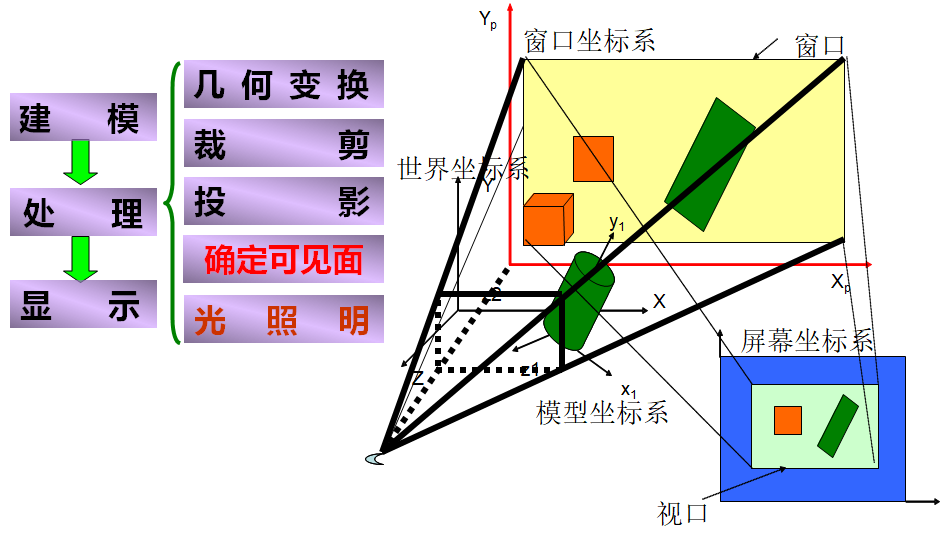
一、概述
由於投影變換失去了深度信息,往往導致圖形的二義性。要消除二義性,就必須在繪製時消除被遮擋的不可見的線或面,習慣上稱作消除隱藏線和隱藏面(或可見線判定、可見面判定),或簡稱為消隱。經過消隱得到的投影圖稱為物體的真實感圖形。
下面這個圖就很好體現了這種二義性。
消隱后的效果圖:
消隱算法的分類
所有隱藏面消隱算法必須確定:
在沿透視投影的投影中心或沿平行投影的投影方向看過去哪些邊或面是可見的
兩種基本算法
1、以構成圖像的每一個像素為處理單元,對場景中的所有表面,確定相對於觀察點是可見的表面,用該表面的顏色填充該像素.
適於面消隱。
算法步驟:
a.在和投影點到像素連線相交的表面中,找到離觀察點最近的表面;
b.用該表面上交點處的顏色填充該像素;
2、以三維場景中的物體對象為處理單元,在所有對象之間進行比較,除去完全不可見的物體和物體上不可見的部分.適於面消隱也適於線消隱。
算法步驟:
a.判定場景中的所有可見表面;
b.用可見表面的顏色填充相應的像素以構成圖形;
提醒注意
1.假定構成物體的面不能相互貫穿,也不能有循環遮擋的情況。
2.假定投影平面是oxy平面,投影方向為z軸的負方向。
如果構成物體的面不滿足該假定,可以把它們剖分成互不貫穿和不循環遮擋的情況。
例如,用圖b中的虛線便可把原來循環遮擋的三個平面,分割成不存在循環遮擋的四個面。
二、可見面判斷的有效技術
1、邊界盒
指能夠包含該物體的一個幾何形狀(如矩形/圓/長方體等),該形狀有較簡單的邊界。
邊界盒技術用於判斷兩條直線是否相交。
進一步簡化判斷
2、後向面消除(Back-face Removal)
思路:把顯然不可見的面去掉,減少消隱過程中的直線求交數目
如何判斷:根據定義尋找外(或內)法向,若外法向背離觀察者,或內法向指向觀察者,則該面為後向面。
注意:如果多邊形是凸的,則可只取一個三角形計算有向面積sp。如果多邊形不是凸的,只取一個三角形計算有向面積sp可能會出現錯誤,即F所在的面為前向面也可能出現sp≥0的情況,因此,需按上式計算多邊形F的有向面積。如果sp ≥0,則F所在的面為後向面。
3、非垂直投影轉化成垂直投影
物體之間的遮擋關係與投影中心和投影方向有着密切的關係,因此,對物體的可見性判定也和投影方式有密切的關係。
垂直投影的優點:進行投影時可以忽略z值,即:實物的(x,y)可直接做為投影后的二維平面上的坐標(x,y)
上述討論說明,垂直投影比非垂直投影容易實現,並且計算量小。因此在進行消隱工作之前,首先應將非垂直投影轉換成垂直投影,從而降低算法的複雜性,提高運算速度。
如何把透視投影變為垂直投影,其本質是把稜台變成長方體。
三、基於窗口的子分算法(Warnack算法)
是一種分而治之(Divide-Conquer)的算法。
1、關係判斷
2、可見性判斷
3、分隔結束條件
4、提高效率的有效的處理技術
5、算法描述
用多邊形的邊界對區域作劃分,其目的是盡量減少對區域劃分的次數--利用裁剪算法
四、八叉樹算法
