一 Kubetcl namespace
1.1 namespace描述
Kubernetes namespace提供了將一組相關資源組合在一起的機制。在Red Hat OpenShift容器平台中,project是一個帶有附加註釋的Kubernetes namespace。
namespace提供以下特性:
- 命名資源,以避免基本的命名衝突;
- 將管理權限授予受信任的用戶;
- 限制用戶資源消耗的能力;
- 用戶和用戶組隔離。
1.2 project
project提供了一種機制,通過這種機制可以管理普通用戶對資源的訪問。project允許一組用戶獨立於其他組組織和管理其內容,必須允許用戶訪問項目。如果允許創建項目,用戶將自動訪問自己的項目。
項目可以有單獨的name、display name和description。
name是項目的唯一標識符,在使用CLI工具或API時都是基於name,name的最大長度為63個字符。
display name是項目在web控制台中显示的方式(默認為name)。
description是項目的更詳細描述,並且在web控制台中也可見。
以下組件適用於項目:
- Object:pod、service、rc等;
- Policies:決定用戶可以或不能對對象執行哪些操作的規則;
- Constraints:可以限制的每種對象的配額。
1.3 cluster管理
集群管理員可以創建項目並將項目的管理權限委託給任何用戶。在OpenShift容器平台中,項目用於對相關對象進行分組和隔離。
管理員可以讓用戶訪問某些項目,允許他們創建自己的項目,並在單個項目中賦予他們管理權限。
管理員可以將角色應用於允許或限制其創建項目能力的用戶和組,同時可以在用戶初始登錄之前分配角色。
限制項目創建:從通過身份驗證的用戶和組中刪除self-provisioning集群角色,將拒絕任何新項目的權限。
[root@master ~]$ oc adm policy remove-cluster-role-from-group \
self-provisioner \
system:authenticated \
system:authenticated:oauth
授予項目創建:項目創建授予具有self-供應者角色和self-provisione集群角色綁定的用戶。默認情況下,所有經過身份驗證的用戶都可以使用這些角色。
[root@master ~]$ oc adm policy add-cluster-role-to-group \
self-provisioner \
system:authenticated \
system:authenticated:oauth
1.4 創建project
如果項目創建權限被授予用戶,則可以使用oc命令創建project。
[root@master ~]$ oc new-project demoproject \
–description=”Demonstrate project creation” \
–display-name=”demo_project”
二 OpenShift角色
2.1 角色概述
role具有不同級別的訪問和策略,包括集群和本地策略。user和group可以同時與多個role關聯。運行oc description命令查看角色及其綁定的詳細信息。
在集群策略中具有cluster-admin缺省角色的用戶可以查看集群策略和所有本地策略。在給定的本地策略中具有admin缺省角色的用戶可以基於per-project查看策略。
可通過以下命令查看當前的集群綁定集,其中显示綁定到不同角色的用戶和組。
[root@demo ~]# oc describe clusterPolicyBindings :default
2.2 查看本地policy
儘管本地角色列表及其關聯的規則集在本地策略中是不可查看的,但是所有缺省角色仍然適用,並且可以添加到用戶或組中,cluster-admin缺省角色除外。但是,本地綁定是可見的。
可通過以下命令查看當前的本地綁定,其中显示綁定到不同角色的用戶和組。
[root@demo ~]# oc describe policyBindings :default
提示:默認情況下,在本地策略中,只會列出admin角色的綁定。但是,如果將其他默認角色添加到本地策略中的用戶和組,也會列出它們。
2.3 管理role綁定
向用戶或組添加或綁定角色,從而實現向用戶或組提供角色授予的相關訪問權限。可以使用oc adm policy命令在用戶和組之間添加和刪除角色。
當使用以下操作管理本地策略的用戶和組角色時,可以使用-n選項指定項目。如果沒有指定,則使用當前項目。
常見管理本地策略操作:
還可以使用如下所示的的操作管理cluster policy的role binding,這類命令不需要-n選項,因為cluster policy不在namespace級別上操作。
常見管理cluster policy操作:
提示:oc policy命令應用於當前項目,而oc adm policy命令應用於集群範圍的操作。
示例:在example項目中為developer用戶提供admin角色。
[root@demo ~]# oc adm policy add-role-to-user admin developer -n example
[root@demo ~]# oc describe policybindings :default -n example #檢查綁定
三 安全上下文約束(SCCS)
3.1 SCCS概述
OpenShift提供安全上下文約束(SCCS),它控制pod可以執行的操作和它可以訪問的資源。默認情況下,任何容器的執行都只授予受限制的SCC定義的功能。
SCCS相關命令:
1 [user@demo ~]$ oc get scc #列出可用的SCC 2 [user@demo ~]$ oc describe scc scc_name #現實特定SCC詳細信息 3 [user@demo ~]$ oc adm policy add-scc-to-user scc_name user_name 4 [user@demo ~]$ oc adm policy add-scc-to-group scc_name group_name #要授予用戶或組特定的SCC 5 [user@demo ~]$ oc adm policy remove-scc-from-user scc_name user_name 6 [user@demo ~]$ oc adm policy remove-scc-from-group scc_name group_name #從特定的SCC中刪除用戶或組
