本文譯自:Generating C# .NET Classes at Runtime
作者:WedPort
在我的C#職業生涯中,有幾次我不得不在運行時生成新的類型。希望把它寫下來能幫助有相同應用需求的人。這也意味着我以後不必在查找相同問題的StackOverflow文章了。我最初是在.NET 4.6.2中這樣做的,但我已經更新到為.NET Core 3.0提供了示例。所有代碼都可以在我的GitHub上面找到。
GitHub:https://github.com/cheungt6/public/tree/master/ReflectionEmitClassGeneration
為什麼我需要在運行時生成類?
在運行時生產新類型的需求通常是由於運行時才知道類屬性,滿足性能要求以及需要在新類型中添加功能。當你嘗試這樣做的時候,你應該考慮的第一件事是:這是否真的是一個明智的解決方案。在深入思考之前,還有很多其他事情可以嘗試,問你自己這樣的問題:
- 我可以使用普通的類嗎
- 我可以使用Dictionary、Tuple或者對象數組(Array)?
- 我是否可以使用擴展對象
- 我確定我不能使用一個普通的類嗎?
如果你認為這仍然是必要的,請繼續閱讀下面的內容。
示例用例
作為一名開發人員,我將大量數據綁定到各種WPF Grids中。大多數時候屬性是固定的,我可以使用預定義的類。有時候,我不得不動態的構建網格,並且能夠在應用程序運行時更改數據。採取以下显示ID和一些財務數據的類(FTSE和CAC是指數,其屬性代表指數價格):
public class PriceHolderViewModel : ViewModelBase
{
public long Id { get; set; }
public decimal FTSE100 { get; set; }
public decimal CAC40 { get; set; }
}
如果我們僅對其中的屬性感興趣,該類定義的非常棒。但是,如果要使用更多屬性擴展此類,則需要在代碼中添加它,重新編譯並在新版本中進行部署。
相反的,我們可以做的是跟蹤對象所需的屬性,並在運行時構建類。這將允許我們在需要是不斷的添加和刪除屬性,並使用反射來更新它們的值。
// Keep track of my properties
var _properties = new Dictionary<string, Type>(new[]{
new KeyValuePair<string, Type>( "FTSE100", typeof(Decimal) ),
new KeyValuePair<string, Type>( "CAC40", typeof(Decimal) ) });
創建你的類型
下面的示例向您展示了如何在運行時構建新類型。你需要使用**System.Reflection.Emit**庫來構造一個新的動態程序集,您的類將在其中創建,然後是模塊和類型。與舊的** .NET Framework**框架不同,在舊的版本中,你需要在當前程序的AppDomain中創建程序集 ,而在** .NET Core** 中,AppDomain不再可用。你將看到我使用GUID創建了一個新類型名稱,以便於跟蹤類型的版本。在以前,你不能創建具有相同名稱的兩個類型,但是現在似乎不是這樣了。
public Type GeneratedType { private set; get; }
private void Initialise()
{
var newTypeName = Guid.NewGuid().ToString();
var assemblyName = new AssemblyName(newTypeName);
var dynamicAssembly = AssemblyBuilder.DefineDynamicAssembly(assemblyName, AssemblyBuilderAccess.Run);
var dynamicModule = dynamicAssembly.DefineDynamicModule("Main");
var dynamicType = dynamicModule.DefineType(newTypeName,
TypeAttributes.Public |
TypeAttributes.Class |
TypeAttributes.AutoClass |
TypeAttributes.AnsiClass |
TypeAttributes.BeforeFieldInit |
TypeAttributes.AutoLayout,
typeof(T)); // This is the type of class to derive from. Use null if there isn't one
dynamicType.DefineDefaultConstructor(MethodAttributes.Public |
MethodAttributes.SpecialName |
MethodAttributes.RTSpecialName);
foreach (var property in Properties)
AddProperty(dynamicType, property.Key, property.Value);
GeneratedType = dynamicType.CreateType();
}
在定義類型時,你可以提供一種類型,從中派生新的類型。如果你的基類具有要包含在新類型中的某些功能或屬性,這將非常有用。之前,我曾使用它在運行時擴展ViewModel和Serializable類型。
