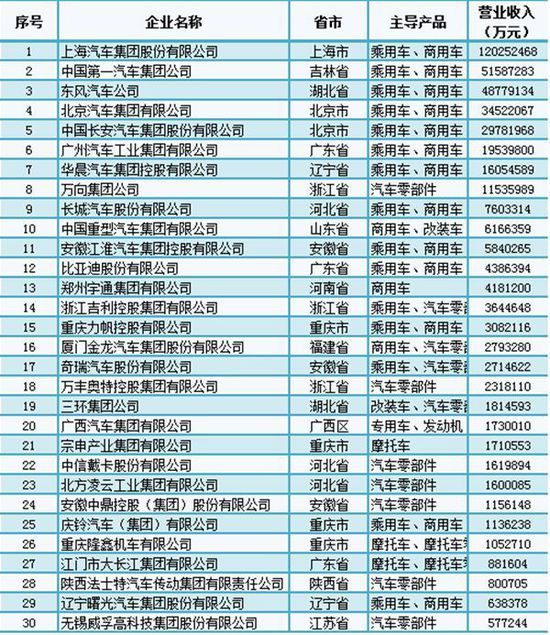
自適應濾波是数字信號處理的核心技術之一,在科學和工業上有着廣泛的應用領域。自適應濾波技術應用廣泛,包括回波抵消、自適應均衡、自適應噪聲抵消和自適應波束形成。回聲對消是當今通信系統中普遍存在的現象。聲回波引起的信號干擾會分散用戶的注意力,降低通信質量。本文重點介紹了LMS和NLMS算法的使用,以減少這種不必要的回聲,從而提高通信質量
關鍵詞:自適應濾波器,自適應算法,回聲消除
1 引言
當音頻信號在真實環境中產生混響時,就會產生聲學回聲,從而導致原始信號加上信號[1]的衰減、延時圖像。本文將重點研究通信系統中聲學回波的產生。
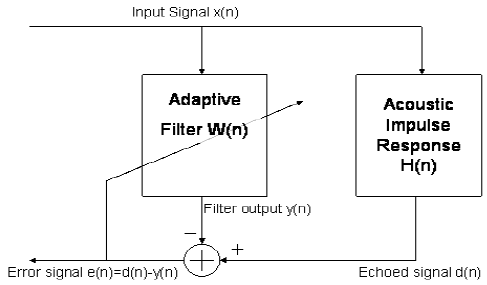
自適應濾波器是一種動態濾波器,它不斷地改變其特性以獲得最優的輸出。自適應濾波算法通過改變參數使期望輸出d (n)與實際輸出y (n)之間的差值最小化。該函數稱為自適應算法的代價函數(loss)。圖1显示了自適應回聲抵消系統的框圖。其中,濾波器H(n)表示聲環境的脈衝響應,W(n)表示用來抵消回波信號的自適應濾波器。自適應濾波器的目標是使輸出的y(n)與期望的d(n)(在回聲環境中混響的信號)相等。在每次迭代中,誤差信號e(n)=d (n)-y (n)被反饋回濾波器,濾波器的特性也隨之改變。
自適應回聲消除系統
自適應濾波器的目標是計算期望信號與自適應濾波器輸出之間的差值e(n)。該誤差信號反饋到自適應濾波器,並通過算法改變其係數,以最小化該差值的函數,即代價函數。在聲回波消除的情況下,自適應濾波器的最優輸出與不需要的回波信號等值。當自適應濾波器輸出等於期望信號時,誤差信號為零。在這種情況下,回顯信號將被完全取消,遠用戶將不會聽到他們的任何原始語音返回給他們。
2. 最小均方(LMS)算法
最小均方(LMS)算法是由Widrow和Hoff在1959年通過對模式識別的研究首次提出的。由此成為自適應濾波中應用最廣泛的算法之一。LMS算法是一種基於隨機梯度的自適應濾波算法,它利用濾波器權重的梯度來收斂到最優的維納解[2-4]。由於其計算簡單而廣為人知並被廣泛使用。正是這種簡單性使它成為判斷所有其他自適應濾波算法的基準。
隨着LMS算法的每次迭代,自適應濾波器的濾波抽頭(tap)權值按照如下公式進行更新。
$$公式1:w(n+1)=w(n)2\mu e(n)x(n)$$
這裏x(n)是延時輸入值的輸入向量,$x(n)=[x_1(n)x_2(n)…x_N(n)]^T=[x(n)x(n-1)…x(n-N+1)]^T$。向量$w(n)=[w_0(n)w_1(n)w_2(n)…w_{N-1}(n)]^T$代表自適應FIR濾波器抽頭(tap)權向量在時刻n的係數。參數μ被稱為步長參數和小正的常數。此步長參數控制更新因子的影響。μ必須選擇一個合適的值LMS算法的性能,如果該值太小自適應濾波器的收斂時間會太長;如果μ太大自適應濾波器變得不穩定,導致其輸出發散[5 – 8]。
2.1 LMS算法的實現
LMS算法的每次迭代都需要三個不同的步驟,順序如下:
1. FIR濾波器的輸出y(n)用公式2計算。
$$公式2:y(n)=\sum_{i=0}^{N-1}w(n)x(n-1)=w^T(n)x(n)$$
2. 誤差估計的值按公式3計算。
$$公式3:e(n)=d(n)-y(n)$$
3.更新FIR向量的抽頭tap權值,為下一次迭代做準備,如公式4所示。
$$公式4:w(n+1)=w(n)+2\mu e(n)x(n)$$
LMS算法在自適應濾波中得到廣泛應用的主要原因是其計算簡單,比其他常用的自適應算法更易於實現。LMS算法每次迭代需要2N加法和2N + 1次乘法(N用於計算輸出y(N)),另一個用於通過向量乘法計算標量[9]。