四 服務賬戶
4.1 服務賬戶
service account提供了一種靈活的方法來控制API訪問,而無需共享常規用戶的憑據。如果應用程序需要訪問受限制的SCC未授予的功能,可創建一個新的、特定的service account並將其添加到適當的SCC中。
例如,在缺省情況下,OpenShift不支持部署需要提升特權的應用程序。若有此需求,可創建一個service account,修改dc,然後添加service account至SCC。
示例:將anyuid配置為在容器中作為root用戶運行。
[user@demo ~]$ oc create serviceaccount useroot #創建一個名為useroot的新服務帳戶
[user@demo ~]$ oc patch dc/demo-app \
–patch ‘{“spec”:{“template”:{“spec”:{“serviceAccountName”: “useroot”}}}}’ #修改應用程序的DC
[user@demo ~]$ oc adm policy add-scc-to-user anyuid -z useroot #將useroot服務帳戶添加到anyuid SCC中,作為容器中的根用戶運行
4.2 Web管理user成員
OCP平台的默認配置是,在用戶首次登錄成功時,自動創建該用戶對象。
要管理允許訪問項目的用戶,請以項目管理員或集群管理員的身份登錄到web控制台,並選擇要管理的項目。在左側窗格中,單擊Resources——>membership進入項目member頁面。
在Users列中,在突出显示的文本框中輸入用戶名。在“添加另一個角色”列中,從用戶所在行的列表中選擇一個角色,然後單擊“添加”。
4.3 Cli管理user成員
CLI中如果自動創建對象功能被關閉,集群管理員可通過如下方式創建新用戶:
[root@master ~]$ oc create user demo-user
同時還需要在身份認證軟件中創建用戶,如為HTPasswdIdentityProvider才用戶命令如下:
[root@master ~]$ htpasswd /etc/origin/openshift-passwd demo-user
要向用戶添加項目角色,首先使用oc project命令輸入項目,然後使用oc policy add-role-to-user命令:
[root@master ~]$ oc policy add-role-to-user edit demo-user
要從用戶中刪除項目角色,使用oc policy remove-role-from-user命令:
[root@master ~]$ oc policy remove-role-from-user edit demo-user
並不是所有OpenShift角色都由項目限定範圍。要分配這些規則,請使用oc adm policy command命令。
[root@master ~]$ oc adm policy add-cluster-role-to-user cluster-admin admin
4.4 身份驗證和授權
身份驗證層標識與對OpenShift容器平台API的請求相關聯的用戶,然後授權層使用關於請求用戶的身份信息來確定是否應該允許該請求。
- user和group
OCP容器平台中的用戶是一個可以向OpenShift API發出請求的實體。通常,這表示與OpenShift交互的develop或administrator的帳戶。
可以將用戶分配給一個或多個組,每個組表示一組特定的角色(或權限)。當需要通過管理授權策略給多個客戶授權時候,group會比較合適。例如允許訪問項目中的對象,而不是單獨授予用戶。
- Authentication Tokens
API調用必須使用訪問令牌或X.509證書進行身份驗證,會話token表示用戶,並且是短期的,默認情況下在24小時內到期。
可以通過運行oc whoami命令來驗證經過身份驗證的用戶。
[root@master ~]$ oc login -u demo-user
[root@master ~]$ oc whoami
demo-user
4.5 身份驗證類型
本環境中,身份驗證由HTPasswdIdentityProvider模塊提供,該模塊根據使用htpasswd命令生成的文件驗證用戶名和密碼。
OpenShift容器平台支持的其他認證類型包括:
- Basic Authentication (Remote)
一種通用的後端集成機制,允許用戶使用針對遠程標識提供者驗證的憑據登錄到OpenShift容器平台。用戶將他們的用戶名和密碼發送到OpenShift容器平台,OpenShift平台通過到服務器的請求驗證這些憑據,並將憑據作為基本的Auth頭傳遞。這要求用戶在登錄過程中向OpenShift容器平台輸入他們的憑據。
- Request Header Authentication
用戶使用請求頭值(如X-RemoteUser)登錄到OpenShift容器平台。它通常與身份驗證代理結合使用,身份驗證代理對用戶進行身份驗證,然後通過請求頭值為OpenShift容器平台提供用戶標識。
- Keystone Authentication
Keystone是一個OpenStack項目,提供標識、令牌、目錄和策略服務。OpenShift容器平台與Keystone集成,通過配置OpenStack Keystone v3服務器將用戶存儲在內部數據庫中,從而支持共享身份驗證。這種配置允許用戶使用Keystone憑證登錄OpenShift容器平台。
- LDAP Authentication
用戶使用他們的LDAP憑證登錄到OpenShift容器平台。在身份驗證期間,LDAP目錄將搜索與提供的用戶名匹配的條目。如果找到匹配項,則嘗試使用條目的專有名稱(DN)和提供的密碼進行簡單綁定。
- GitHub Authentication
GitHub使用OAuth,它允許與OpenShift容器平台集成使用OAuth身份驗證來促進令牌交換流。這允許用戶使用他們的GitHub憑證登錄到OpenShift容器平台。為了防止使用GitHub用戶id的未授權用戶登錄到OpenShift容器平台集群,可以將訪問權限限制在特定的GitHub組織中。
