線上服務的GC問題,是Java程序非常典型的一類問題,非常考驗工程師排查問題的能力。同時,幾乎是面試必考題,但是能真正答好此題的人並不多,要麼原理沒吃透,要麼缺乏實戰經驗。
過去半年時間里,我們的廣告系統出現了多次和GC相關的線上問題,有Full GC過於頻繁的,有Young GC耗時過長的,這些問題帶來的影響是:GC過程中的程序卡頓,進一步導致服務超時從而影響到廣告收入。
這篇文章,我將以一個FGC頻繁的線上案例作為引子,詳細介紹下GC的排查過程,另外會結合GC的運行原理給出一份實踐指南,希望對你有所幫助。內容分成以下3個部分:
1、從一次FGC頻繁的線上案例說起
2、GC的運行原理介紹
3、排查FGC問題的實踐指南
01 從一次FGC頻繁的線上案例說起
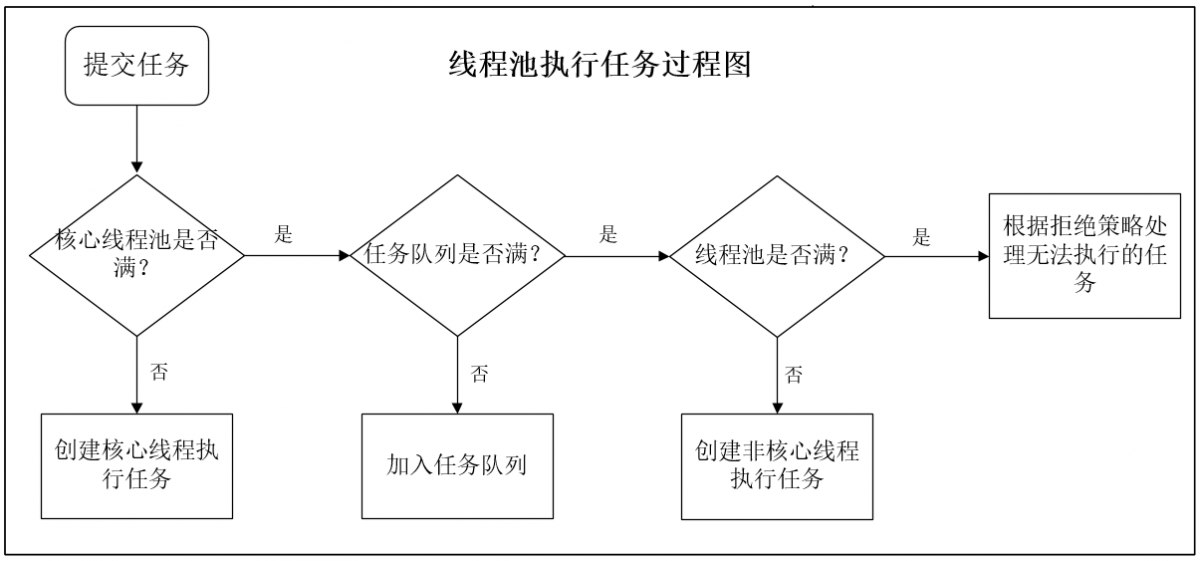
去年10月份,我們的廣告召回系統在程序上線后收到了FGC頻繁的系統告警,通過下面的監控圖可以看到:平均每35分鐘就進行了一次FGC。而程序上線前,我們的FGC頻次大概是2天一次。下面,詳細介紹下該問題的排查過程。
1. 檢查JVM配置
通過以下命令查看JVM的啟動參數:
ps aux | grep “applicationName=adsearch”
-Xms4g -Xmx4g -Xmn2g -Xss1024K
-XX:ParallelGCThreads=5
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+UseCMSCompactAtFullCollection
-XX:CMSInitiatingOccupancyFraction=80
可以看到堆內存為4G,新生代為2G,老年代也為2G,新生代採用ParNew收集器,老年代採用併發標記清除的CMS收集器,當老年代的內存佔用率達到80%時會進行FGC。
進一步通過 jmap -heap 7276 | head -n20 可以得知新生代的Eden區為1.6G,S0和S1區均為0.2G。
2. 觀察老年代的內存變化
通過觀察老年代的使用情況,可以看到:每次FGC后,內存都能回到500M左右,因此我們排除了內存泄漏的情況。
3. 通過jmap命令查看堆內存中的對象
通過命令 jmap -histo 7276 | head -n20
上圖中,按照對象所佔內存大小排序,显示了存活對象的實例數、所佔內存、類名。可以看到排名第一的是:int[],而且所佔內存大小遠遠超過其他存活對象。至此,我們將懷疑目標鎖定在了 int[] .