clear; clc; snr=20; % 信噪比 order=8; % 自適應濾波器的階數為8 Hn =[0.8783 -0.5806 0.6537 -0.3223 0.6577 -0.0582 0.2895 -0.2710 0.1278 ... % ...表示換行的意思 -0.1508 0.0238 -0.1814 0.2519 -0.0396 0.0423 -0.0152 0.1664 -0.0245 ... 0.1463 -0.0770 0.1304 -0.0148 0.0054 -0.0381 0.0374 -0.0329 0.0313 ... -0.0253 0.0552 -0.0369 0.0479 -0.0073 0.0305 -0.0138 0.0152 -0.0012 ... 0.0154 -0.0092 0.0177 -0.0161 0.0070 -0.0042 0.0051 -0.0131 0.0059 ... -0.0041 0.0077 -0.0034 0.0074 -0.0014 0.0025 -0.0056 0.0028 -0.0005 ... 0.0033 -0.0000 0.0022 -0.0032 0.0012 -0.0020 0.0017 -0.0022 0.0004 -0.0011 0 0]; Hn=Hn(1:order); mu=0.5; % mu表示步長 N=1000; % 橫坐標1000個採樣點 Loop=150; % 150次循環 EE_NLMS=zeros(N,1); % 不同步長的初始化誤差 for nn=1:Loop % epoch=150 % 權重初始化w win_NLMS=zeros(1,order); % NLMS四種步長測試,四個權重——1 error_NLMS=zeros(1,N)'; % 初始化誤差 % 均勻分佈的輸入值 r=sign(rand(N,1)-0.5); % shape=(1000,1)的(0,1)均勻分佈-0.5,sign(n)>0=1;<0=-1 % 輸出:輸入卷積Hn得到 輸出 output=conv(r,Hn); % r卷積Hn,output長度=length(u)+length(v)-1 output=awgn(output,snr,'measured'); % 將白高斯噪聲添加到信號中 % N=1000,每個採樣點 for i=order:N % i=8:1000 input=r(i:-1:i-order+1); % 每次迭代取8個數據進行處理 e_NLMS = output(i)-win_NLMS*input; win_NLMS=win_NLMS+e_NLMS*input'/(input'*input); % NLMS更新權重 error_NLMS(i)=error_NLMS(i)+e_NLMS^2; end EE_NLMS=EE_NLMS+error_NLMS; % 把總誤差相加 end % 對總誤差求平均值 error_NLMS=EE_NLMS/Loop; figure; error_NLMS=10*log10(error_NLMS(order:N)); plot(error_NLMS,'r'); % 紅色 axis tight; % 使用緊湊的坐標軸 legend('NLMS算法'); % 圖例 title('NLMS算法誤差曲線'); % 圖標題 xlabel('樣本'); % x軸標籤 ylabel('誤差/dB'); % y軸標籤 grid on; % 網格線
3 歸一化最小均方(NLMS)算法