五 管理項目及賬戶
5.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
5.2 本練習準備
[student@workstation ~]$ lab secure-resources setup
5.3 創建htpasswd賬戶
1 [kiosk@foundation0 ~]$ ssh root@master 2 [root@master ~]# htpasswd -b /etc/origin/master/htpasswd user1 redhat 3 [root@master ~]# htpasswd -b /etc/origin/master/htpasswd user2 redhat 4 #添加基於htpasswd形式的user1和user2,密碼都為redhat。
5.4 設置策略
1 [student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com #使用管理員登錄 2 [student@workstation ~]$ oc adm policy remove-cluster-role-from-group \ 3 self-provisioner system:authenticated:oauth 4 #刪除所有賦予普通創建項目的功能,該命令可參考本環境如下目錄中的命令。 5 [student@workstation ~]$ cat /home/student/DO280/labs/secure-resources/configure-policy.sh 6 #!/bin/bash 7 oc adm policy remove-cluster-role-from-group \ 8 self-provisioner system:authenticated system:authenticated:oauth
5.5 驗證策略
1 [student@workstation ~]$ oc login -u user1 -p redhat https://master.lab.example.com #使用普通用戶user1登錄 2 [student@workstation ~]$ oc new-project test #測試創建project 3 Error from server (Forbidden): You may not request a new project via this API.
5.6 創建項目
1 [student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com #使用集群管理員登錄 2 [student@workstation ~]$ oc new-project project-user1 #創建兩個項目 3 [student@workstation ~]$ oc new-project project-user2
5.7 將項目與user關聯
1 #選擇項目1 2 Now using project "project-user1" on server "https://master.lab.example.com:443". 3 [student@workstation ~]$ oc policy add-role-to-user admin user1 #將user1添加為項目1的管理員 4 role "admin" added: "user1" 5 [student@workstation ~]$ oc policy add-role-to-user edit user2 #將user2添加為項目1的開發員 6 role "edit" added: "user2" 7 8 [student@workstation ~]$ oc project project-user2 #選擇項目2 9 Now using project "project-user2" on server "https://master.lab.example.com:443". 10 [student@workstation ~]$ oc policy add-role-to-user edit user2 #將user2添加為項目2的開發員 11 role "edit" added: "user2"
5.8 驗證訪問
1 [student@workstation ~]$ oc login -u user1 -p redhat https://master.lab.example.com #使用user1登錄 2 [student@workstation ~]$ oc project project-user1 #驗證項目1的訪問 3 Already on project "project-user1" on server "https://master.lab.example.com:443". 4 [student@workstation ~]$ oc project project-user2 #驗證項目2的訪問 5 error: You are not a member of project "project-user2". 6 You have one project on this server: project-user1 7 8 [student@workstation ~]$ oc login -u user2 -p redhat https://master.lab.example.com #使用user2登錄 9 [student@workstation ~]$ oc project project-user1 10 Already on project "project-user1" on server "https://master.lab.example.com:443". #驗證項目1的訪問 11 [student@workstation ~]$ oc project project-user2 12 Now using project "project-user2" on server "https://master.lab.example.com:443". #驗證項目2的訪問
5.9 部署特權應用
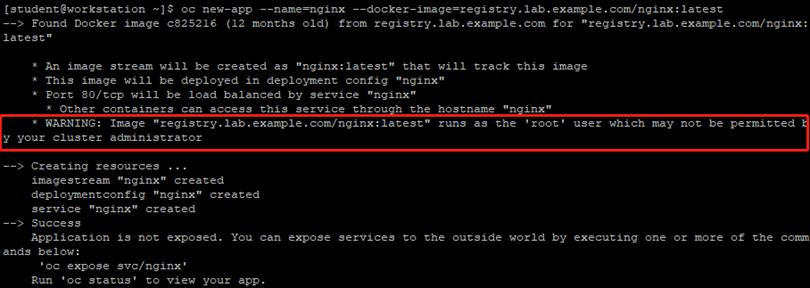
