npm install 命令
首先總結下npm 安裝一個模塊包的常用命令。
/* 模塊依賴會寫入 dependencies 節點 */ npm install moduleName npm install -save moduleName npm install -S moduleName /* 模塊依賴會寫入 devDependencies 節點 */ npm install -save-dev moduleName npm install -D moduleName /* 全局安裝模塊包 */ npm install -g moduleName /* 安裝特定版本的包 */ npm install 包名@版本號 /* 通過地址安裝git倉庫 */ npm install git+https://github.com/itwmike/axios.git npm install git+ssh://git@github.com:itwmike/axios.git /* 安裝特定分支或Tag的git倉庫 */ npm install git+https://github.com/itwmike/axios.git#tag /* 通過用戶名安裝git倉庫 */ npm install github:帳號/倉庫名 # npm install github:itwmike/axios npm install github:帳號/倉庫名
npm 依賴包版本號
npm 所有node包都使用語義化版本號,規則要求如下:
-
每個版本號都形如1.2.3,由三個部分組成,依次叫做“主版本號(major)”、“次版本號(minor)”和“修訂號(patch)” 。
-
當新版本無法兼容基於前一版本的代碼時,則提高主版本號 。
-
當新版本新增了功能與特性,但仍兼容前一版本的代碼時,則提高次版本號 。
-
當新版本僅僅修正漏洞或者增強效率,仍然兼容前一版本代碼,則提高修訂號。
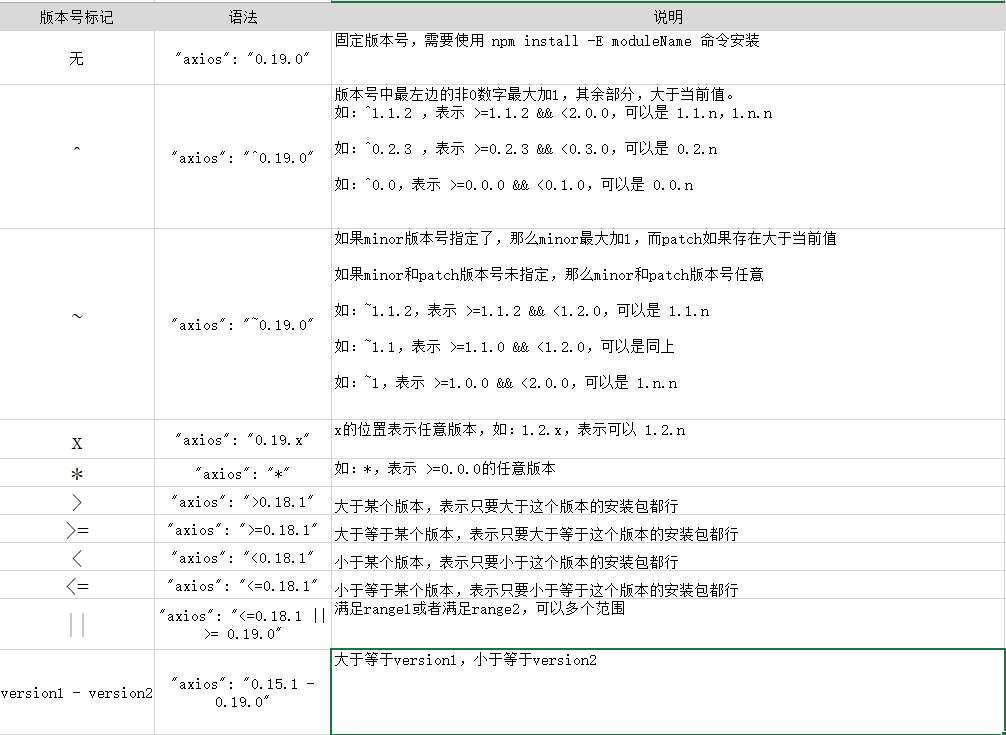
默認使用 npm install -save 下載的都是最新版本,同時會在package.json 文件中登記一個最優版本號,如下形式:
"dependencies": {
"axios": "^0.19.0"
},
最優版本號前面會多出一個“標記”,這個標記有啥意義?它的寫法又有哪些?
npm install 都做了哪些事?
拿到一個node項目時首要做法是運行 npm install 命令,這個命令將 package.json 文件中的依賴包自動解析並安裝,這也是項目能夠本地運行的前置條件。那如此簡單的一條命令,npm 背後又做了哪些不為人知的事呢?
Number One
自 npm 5.0后,項目中如果沒有 package-lock.json 文件的時候,npm 會自動幫我們生成。該文件的主要作用是記錄依賴包之間的具體版本號,對包版本有一個鎖定的意義,項目開發中應該將此文件上傳到git等版本控制工具(博主為此經歷了血淋淋的慘痛教育)。
Number Two
檢測本地包是否已經下載。如果本地 node_modules 下已經存在和 package-lock.json 中版本一致的包,則不會重新下載。
Number Three
下載依賴節點中對應的模板包。下載規則是:如果 package-lock.json 文件存在,則按照該文件中記錄的版本號下載對應的模塊包;如果文件不存在或文件中沒有該包的記錄,此時會按照版本號的標記(上面已講)規範下載並同時更新到 package-lock.json。
了解了 package-lock.json 的作用后,筆者有個疑問:手動修改 package.json 中的包版本號后運行 npm install 命令會下載新包么?
帶着這個疑問,筆者做了實驗,得出如下結論:
-
如果新舊版本號差距較大,比如從 ^2.5.2 變為 2.6.0 ,那麼會下載最新包並且更新 package-lock.json 。
-
如果新舊版本號差距較小,比如從 ^2.5.2 變為 2.5.4,那麼不會更新。
總之是否更新要看特定情況,取決於 package.json中版本號的標記和 package-lock.json 是否一致。
cnpm install 探索
cnpm 是淘寶 npm 鏡像,在國內很受歡迎,雖然筆者並不喜歡使用。那 cnpm 和 npm 對包的管理是否一樣呢?
-
cnpm install 並不會生成 package-lock.json
-
cnpm install 並不受 package-lock.json 的約束,它會按照版本號標記規則下載依賴包
由此可見,我們在項目中使用 cnpm 的時候一定要慎重,因為很可能團隊成員每個人使用的依賴包版本都不相同,造成打包后的結果也不同。
如果團隊要使用 cnpm,請使用固定版本號的方式安裝依賴包如:cnpm install -E moduleName
本文轉載自:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!