LMS算法的主要缺點之一是每次迭代都有一個固定的步長參數。這需要在開始自適應濾波操作之前了解輸入信號的統計信息。實際上,這是很難實現的。即使我們假設自適應回聲抵消系統的唯一輸入信號是語音,但仍有許多因素如信號輸入功率和振幅會影響其性能[10-12]。
歸一化最小均方算法(NLMS)是LMS算法的擴展,LMS算法通過計算最大步長值來繞過這個問題。步長值的計算公式如下
$$Step\ size = \frac{1}{dot\ product(input\ vector,\ input\ vector)}$$
這個步長與輸入向量x(n)的係數的瞬時值的總期望能量的倒數成正比。輸入樣本的期望能量之和也等於輸入向量與自身的點積,以及輸入向量自相關矩陣的跡R[13-15]。
$$公式5:tr[R]=\sum_{i=0}^{N-1}E[x^2(n-i)]\\ \quad\quad =E[\sum_{i=0}^{N-1}x^2(n-i)]$$
NLMS算法的遞歸公式如式6所示
$$公式6:w(n+1)=w(n)+\frac{1}{x^T(n)x(n)}e(n)x(n)$$
3.1 NLMS算法的實現
NLMS算法已在Matlab中實現。由於步長參數是根據當前的輸入值來選擇的,因此NLMS算法在未知信號下具有更大的穩定性。該算法具有良好的收斂速度和相對簡單的計算能力,是實時自適應回波抵消系統[16]的理想算法。
由於NLMS是標準LMS算法的擴展,因此NLMS算法的實際實現與LMS算法非常相似。NLMS算法的每次迭代都需要按照以下順序執行這些步驟。
1. 計算了自適應濾波器的輸出
$$公式7:y(n)=\sum_{i=0}^{N-1}w(n)x(n-i)=w^T(n)x(n)$$
2. 誤差信號等於期望信號和濾波器輸出之間的差值。
$$公式8:e(n)=d(n)-y(n)$$
3.計算了輸入向量的步長值。
$$公式9:\mu(n)=\frac{1}{x^T(n)x(n)}$$
4. 濾波器抽頭權重更新,為下一次迭代做準備。
$$公式10:w(n+1)=w(n)+\mu(n)e(n)x(n)$$
NLMS算法的每次迭代都需要3N+1次乘法,僅比標準LMS算法多N次。考慮到所獲得的穩定性和回波衰減增益,這是一個可接受的增加。
clear; clc; snr=20; % 信噪比 order=8; % 自適應濾波器的階數為8 % Hn是濾波器權重 Hn =[0.8783 -0.5806 0.6537 -0.3223 0.6577 -0.0582 0.2895 -0.2710 0.1278 ... % ...表示換行的意思 -0.1508 0.0238 -0.1814 0.2519 -0.0396 0.0423 -0.0152 0.1664 -0.0245 ... 0.1463 -0.0770 0.1304 -0.0148 0.0054 -0.0381 0.0374 -0.0329 0.0313 ... -0.0253 0.0552 -0.0369 0.0479 -0.0073 0.0305 -0.0138 0.0152 -0.0012 ... 0.0154 -0.0092 0.0177 -0.0161 0.0070 -0.0042 0.0051 -0.0131 0.0059 ... -0.0041 0.0077 -0.0034 0.0074 -0.0014 0.0025 -0.0056 0.0028 -0.0005 ... 