1 [student@workstation ~]$ oc login -u user2 -p redhat https://master.lab.example.com 2 [student@workstation ~]$ oc project project-user1 3 Now using project "project-user1" on server "https://master.lab.example.com:443". 4 [student@workstation ~]$ oc new-app --name=nginx --docker-image=registry.lab.example.com/nginx:latest 5 #使用在項目1上不具備admin權限的用戶user2登錄,並部署應用,會出現如下提示:
5.10 驗證部署
1 [student@workstation ~]$ oc get pods
結論:由上可知,部署失敗是因為容器映像需要root用戶,pod以CrashLoopBackOff或錯誤狀態結束。
5.11 故障排除
若要解決此故障需要減少特定項目的安全限制。
要使用特權訪問運行容器,可創建一個允許pod使用操作系統普通用戶運行的service account。
如下部分需要具有項目管理員特權的用戶執行,而另一些操作需要具有集群管理員特權的用戶執行。
本環境中,相關操作命令可以從/home/student/DO280/labs/secure-resources文件夾中的configure-sc.sh腳本運行或複製。
1 [student@workstation ~]$ oc login -u user1 -p redhat https://master.lab.example.com #使用項目1的admin賬戶登錄 2 [student@workstation ~]$ oc create serviceaccount useroot #創建服務賬戶 3 serviceaccount "useroot" created 4 [student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com #使用集群管理員登錄 5 [student@workstation ~]$ oc project project-user1 #選擇項目1 6 Already on project "project-user1" on server "https://master.lab.example.com:443". 7 [student@workstation ~]$ oc adm policy add-scc-to-user anyuid -z useroot #設置SCC策略 8 scc "anyuid" added to: ["system:serviceaccount:project-user1:useroot"] #將服務帳戶與anyuid安全上下文關聯,此操作需要集群管理員用戶。 9 [student@workstation ~]$ oc login -u user2 -p redhat https://master.lab.example.com #切換user2用戶 10 [student@workstation ~]$ oc project project-user1 11 Already on project "project-user1" on server "https://master.lab.example.com:443". 12 [student@workstation ~]$ oc patch dc nginx --patch='{"spec":{"template":{"spec":{"serviceAccountName": "useroot"}}}}'
#更新負責管理nginx的dc資源,任何開發人員用戶都可以執行此操作。本環境中,相關操作命令可以從/home/student/DO280/labs/secure-resources文件夾中的configure-sc.sh腳本運行或複製。
5.12 驗證確認
1 [student@workstation ~]$ oc get pods 2 NAME READY STATUS RESTARTS AGE 3 nginx-2-98k8f 1/1 Running 0 3m 4
5.13 暴露服務
1 [student@workstation ~]$ oc expose svc nginx 2 route "nginx" exposed 3 [student@workstation ~]$ oc get svc 4 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE 5 nginx ClusterIP 172.30.118.63 <none> 80/TCP 13m 6 [student@workstation ~]$ oc get route 7 NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD 8 nginx nginx-project-user1.apps.lab.example.com nginx 80-tcp None
5.14 測試訪問
1 [student@workstation ~]$ curl -s http://nginx-project-user1.apps.lab.example.com
5.15 策略刪除演示
1 [student@workstation ~]$ oc login -u admin -p redhat 2 [student@workstation ~]$ oc adm policy add-cluster-role-to-group self-provisioner system:authenticated system:authenticated:oauth 3 cluster role "self-provisioner" added: ["system:authenticated" "system:authenticated:oauth"] 4 [student@workstation ~]$ oc delete project project-user1 5 project "project-user1" deleted 6 [student@workstation ~]$ oc delete project project-user2 7 [root@master ~]# htpasswd -D /etc/origin/master/htpasswd user1 8 [root@master ~]# htpasswd -D /etc/origin/master/htpasswd user2