為了生成真實感圖形,關鍵問題之一就是對圖像空間的每一個像素進行處理。從場景中所有的在該像素上有投影的表面中確定相對於觀察點是可見表面。為了提高算法效率,自然是希望從可能在像素上有投影的面片中尋找可見表面。八叉樹算法是快速尋找可見面的一種有效方法,是一種搜索算法。
基本思想:將能夠包含整個場景的立方體,即八叉樹的根結點,按照x,y,z三個方向中的剖面分割成八個子立方體,稱為根結點的八個子結點。對每一個子立方體,如果它包含的表面片少於一個給定的值,則該子立方體為八叉樹的終端結點,否則為非終端結點並將其進一步分割成八個子立方體;重複上述過程,直到每個小立方體所包含的表面片少於一個給定的值,分割即告終止。
那麼對於上述圖所示,視圖平面法向量(1,1,1)那麼此時它的一個排列是0,1,2,4,3,5,6,7,即最遠的八分體是0,與八分體0共享一個面的三個相鄰八分體是1,2和4,與最近八分體7的3個相鄰八分體是3,5和6。
五、Z緩衝器算法
1、算法描述
z緩衝器算法是最簡單的隱藏面消除算法之一。
基本思想:對屏幕上每一個像素點,過像素中心做一條投影線,找到此投影線與所有多邊形交點中離觀察者最近的點,此點的屬性(顏色或灰度)值即為這一屏幕像素點的屬性值。
需要兩個緩衝器數組,即:z緩衝器數組和幀緩衝器數組,分別設為 Zdepth[ ][ ] 與 Frame[ ][ ]
z緩衝器是一組存貯單元,其單元個數和屏幕上像素的個數相同,也和幀緩衝器的單元個數相同,它們之間一一對應。
幀緩衝器每個單元存放對應像素的顏色值;z緩衝器每個單元存放對應像素的深度值;
2、算法實現
算法的複雜性正比於m*n*N,在屏幕大小即m*n一定的情況下,算法的計算量只和多邊形個數N成正比
3、優缺點
z-Buffer算法沒有利用圖形的相關性和連續性,這是z-Buffer算法的嚴重缺陷,更為嚴重的是,該算法是像素級上的消隱算法。
六、掃描線z緩衝器算法
1、算法描述
將z緩衝器的單元數置為和一條掃描線上的像素數目相同。
從最上面的一條掃描線開始工作,向下對每一條掃描線作如下處理:
掃描線算法也屬於圖像空間消隱算法。該算法可以看作是多邊形區域填充里介紹過的邊相關掃描線填充算法的延伸。不同的是在消隱算法中處理的是多個面片,而多邊形填充中是對單個多邊形面進行填充。
2、數據結構
對每個多邊形,檢查它在oxy平面上的投影和當前掃描線是否相交?
若不相交,則不考慮該多邊形。
如果相交,則掃描線和多邊形邊界的交點是成對地出現
對每對交點中間的像素計算多邊形所在平面對應點的深度(即z值),並和z緩衝器中相應單元存放的深度值作比較。
若前者大於後者,則z緩衝器的相應單元內容要被求得的平面深度代替,幀緩衝器相應單元的內容也要換成該平面的屬性。
對所有的多邊形都作上述處理后,幀緩衝器中這一行的值便反應了消隱后的圖形。
對幀緩衝器每一行的單元都填上相應內容后就得到了整個消隱后的圖。
每處理一條掃描線,都要檢查各多邊形是否和該線相交,還要計算多邊形所在平面上很多點的z值,需要花費很大的計算
為了提高算法效率,採用跟多邊形掃描轉換中的掃描線算法類似的數據結構和算法.
多邊形Y表
實際上是一個指針數組 ,每個表的深度和显示屏幕行數相同.將所有多邊形存在多邊形Y表中,根據多邊形頂點中Y坐標最大值,插入多邊形Y表中的相應位置,多邊形Y表中保存多邊形的序號和其頂點的最大y坐標.