在你創建了TypeBuilder后,你可以使用下面提供的代碼開始添加屬性。它創建了支持字段和所需的中間語言,以便通過Getter和Setter訪問它們。為每個屬性完成此操作后,可以使用CreateType()創建類型的實例。
private static void AddProperty(TypeBuilder typeBuilder, string propertyName, Type propertyType)
{
var fieldBuilder = typeBuilder.DefineField("_" + propertyName, propertyType, FieldAttributes.Private);
var propertyBuilder = typeBuilder.DefineProperty(propertyName, PropertyAttributes.HasDefault, propertyType, null);
var getMethod = typeBuilder.DefineMethod("get_" + propertyName,
MethodAttributes.Public |
MethodAttributes.SpecialName |
MethodAttributes.HideBySig, propertyType, Type.EmptyTypes);
var getMethodIL = getMethod.GetILGenerator();
getMethodIL.Emit(OpCodes.Ldarg_0);
getMethodIL.Emit(OpCodes.Ldfld, fieldBuilder);
getMethodIL.Emit(OpCodes.Ret);
var setMethod = typeBuilder.DefineMethod("set_" + propertyName,
MethodAttributes.Public |
MethodAttributes.SpecialName |
MethodAttributes.HideBySig,
null, new[] { propertyType });
var setMethodIL = setMethod.GetILGenerator();
Label modifyProperty = setMethodIL.DefineLabel();
Label exitSet = setMethodIL.DefineLabel();
setMethodIL.MarkLabel(modifyProperty);
setMethodIL.Emit(OpCodes.Ldarg_0);
setMethodIL.Emit(OpCodes.Ldarg_1);
setMethodIL.Emit(OpCodes.Stfld, fieldBuilder);
setMethodIL.Emit(OpCodes.Nop);
setMethodIL.MarkLabel(exitSet);
setMethodIL.Emit(OpCodes.Ret);
propertyBuilder.SetGetMethod(getMethod);
propertyBuilder.SetSetMethod(setMethod);
}
有了類型后,就很容易通過使用Activator.CreateInstance()來創建它的實例。但是,你希望能夠更改已創建的屬性的值,為了做到這一點,你可以再次使用反射來獲取propertyInfos並提取Set方法。一旦有了這些屬性,電影它們類設置屬性值就相對簡單了。
foreach (var property in Properties)
{
var propertyInfo = GeneratedType.GetProperty(property.Key);
var setMethod = propertyInfo.GetSetMethod();
setMethod.Invoke(objectInstance, new[] { propertyValue });
}
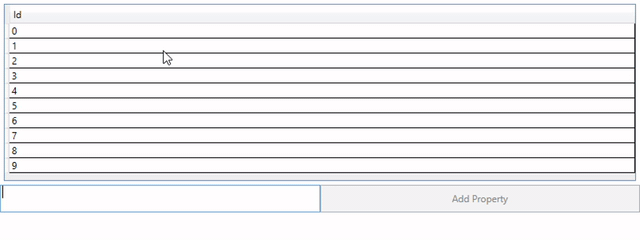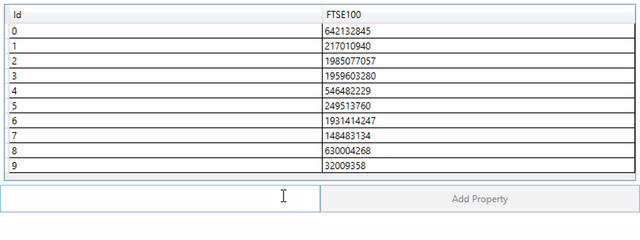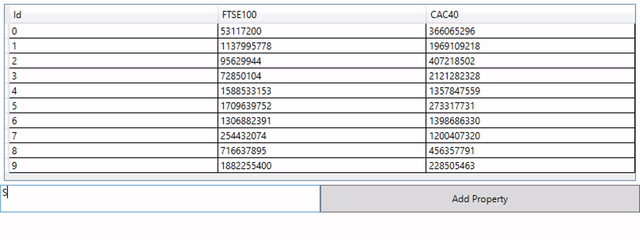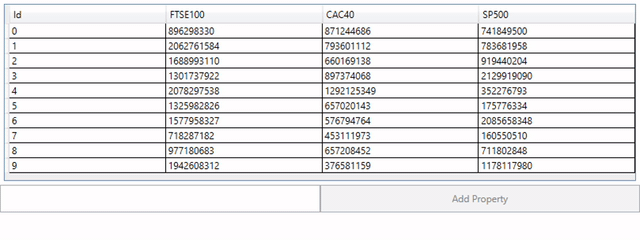
現在,您可以在運行時使用自定義屬性來創建自己的類型,並具有更新其值的功能,一切就緒。 我發現的唯一障礙是創建一個可以存儲新類型實例的列表。 WPF中的DataGrid傾向於只讀取List的常規參數類型的屬性。 這意味着即使您使用新屬性擴展了基類,使用AutoGenerateProperties也只能看到基類中的屬性。 解決方案是使用生成的類型顯式創建一個新的List。 我在下面提供了如何執行此操作的示例:
var listGenericType = typeof(List<>);
var list = listGenericType.MakeGenericType(GeneratedType);
var constructor = list.GetConstructor(new Type[] { });
var newList = (IList)constructor.Invoke(new object[] { });
foreach (var value in values)
newList.Add(value);
結論
我已經在GitHub中創建了一個示例應用程序。它包含一個UI來幫助您調試和理解運行時新類型的創建,以及如何更新值。如果您有任何問題或意見,請隨時與我們聯繫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?