#為所有常規用戶重新啟用項目創建,即重置為初始狀態。本環境中,相關操作命令可以從/home/student/DO280/labs/secure-resources文件夾中的restore-policy.sh腳本運行或複製。
六 管理加密信息
6.1 secret特性
Secret對象類型提供了一種機制來保存敏感信息,如密碼、OCP客戶端配置文件、Docker配置文件和私有倉庫憑據。Secrets將敏感內容與Pod解耦。可以使用Volume插件將Secrets掛載到容器上,或者系統可以使用Secrets代表pod執行操作。
Secrets的主要特徵包括:
- Secrets data可以獨立於其定義引用。
- Secrets data Volume由臨時文件存儲支持。
- 可以在名稱空間中共享Secrets data。
6.2 創建Secrets
在依賴於該Secrets的pod之前創建一個Secrets。
1 [user@demo ~]$ oc create secret generic secret_name \ 2 --from-literal=key1=secret1 \ 3 --from-literal=key2=secret2 #用secret data創建secret對象 4 [user@demo ~]$ oc secrets add --for=mount serviceaccount/serviceaccount-name \ 5 secret/secret_name #更新pod的服務帳戶,允許引用該secrets。
例如,允許一個運行在指定服務帳戶下的pod掛載一個secrets
創建一個pod,該pod使用環境變量或數據卷作為文件的方式使用該secret,通常使用模板完成。
6.3 使用secret暴露Pod
secrets可以作為數據卷掛載,也可以作為環境變量以便供pod中的容器使用。
例如,要向pod公開一個secrets,首先創建一個secrets並將username和password以k/v形式配置,然後將鍵名分配給pod的YAML文件env定義。
示例:創建名為demo-secret的secrets,它定義用戶名和密碼為username/demo-user。
[user@demo ~]$ oc create secret generic demo-secret \
–from-literal=username=demo-user
要使用前面的secret作為MySQL數據庫pod的數據庫管理員密碼,請定義環境變量,並引用secret名稱和密碼。
1 env: 2 - name: MYSQL_ROOT_PASSWORD 3 valueFrom: 4 secretKeyRef: 5 key: username 6 name: demo-secret
6.4 web端管理secret
從web控制台管理secret:
1. 以授權用戶身份登錄到web控制台。
2. 創建或選擇一個項目來承載secret。
3. 導航到resource——>secrets。
6.5 Secret使用場景
- password和user names
敏感信息(如password和user name)可以存儲在一個secret中,該secret被掛載為容器中的數據卷。數據显示為位於容器的數據卷目錄中的文件中的內容。然後,應用程序(如數據庫)可以使用這些secret對用戶進行身份驗證。
- 傳輸層安全性(TLS)和密鑰對
通過讓集群將簽名證書和密鑰對生成到項目名稱空間中的secret中,可以實現對服務的通信的保護。證書和密鑰對使用PEM格式存儲以類似tls.crt和tls.key的格式存儲在secret的pod中。
七 ConfigMap對象
7.1 ConfigMap概述
ConfigMaps對象類似於secret,但其設計目的是支持處理不包含敏感信息的字符串。ConfigMap對象持有配置數據的鍵值對,這些配置數據可以在pods中使用,或者用於存儲系統組件(如控制器)的配置數據。
ConfigMap對象提供了將配置數據注入容器的機制。ConfigMap存儲精細的粒度信息,比如單個屬性,或者詳細信息,比如整個配置文件或JSON blob。
7.2 CLI創建ConfigMap
可以使用–from-literal選項從CLI創建ConfigMap對象。
示例:創建一個ConfigMap對象,該對象將IP地址172.20.30.40分配給名為serverAddress的ConfigMap密鑰。
1 [user@demo ~]$ oc create configmap special-config \ 2 --from-literal=serverAddress=172.20.30.40 3 [user@demo ~]$ oc get configmaps special-config -o yaml #查看configMap 4 apiVersion: v1 5 data: 6 key1: serverAddress=172.20.30.40 7 kind: ConfigMap 8 metadata: 9 creationTimestamp: 2017-07-10T17:13:31Z 10 name: special-config 11 …… 12 在配置映射的pod定義中填充環境變量APISERVER。 13 env: 14 - name: APISERVER 15 valueFrom: 16 configMapKeyRef: 17 name: special-config 18 key: serverAddress
7.3 web管理ConfigMap
從web控制台管理ConfigMap對象:
1. 以授權用戶身份登錄到web控制台。
2. 創建或選擇一個項目來承載ConfigMap。
3. 導航到資源→配置映射。
八 加密練習
8.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
8.2 本練習準備