4. 進一步dump堆內存文件進行分析
鎖定 int[] 后,我們打算dump堆內存文件,通過可視化工具進一步跟蹤對象的來源。考慮堆轉儲過程中會暫停程序,因此我們先從服務管理平台摘掉了此節點,然後通過以下命令dump堆內存:
jmap -dump:format=b,file=heap 7276
通過JVisualVM工具導入dump出來的堆內存文件,同樣可以看到各個對象所佔空間,其中int[]佔到了50%以上的內存,進一步往下便可以找到 int[] 所屬的業務對象,發現它來自於架構團隊提供的codis基礎組件。
5. 通過代碼分析可疑對象
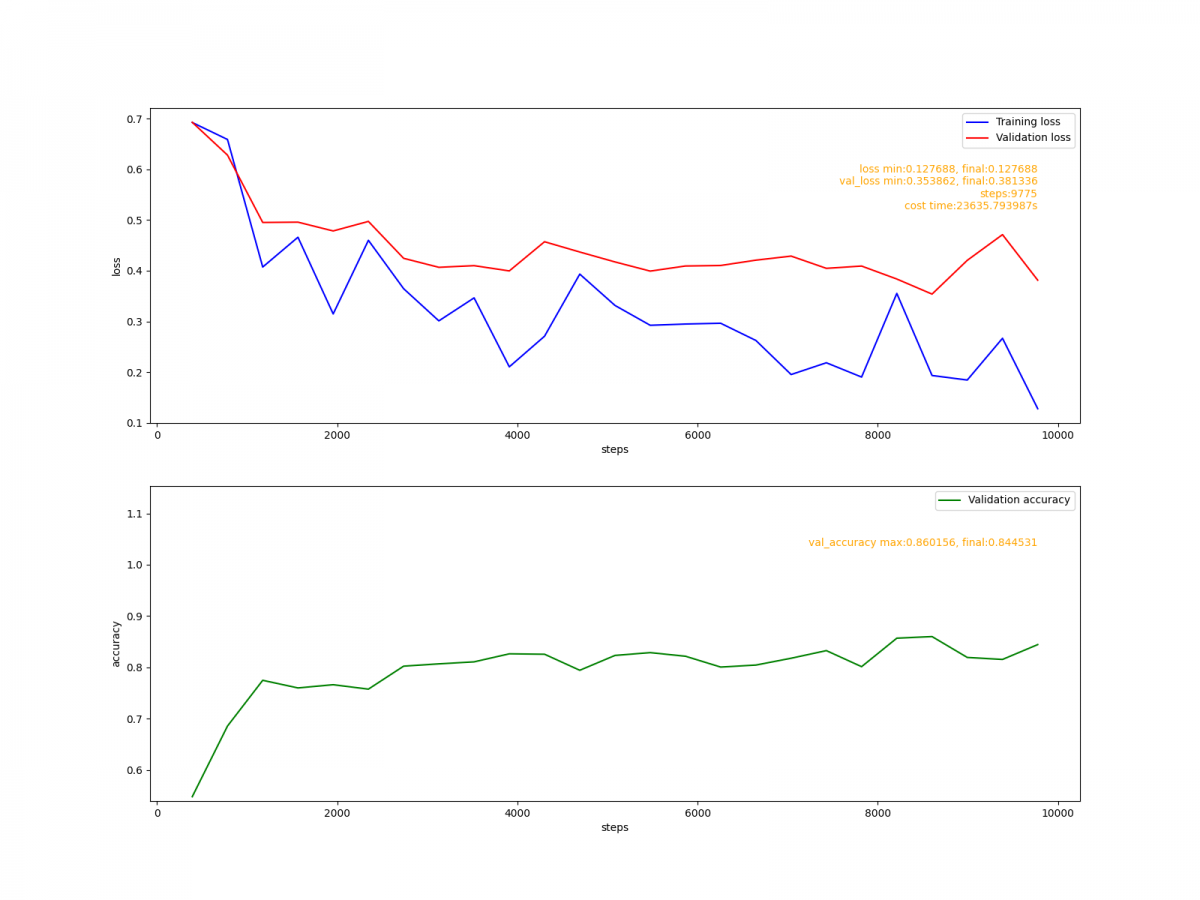
通過代碼分析,codis基礎組件每分鐘會生成約40M大小的int數組,用於統計TP99 和 TP90,數組的生命周期是一分鐘。而根據第2步觀察老年代的內存變化時,發現老年代的內存基本上也是每分鐘增加40多M,因此推斷:這40M的int數組應該是從新生代晉陞到老年代。
我們進一步查看了YGC的頻次監控,通過下圖可以看到大概1分鐘有8次左右的YGC,這樣基本驗證了我們的推斷:因為CMS收集器默認的分代年齡是6次,即YGC 6次后還存活的對象就會晉陞到老年代,而codis組件中的大數組生命周期是1分鐘,剛好滿足這個要求。