0.0033 -0.0000 0.0022 -0.0032 0.0012 -0.0020 0.0017 -0.0022 0.0004 -0.0011 0 0]; Hn=Hn(1:order); mu=0.5; % mu表示步長 N=1000; % 橫坐標1000個採樣點 Loop=150; % 150次循環 % 不同步長的初始化誤差 EE_LMS = zeros(N,1); EE_NLMS=zeros(N,1); for nn=1:Loop % epoch=150 win_LMS = zeros(1,order); % 權重初始化w error_LMS=zeros(1,N)'; % 初始化誤差 % 均勻分佈的語音數據輸入 r=sign(rand(N,1)-0.5); % shape=(1000,1)的(0,1)均勻分佈-0.5,sign(n)>0=1;<0=-1 % 輸出:輸入卷積Hn得到 輸出 output=conv(r,Hn); % r卷積Hn,output長度=length(u)+length(v)-1 output=awgn(output,snr,'measured'); % 真實輸出=將白高斯噪聲添加到信號中 % N=1000,每個採樣點 for i=order:N % i=8:1000 input=r(i:-1:i-order+1); % 每次迭代取8個數據進行處理 e_LMS = output(i)-win_LMS*input; mu=0.02; % 步長 win_LMS = win_LMS+2*mu*e_LMS*input'; error_LMS(i)=error_LMS(i)+e_LMS^2; end % 把總誤差相加 EE_LMS = EE_LMS+error_LMS; end % 對總誤差求平均值 error_LMS = EE_LMS/Loop; figure; error1_LMS=10*log10(error_LMS(order:N)); plot(error1_LMS,'b.'); % 藍色 axis tight; % 使用緊湊的坐標軸 legend('LMS算法'); % 圖例 title('LMS算法誤差曲線'); % 圖標題 xlabel('樣本'); % x軸標籤 ylabel('誤差/dB'); % y軸標籤 grid on; % 網格線
4 LMS算法的結果
利用Matlab對LMS算法進行了仿真。圖2显示的是通過麥克風從計算機系統收集到的輸入語音信號。圖3显示了從輸入信號派生出的所需回波信號。圖4显示了自適應濾波器的輸出,它將減少輸入信號的回波信號。圖5显示了由濾波器輸出信號計算出的均方誤差信號。圖6是由回波信號對誤差信號的分割得到的衰減。
自適應濾波器為1025階FIR濾波器。步長設置為0.02。MSE表明,隨着算法的發展,代價函數的平均值逐漸減小。
5 NLMS算法的結果
用Matlab對NLMS算法進行了仿真。圖7显示了輸入信號。圖8显示了所需的信號。圖9显示了自適應濾波器輸出。圖10显示了均方誤差。圖11显示了衰減。
自適應濾波器為1025階FIR濾波器。步長設置為0.1。
NLMS算法在均方誤差和平均衰減方面優於LMS算法,其性能總結如表1所示。
6 結論
由於其簡單性,LMS算法是最流行的自適應算法。然而,LMS算法存在收斂速度慢和數據依賴的問題。
NLMS算法是LMS算法的一個同樣簡單但更健壯的變體,它在簡單性和性能之間表現出比LMS算法更好的平衡。由於其良好的性能,NLMS在實時應用中得到了廣泛的應用。
7. 參考
文章翻譯自論文《2011_adaptive algorithms for acoustic echo cancellation in speech processing》
[1]. Homana, I.; Topa, M.D.; Kirei, B.S.; “Echo cancelling using adaptive algorithms”, Design and Technology of Electronics Packages, (SIITME) 15th International Symposium., pp. 317-321, Sept.2009.