[student@workstation ~]$ lab secure-secrets setup
8.3 創建項目
1 [student@workstation ~]$ oc login -u developer -p redhat 2 [student@workstation ~]$ cd /home/student/DO280/labs/secure-secrets/ 3 [student@workstation secure-secrets]$ less mysql-ephemeral.yml #導入本環境MySQL模板
模板解讀:
該mysql-ephemeral.yml模板文件,包含openshift項目中的mysql臨時模板,pod所需的其他環境變量由模板參數初始化,並具有默認值。
但沒有secret定義,後續操作將手動創建模板所需的secret。
根據模板的要求,創建一個包含MySQL容器image使用的憑證的secret,將這個secret命名為mysql。
- 應用程序訪問的數據庫用戶名由database-user定義。
- 數據庫用戶的密碼由database-password定義。
- 數據庫管理員密碼由database-root-password定義
8.4 創建新secret
1 [student@workstation secure-secrets]$ oc create secret generic mysql \ 2 --from-literal='database-user'='mysql' \ 3 --from-literal='database-password'='redhat' \ 4 --from-literal='database-root-password'='do280-admin' 5 [student@workstation secure-secrets]$ oc get secret mysql -o yaml #確認secret
8.5 創建應用
1 [student@workstation secure-secrets]$ oc new-app --file=mysql-ephemeral.yml 2 [student@workstation secure-secrets]$ oc get pods #確認應用 3 NAME READY STATUS RESTARTS AGE 4 mysql-1-j4fnz 1/1 Running 0 1m
8.6 端口轉發
1 [student@workstation secure-secrets]$ cd 2 [student@workstation ~]$ oc port-forward mysql-1-j4fnz 3306:3306
提示:驗證完成之前forward不要關閉。
8.7 確認驗證
1 [student@workstation ~]$ mysql -uroot -pdo280-admin -h127.0.0.1 #新開終端測試MySQL
九 管理security policy
9.1 OCP authorization授權
OCP定義了用戶可以執行的兩組主要操作:
與項目相關的操作(也稱為本地策略):project-related
與管理相關的操作(也稱為集群策略):administration-related
由於這兩種策略都有大量可用的操作,所以將一些操作分組並定義為角色。
為管理本地政策,OCP提供以下角色:
除了能夠創建新應用程序之外,admin角色還允許用戶訪問項目資源,比如配額和限制範圍。
edit角色允許用戶在項目中充當開發人員,但要在項目管理員配置的約束下工作。
9.2 相關命令
1 向集群用戶添加角色 2 $ oc adm policy add-cluster-role-to-user cluster-role username 3 示例:將普通用戶更改為集群管理員。 4 $ oc adm policy add-cluster-role-to-user cluster-role username 5 從用戶中刪除集群角色 6 $ oc adm policy remove-cluster-role-from-user cluster-role username 7 示例:將集群管理員更改為普通用戶。 8 $ oc adm policy remove-cluster-role-from-user cluster-admin username 9 將指定的用戶綁定到項目中的角色 10 $ oc adm policy add-role-to-user role-name username -n project 11 示例:在WordPress項目中dev用戶綁定basic-user角色。 12 $ oc adm policy add-role-to-user basic-user dev -n wordpress
9.3 權限及規則
OpenShift將一組規則集合成一個角色,規則由謂詞和資源定義。如create user是OpenShift中的一條規則,它是一個名為cluster-admin的角色的所擁有的權限的一部分。
1 $ oc adm policy who-can delete user
9.4 user類型
與OCP的交互基於用戶,OCP的user對象表示可以通過向該用戶或用戶組添加角色來從而實現相應權限的授予。
Regular users:通常以這種用戶類型與OCP交互,常規用戶用User對象表。例如,user1,user2。
System users:通常在安裝OCP中定義基礎設施時自動創建的,主要目的是使基礎設施能夠安全地與API交互。包括集群管理員(可以訪問所有內容)、每個節點的用戶、路由器和內部倉庫使用的用戶,以及各種其他用戶。還存在一個匿名系統用戶,默認情況下,該用戶用於未經身份驗證的請求。system user主要包括:system:admin、system:openshift-registry和system:node:node1.example.com。
Service accounts:這些是與項目關聯的特殊系統用戶。有些是在第一次創建項目時自動創建的,項目管理員可以創建多個,以便定義對每個項目內容的訪問。Service accounts由ServiceAccount對象表示。Service accounts主要包括:system:serviceaccount:default:deployer和system:serviceaccount:foo:builder。