至此,整個排查過程基本結束了,那為什麼程序上線前沒出現此問題呢?通過上圖可以看到:程序上線前YGC的頻次在5次左右,此次上線后YGC頻次變成了8次左右,從而引發了此問題。
6. 解決方案
為了快速解決問題,我們將CMS收集器的分代年齡改成了15次,改完后FGC頻次恢復到了2天一次,後續如果YGC的頻次超過每分鐘15次還會再次觸發此問題。當然,我們最根本的解決方案是:優化程序以降低YGC的頻率,同時縮短codis組件中int數組的生命周期,這裏就不做展開了。
02 GC的運行原理介紹
上面整個案例的分析過程中,其實涉及到很多GC的原理知識,如果不懂得這些原理就着手處理,其實整個排查過程是很抓瞎的。
這裏,我選擇幾個最核心的知識點,展開介紹下GC的運行原理,最後再給出一份實踐指南。
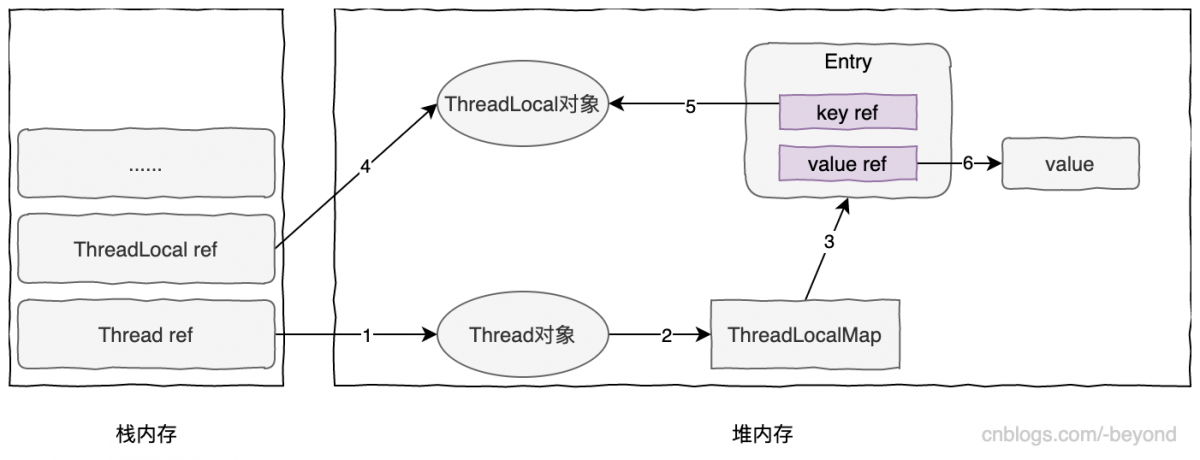
1. 堆內存結構
大家都知道: GC分為YGC和FGC,它們均發生在JVM的堆內存上。先來看下JDK8的堆內存結構:
可以看到,堆內存採用了分代結構,包括新生代和老年代。新生代又分為:Eden區,From Survivor區(簡稱S0),To Survivor區(簡稱S1區),三者的默認比例為8:1:1。另外,新生代和老年代的默認比例為1:2。
堆內存之所以採用分代結構,是考慮到絕大部分對象都是短生命周期的,這樣不同生命周期的對象可放在不同的區域中,然後針對新生代和老年代採用不同的垃圾回收算法,從而使得GC效率最高。