[2]. Paleologu, C.; Benesty, J.; Grant, S.L.; Osterwise, C.; “Variable step-size NLMS algorithms for echo cancellation” 2009 Conference Record of the forty-third Asilomar Conference on Signals, Systems and Computers., pp. 633-637, Nov 2009.
[3]. Soria, E.; Calpe, J.; Chambers, J.; Martinez, M.; Camps, G.; Guerrero, J.D.M.; “A novel approach to introducing adaptive filters based on the LMS algorithm and its variants”, IEEE Transactions, vol. 47, pp. 127-133, Feb 2008.
[4]. Tandon, A.; Ahmad, M.O.; Swamy, M.N.S.; “An efficient, low-complexity, normalized LMS algorithm for echo cancellation”, IEEE workshop on Circuits and Systems, 2004. NEWCAS 2004, pp. 161-164, June 2004.
[5]. Eneman, K.; Moonen, M.; “Iterated partitioned block frequency-domain adaptive filtering for acoustic echo cancellation,” IEEE Transactions on Speech and Audio Processing, vol. 11, pp. 143-158, March 2003.
[6]. Krishna, E.H.; Raghuram, M.; Madhav, K.V; Reddy, K.A; “Acoustic echo cancellation using a computationally efficient transform domain LMS adaptive filter,” 2010 10th International Conference on Information sciences signal processing and their applications (ISSPA), pp. 409-412, May 2010.
[7]. Lee, K.A.; Gan,W.S; “Improving convergence of the NLMS algorithm using constrained subband updates,” Signal Processing Letters IEEE, vol. 11, pp. 736-739, Sept. 2004.
[8]. S.C. Douglas, “Adaptive Filters Employing Partial Updates,” IEEE Trans.Circuits SYS.II, vol. 44, pp. 209-216, Mar 1997.
[9]. D.L. Duttweiler, “Proportionate Normalized Least Mean Square Adaptation in Echo Cancellers,” IEEE Trans. Speech Audio Processing, vol. 8, pp. 508-518, Sept. 2000.
[10]. E. Soria, J. Calpe, J. Guerrero, M. Martínez, and J. Espí, “An easy demonstration of the optimum value of the adaptation constant in the LMS algorithm,” IEEE Trans. Educ., vol. 41, pp. 83, Feb. 1998.
[11]. D. Morgan and S. Kratzer, “On a class of computationally efficient rapidly converging, generalized NLMS algorithms,” IEEE Signal Processing Lett., vol. 3, pp. 245–247, Aug. 1996.
[12]. G. Egelmeers, P. Sommen, and J. de Boer, “Realization of an acoustic echo canceller on a single DSP,” in Proc. Eur. Signal Processing Conf. (EUSIPCO96), Trieste, Italy, pp. 33–36, Sept. 1996.
[13]. J. Shynk, “Frequency-domain and multirate adaptive filtering,” IEEE Signal Processing Mag., vol. 9, pp. 15– 37, Jan. 1992.
[14]. Ahmed I. Sulyman and Azzedine Zerguine, “Echo Cancellation Using a Variable Step-Size NLMS Algorithm”, Electrical and Computer Engineering Department Queen’s University.
[15]. D. L. Duttweiler, “A twelve-channel digital echo canceller,” IEEE Trans. Commun., vol. 26, no. 5, pp. 647–653, May 1978.
[16]. J. Benesty, H. Rey, L. Rey Vega, and S. Tressens, “A nonparametric VSS NLMS algorithm,” IEEE Signal Process. Lett., vol. 13, pp. 581–584, Oct. 2006.
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※大陸寄台灣空運注意事項
※大陸海運台灣交貨時間多久?
※避免吃悶虧無故遭抬價!台中搬家公司免費估價,有契約讓您安心有保障!