每個用戶在訪問OpenShift容器平台之前必須進行身份驗證。沒有身份驗證或身份驗證無效的API請求將使用匿名系統用戶身份驗證來請求服務。身份驗證成功后,策略確定用戶被授權做什麼。
9.5 安全上下文約束(SCCS)
OpenShift提供了一種名為安全上下文約束的安全機制,它限制對資源的訪問,但不限制OpenShift中的操作。
SCC限制從OpenShift中運行的pod到主機環境的訪問:
- 運行特權容器
- 請求容器的額外功能
- 使用主機目錄作為卷
- 更改容器的SELinux上下文
- 更改用戶ID
社區開發的一些容器可能需要放鬆安全上下文約束,因為它們可能需要訪問默認禁止的資源,例如文件系統、套接字或訪問SELinux上下文。
OpenShift定義的安全上下文約束(SCCs)可以使用以下命令作為集群管理員列出。
$ oc get scc
SCC通常有以下7中SCCS:
- anyuid
- hostaccess
- hostmount-anyuid
- nonroot
- privileged
- restricted(默認)
$ oc describe scc anyuid #查看某一種SCC詳情
OpenShift創建的所有容器都使用restricted類型的SCC,它提供了對OpenShift外部資源的有限訪問。
對於anyuid安全上下文,run as user策略被定義為RunAsAny,表示pod可以作為容器中可用的任何用戶ID運行。這允許需要特定用戶使用特定用戶ID運行命令的容器。
要將容器更改為使用不同的SCC運行,需要創建綁定到pod的服務帳戶。
$ oc create serviceaccount service-account-name #首先創建服務賬戶
$ oc adm policy add-scc-to-user SCC -z service-account #將服務帳戶與SCC關聯
要確定哪個帳戶可以創建需要更高安全性要求的pod,可以使用scc-subject-review子命令。
$ oc export pod pod-name > output.yaml
$ oc adm policy scc-subject-review -f output.yaml
9.6 OpenShift與SELinux
OpenShift要求在每個主機上啟用SELinux,以便使用強制訪問控制提供對資源的安全訪問。同樣,由OpenShift管理的Docker容器需要管理SELinux上下文,以避免兼容性問題。
為了最小化在不支持SELinux的情況下運行容器的風險,可以創建SELinux上下文策略。
為了更新SELinux上下文,可以使用現有的SCC作為起點生成一個新的SCC。
$ oc export scc restricted > custom_selinux.yml #導出默認的SCC
編輯導出的YAML文件以更改SCC名稱和SELinux上下文。
$ oc create -f yaml_file #使用修改后的ymal重新創建一個SCC
9.7 特權容器
有些容器可能需要訪問主機的運行時環境。S2I構建器容器需要訪問宿主docker守護進程來構建和運行容器。
例如,S2I構建器容器是一類特權容器,它要求訪問超出其自身容器的限制。這些容器可能會帶來安全風險,因為它們可以使用OpenShift節點上的任何資源。通過創建具有特權訪問權的服務帳戶,可以使用SCCs啟用特權容器的訪問。
十 資源訪問控制綜合實驗
10.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
10.2 本練習準備
1 [student@workstation ~]$ lab secure-review setup
10.3 創建用戶
1 [root@master ~]# htpasswd /etc/origin/master/htpasswd user-review 2 New password: 【redhat】 3 Re-type new password: 【redhat】
10.4 修改策略
1 [student@workstation ~]$ oc login -u admin -p redhat 2 [student@workstation ~]$ oc adm policy remove-cluster-role-from-group \ 3 self-provisioner system:authenticated system:authenticated:oauth 4 禁用所有常規用戶的項目創建功能
10.5 確認驗證
1 [student@workstation ~]$ oc login -u user-review -p redhat 2 [student@workstation ~]$ oc new-project test #普通用戶無法創建項目 3 Error from server (Forbidden): You may not request a new project via this API.
10.6 創建項目
1 [student@workstation ~]$ oc login -u admin -p redhat 2 [student@workstation ~]$ oc new-project secure-review #使用管理員創建項目
10.7 授權用戶
1 [student@workstation ~]$ oc project secure-review 2 Already on project "secure-review" on server "https://master.lab.example.com:443". 3 [student@workstation ~]$ oc policy add-role-to-user edit user-review #將edit的role和user-review進行關聯
10.8 測試訪問
1 [student@workstation ~]$ oc login -u user-review -p redhat 2 [student@workstation ~]$ oc project secure-review #測試訪問 3 Already on project "secure-review" on server "https://master.lab.example.com:443".