2. YGC是什麼時候觸發的?
大多數情況下,對象直接在年輕代中的Eden區進行分配,如果Eden區域沒有足夠的空間,那麼就會觸發YGC(Minor GC),YGC處理的區域只有新生代。因為大部分對象在短時間內都是可收回掉的,因此YGC后只有極少數的對象能存活下來,而被移動到S0區(採用的是複製算法)。
當觸發下一次YGC時,會將Eden區和S0區的存活對象移動到S1區,同時清空Eden區和S0區。當再次觸發YGC時,這時候處理的區域就變成了Eden區和S1區(即S0和S1進行角色交換)。每經過一次YGC,存活對象的年齡就會加1。
3. FGC又是什麼時候觸發的?
下面4種情況,對象會進入到老年代中:
1、YGC時,To Survivor區不足以存放存活的對象,對象會直接進入到老年代。
2、經過多次YGC后,如果存活對象的年齡達到了設定閾值,則會晉陞到老年代中。
3、動態年齡判定規則,To Survivor區中相同年齡的對象,如果其大小之和佔到了 To Survivor區一半以上的空間,那麼大於此年齡的對象會直接進入老年代,而不需要達到默認的分代年齡。
4、大對象:由-XX:PretenureSizeThreshold啟動參數控制,若對象大小大於此值,就會繞過新生代, 直接在老年代中分配。
當晉陞到老年代的對象大於了老年代的剩餘空間時,就會觸發FGC(Major GC),FGC處理的區域同時包括新生代和老年代。除此之外,還有以下4種情況也會觸發FGC:
1、老年代的內存使用率達到了一定閾值(可通過參數調整),直接觸發FGC。
2、空間分配擔保:在YGC之前,會先檢查老年代最大可用的連續空間是否大於新生代所有對象的總空間。如果小於,說明YGC是不安全的,則會查看參數 HandlePromotionFailure 是否被設置成了允許擔保失敗,如果不允許則直接觸發Full GC;如果允許,那麼會進一步檢查老年代最大可用的連續空間是否大於歷次晉陞到老年代對象的平均大小,如果小於也會觸發 Full GC。
3、Metaspace(元空間)在空間不足時會進行擴容,當擴容到了-XX:MetaspaceSize 參數的指定值時,也會觸發FGC。
4、System.gc() 或者Runtime.gc() 被顯式調用時,觸發FGC。
4. 在什麼情況下,GC會對程序產生影響?
