();
curatorFramework.getData().storingStatIn(result).forPath("/localhost/aotian");
byte[] results = curatorFramework.getData().forPath("/localhost/aotian");
zkCli查看服務端中的內容。 @Test
public void testCurator() {
// 創建客戶端
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient("localhost:2181", retryPolicy);
curatorFramework.start();
// 定義節點內容
String message = "testCurator";
try {
// 判斷節點是否存在不存在則創建,存在則設置指定值
Stat a = curatorFramework.checkExists().forPath("/localhost/aotian");
if (a == null){
curatorFramework.create()
.creatingParentContainersIfNeeded()
.forPath("/localhost/aotian", message.getBytes());
}else{
curatorFramework.setData().forPath("/localhost/aotian", message.getBytes());
}
// 獲取節點信息
Stat result = new Stat();
curatorFramework.getData().storingStatIn(result).forPath("/localhost/aotian");
System.out.println(result.getCtime());
// 獲取節點內容
byte[] results = curatorFramework.getData().forPath("/localhost/aoitan");
System.out.println(new String(results));
// 線程睡10S,這段時間內可以通過客戶端查看節點內的信息,結束后只能查看到空節點
Thread.sleep(100000);
} catch (Exception e) {
e.printStackTrace();
}finally {
curatorFramework.close();
}
}
ZooKeeper集群中包含兩種角色:Leader和Follower,因為ZooKeeper集群是半數節以上節點正常時才會正常提供服務,所以一般ZooKeeper集群中節點數量均為奇數。我們按照最小數量算,準備三台zookeeper服務器。
datadir屬性對應的目錄下創建一個myid文件。然後在文件內寫上當前服務對應的ID,筆者規劃的是0、1、2,所以我需要添加的配置文件如下:| IP地址 | 文件路徑 | 文件內容 |
|---|---|---|
| 192.168.142.7 | /tmp/zookeeper/myid | 0 |
| 192.168.142.8 | /tmp/zookeeper/myid | 1 |
| 192.168.142.9 | /tmp/zookeeper/myid | 2 |
datadir屬性默認在/tmp目錄下,此目錄會被定期清理掉,生產環境不要使用。
3、配置完以上文件后,需要配置之前的zoo.cfg,在最後添加以下內容,其中server.*對應myid文件中的ID號,192.168.142.7是IP地址,2888是ZooKeeper集群的通訊端口,3888是集群選取Leader使用的端口。
server.0=192.168.142.7:2888:3888
server.1=192.168.142.8:2888:3888
server.2=192.168.142.9:2888:3888
4、最後檢查防火牆是否開放了2181、2888、3888端口,確認開放后啟動ZooKeeper即可。通過執行zkServer.sh status命令可以查看當前機器的狀態。
[root@centos-server-01 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/apache-zookeeper-3.6.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@centos-server-02 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/apache-zookeeper-3.6.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新