邊Y表
要注意:Δx是下一條掃描線與邊交點的x減去當前的掃描線與邊交點的x。
多邊形活化表
邊對活化表
其實這裏最難理解的就是Δyl和Δxr了,這裏的意思就是當前掃描線所處的y值和與該掃描線相交邊的最小y值的差值。
就比如說掃描線y=6,與第一個三角形有兩個交點,左交點(4,6),右交點(7,6)那麼Δyl=6-3 Δyr=6-3
3、重溫算法目標
對每一條掃描線,檢查對每個多邊形的投影是否相交,如相交則交點成對出現,對每對交點中間的每個像素計算多邊形所在平面對應點的深度(即z值),並和z緩衝器中相應單元存放的深度值作比較,若前者大於後者,則z緩衝器的相應單元內容要被求得的平面深度代替,幀緩衝器相應單元的內容也要換成該平面的屬性。
對所有的多邊形都作上述處理后,幀緩衝器中這一行的值便反應了消隱后的圖形,對幀緩衝器每一行的單元都填上相應內容后也就得到了整個消隱后的圖。
4、算法步驟
算法描述如下
七、優先級排序表算法
1、算法思想
優先級排序表算法按多邊形離觀察者的遠近來建立一個多邊形排序表,距觀察者遠的優先級低,放在表頭;近的優先級高,放在表尾
從優先級低的多邊形開始,依次把多邊形的顏色填入幀緩衝存儲器中
表中距觀察者近的元素覆蓋幀緩衝存儲器中原有的內容
當優先級最高的多邊形的圖形送入幀緩衝器后,整幅圖形就形成了
類似於油畫家繪畫過程,因此又稱為油畫家算法。
2、算法的優缺點
算法的優點:
簡單,容易實現,並且可以作為實現更複雜算法的基礎;
缺點:
只能處理不相交的面,而且深度優先級表中面的順序可能出錯.
該算法不能處理某些特殊情況。
解決辦法:把P沿Q平面一分為二,從多邊形序列中把原多邊形P去掉,把分割P生成的兩個多邊形加入鏈表中。具體實現時,當離視點最遠的多邊形P和其他多邊形交換時,要對P做一標誌,當有標誌的多邊形再換成離視點最遠的多邊形時,則說明出現了上述的現象,可用分割方法進行處理 。
用來解決動態显示問題時,可大大提高效率
八、光線投射算法
1、算法原理
要處理的場景中有無限多條光線,從採樣的角度講我們僅對穿過像素的光線感興趣,因此,可考慮從像素出發,逆向追蹤射入場景的光線路徑
2、算法實現
由視點出發穿過觀察平面上一像素向場景發射一條射線
求出射線與場景中各物體表面的交點
離視點最近的交點的顏色即為像素要填的顏色。
光線投射算法對於包含曲面,特別是包含球面的場景有很高的效率。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益

 業界認為,這家韓國公司並不是唯一一家負責蘋果電池開發的公司。不過,有消息稱,儘管蘋果從一開始就從完全不同的設計、功能以及性能角度來開發電池,但是他們仍舊一直在挖掘創新技術。業界相信,蘋果專注于開發出只能存在於蘋果自動駕駛汽車的創新電池技術。 這家韓國電池開發商由大約20名電池專家組成,持有空芯電池的國際專利技術。這些電池是圓柱形鋰離子二次電池,有兩根手指那麼厚,不同於其它空芯電池。蘋果並未選擇當前電動汽車普遍使用的標準圓形或矩形電池,但計畫根據韓國公司的空芯電池技術為其電動汽車開發自主電池。 文章來源:鳳凰科技
業界認為,這家韓國公司並不是唯一一家負責蘋果電池開發的公司。不過,有消息稱,儘管蘋果從一開始就從完全不同的設計、功能以及性能角度來開發電池,但是他們仍舊一直在挖掘創新技術。業界相信,蘋果專注于開發出只能存在於蘋果自動駕駛汽車的創新電池技術。 這家韓國電池開發商由大約20名電池專家組成,持有空芯電池的國際專利技術。這些電池是圓柱形鋰離子二次電池,有兩根手指那麼厚,不同於其它空芯電池。蘋果並未選擇當前電動汽車普遍使用的標準圓形或矩形電池,但計畫根據韓國公司的空芯電池技術為其電動汽車開發自主電池。 文章來源:鳳凰科技