不管YGC還是FGC,都會造成一定程度的程序卡頓(即Stop The World問題:GC線程開始工作,其他工作線程被掛起),即使採用ParNew、CMS或者G1這些更先進的垃圾回收算法,也只是在減少卡頓時間,而並不能完全消除卡頓。
那到底什麼情況下,GC會對程序產生影響呢?根據嚴重程度從高到底,我認為包括以下4種情況:
1、FGC過於頻繁:FGC通常是比較慢的,少則幾百毫秒,多則幾秒,正常情況FGC每隔幾個小時甚至幾天才執行一次,對系統的影響還能接受。但是,一旦出現FGC頻繁(比如幾十分鐘就會執行一次),這種肯定是存在問題的,它會導致工作線程頻繁被停止,讓系統看起來一直有卡頓現象,也會使得程序的整體性能變差。
2、YGC耗時過長:一般來說,YGC的總耗時在幾十或者上百毫秒是比較正常的,雖然會引起系統卡頓幾毫秒或者幾十毫秒,這種情況幾乎對用戶無感知,對程序的影響可以忽略不計。但是如果YGC耗時達到了1秒甚至幾秒(都快趕上FGC的耗時了),那卡頓時間就會增大,加上YGC本身比較頻繁,就會導致比較多的服務超時問題。
3、FGC耗時過長:FGC耗時增加,卡頓時間也會隨之增加,尤其對於高併發服務,可能導致FGC期間比較多的超時問題,可用性降低,這種也需要關注。
4、YGC過於頻繁:即使YGC不會引起服務超時,但是YGC過於頻繁也會降低服務的整體性能,對於高併發服務也是需要關注的。
其中,「FGC過於頻繁」和「YGC耗時過長」,這兩種情況屬於比較典型的GC問題,大概率會對程序的服務質量產生影響。剩餘兩種情況的嚴重程度低一些,但是對於高併發或者高可用的程序也需要關注。
03 排查FGC問題的實踐指南
通過上面的案例分析以及理論介紹,再總結下FGC問題的排查思路,作為一份實踐指南供大家參考。
1. 清楚從程序角度,有哪些原因導致FGC?
1、大對象:系統一次性加載了過多數據到內存中(比如SQL查詢未做分頁),導致大對象進入了老年代。
2、內存泄漏:頻繁創建了大量對象,但是無法被回收(比如IO對象使用完后未調用close方法釋放資源),先引發FGC,最後導致OOM.
3、程序頻繁生成一些長生命周期的對象,當這些對象的存活年齡超過分代年齡時便會進入老年代,最後引發FGC. (即本文中的案例)
4、程序BUG導致動態生成了很多新類,使得 Metaspace 不斷被佔用,先引發FGC,最後導致OOM.
5、代碼中顯式調用了gc方法,包括自己的代碼甚至框架中的代碼。
6、JVM參數設置問題:包括總內存大小、新生代和老年代的大小、Eden區和S區的大小、元空間大小、垃圾回收算法等等。
2. 清楚排查問題時能使用哪些工具
1、公司的監控系統:大部分公司都會有,可全方位監控JVM的各項指標。
2、JDK的自帶工具,包括jmap、jstat等常用命令:
查看堆內存各區域的使用率以及GC情況
jstat -gcutil -h20 pid 1000查看堆內存中的存活對象,並按空間排序
jmap -histo pid | head -n20dump堆內存文件
jmap -dump:format=b,file=heap pid3、可視化的堆內存分析工具:JVisualVM、MAT等
3. 排查指南
1、查看監控,以了解出現問題的時間點以及當前FGC的頻率(可對比正常情況看頻率是否正常)
2、了解該時間點之前有沒有程序上線、基礎組件升級等情況。
3、了解JVM的參數設置,包括:堆空間各個區域的大小設置,新生代和老年代分別採用了哪些垃圾收集器,然後分析JVM參數設置是否合理。
4、再對步驟1中列出的可能原因做排除法,其中元空間被打滿、內存泄漏、代碼顯式調用gc方法比較容易排查。
5、針對大對象或者長生命周期對象導致的FGC,可通過 jmap -histo 命令並結合dump堆內存文件作進一步分析,需要先定位到可疑對象。
6、通過可疑對象定位到具體代碼再次分析,這時候要結合GC原理和JVM參數設置,弄清楚可疑對象是否滿足了進入到老年代的條件才能下結論。
04 最後的話
這篇文章通過線上案例並結合GC原理詳細介紹了FGC的排查過程,同時給出了一份實踐指南。
後續會以類似的方式,再分享一個YGC耗時過長的案例,希望能幫助大家吃透GC問題排查,如果覺得本文對你有幫助,請大家關注我的個人公眾號!
– End –
作者簡介:程序員,985碩士,前亞馬遜Java工程師,現58轉轉技術總監。持續分享技術和管理方向的文章。如果感興趣,可微信掃描下面的二維碼關注我的公眾號:『IT人的職場進階』
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?