10.9 檢查模板
1 [student@workstation ~]$ cd /home/student/DO280/labs/secure-review/ 2 [student@workstation secure-review]$ less mysql-ephemeral.yml
模板解讀:
該mysql-ephemeral.yml模板文件,包含openshift項目中的mysql臨時模板,pod所需的其他環境變量由模板參數初始化,並具有默認值。
但沒有secret定義,後續操作將手動創建模板所需的secret。
根據模板的要求,創建一個包含MySQL容器image使用的憑證的secret,將這個secret命名為mysql。
- 應用程序訪問的數據庫用戶名由database-user定義。
- 數據庫用戶的密碼由database-password定義。
- 數據庫管理員密碼由database-root-password定義
使用user-review developer用戶創建一個名為mysql的secret。這個secret應該存儲用戶名mysql、密碼redhat和數據庫管理員密碼do280-admin。
數據庫用戶名由database-user定義。此用戶的密碼由mysql secret密鑰定義。
數據庫管理員密碼由database-root-password定義。
10.10 創建secret
1 [student@workstation secure-review]$ oc create secret generic mysql \ 2 --from-literal='database-user'='mysql' \ 3 --from-literal='database-password'='redhat' \ 4 --from-literal='database-root-password'='do280-admin' 5 [student@workstation secure-review]$ oc get secret mysql -o yaml #確認驗證secret
10.11 部署應用
1 [student@workstation secure-review]$ oc new-app --file=mysql-ephemeral.yml 2 [student@workstation secure-review]$ oc get pods 3 NAME READY STATUS RESTARTS AGE 4 mysql-1-2lr7t 1/1 Running 0 31s
10.12 轉發端口
1 [student@workstation ~]$ oc port-forward mysql-1-2lr7t 3306:3306
10.13 測試訪問
1 [student@workstation ~]$ mysql -umysql -predhat -h127.0.0.1
10.14 部署phpmyadmin應用
使用內部倉庫registry.lab.example.com的image部署phpmyadmin:4.7容器。phpmyadmin:4.7容器需要名為PMA_HOST的環境變量來提供MySQL服務器的IP地址。
使用模板創建一個基於FQND的MySQL pod的service。
為使用模板創建的MySQL服務器pod使用服務FQDN,該模板是mysql.secure-review.svc.cluster.local。
1 [student@workstation ~]$ oc new-app --name=phpmyadmin \ 2 --docker-image=registry.lab.example.com/phpmyadmin/phpmyadmin:4.7 \ 3 -e PMA_HOST=mysql.secure-review.svc.cluster.local
結論:該命令會發出警告,提示需要root特權。默認情況下,OpenShift不支持使用操作系統的root用戶運行容器。
10.15 查看pod
1 [student@workstation ~]$ oc get pods 2 NAME READY STATUS RESTARTS AGE 3 mysql-1-2lr7t 1/1 Running 0 8m 4 phpmyadmin-1-v7tl7 0/1 Error 2 1m 5 因為沒有root權限,因此部署失敗,需要提權。
10.16 授予權限
1 [student@workstation ~]$ oc login -u admin -p redhat #使用管理員登錄 2 [student@workstation ~]$ oc create serviceaccount phpmyadmin-account #首先創建服務賬戶 3 [student@workstation ~]$ oc adm policy add-scc-to-user anyuid -z phpmyadmin-account 4 scc "anyuid" added to: ["system:serviceaccount:secure-review:phpmyadmin-account"] #將服務帳戶與anyuid安全上下文關聯
10.17 更新應用
1 [student@workstation ~]$ oc patch dc phpmyadmin --patch='{"spec":{"template":{"spec":{"serviceAccountName": "phpmyadmin-account"}}}}'
#更新負責管理phpmyadmin的dc資源,任何開發人員用戶都可以執行此操作。
本環境中,相關操作命令可以從/home/student/DO280/labs/secure-review文件夾中的patch-dc.sh腳本運行或複製。
10.18 確認驗證
1 [student@workstation ~]$ oc login -u user-review -p redhat 2 [student@workstation ~]$ oc get pods #確認pod是否正常 3 NAME READY STATUS RESTARTS AGE 4 mysql-1-2lr7t 1/1 Running 0 13m 5 phpmyadmin-2-bdjvq 1/1 Running 0 1m
10.19 暴露服務
1 [student@workstation ~]$ oc expose svc phpmyadmin --hostname=phpmyadmin.apps.lab.example.com
10.20 訪問測試
1 [student@workstation ~]$ curl -s http://phpmyadmin.apps.lab.example.com
10.21 確認及刪除
1 [student@workstation ~]$ lab secure-review grade #環境腳本判斷 2 [student@workstation ~]$ oc login -u admin -p redhat 3 [student@workstation ~]$ oc adm policy add-cluster-role-to-group \ 4 self-provisioner system:authenticated system:authenticated:oauth 5 [student@workstation ~]$ oc delete project secure-review 6 [student@workstation ~]$ ssh root@master htpasswd -D \ 7 /etc/origin/master/htpasswd user-review #刪除用戶 8 [student@workstation ~]$ oc delete user user-review #刪除項目
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!