環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年7月19日法廣報導
在馬來西亞,臨海的登嘉樓州(Terengganu)頒布了一項新法律,禁止販賣海龜蛋。當地出名的原因之一,也是因為這裡可以品嘗得到瀕臨滅絕的珍稀動物海龜的蛋。儘管現在可以看到思維開始轉變,但動物保護工作依然複雜。
就在海龜保護機構九年來致力於搶救小海龜的同時,20公里外的Chukai市場上,海龜蛋被混在水果中,一起銷售。當地一名女商販指出,儘管這一做法沒有得到大家一致認同,但這種生意依然火紅。這名商販表示,海龜蛋的氣味在近距離真的很難聞,但它有益於防範AVC腦血管意外(中風),有人就是因此而購買,價格為2歐元三個。
登嘉樓州的新法對保護瀕臨滅絕物種是一個進步,但當局尚未公布對違法分子如何量刑。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年7月21日公視報導
荷蘭一間生化公司開發出以植物原料製造的塑膠瓶,使用完不僅可以回收,它還能在一年內自行分解。
荷蘭生化公司技術總監古魯特表示:「而且因為從隔離膜的角度來看,PEF(生質聚酯塑膠)性能確實很好,因為紙瓶的優勢來自於紙質製造,只需要一層薄薄的PEF即可實現阻隔(液體)的性能,能好好將內容物妥善保存一段時間。」
這種植物塑膠,是由玉米、小麥,和甜菜根作成,可以用來盛裝包括氣泡型的飲料,能大幅減少塑膠污染,跟市場對化石燃料的依賴。經過將瓶子放入淡水、鹽水、泥土跟沉澱物的實驗證明,這種塑膠經過堆肥處理後,一年內就可以完全分解,就算放在戶外,也只要幾年時間就能分解。
生化公司認為這些瓶子,可以回收再利用,因此爭取到了美國可口可樂公司,和丹麥啤酒製造商「嘉士伯」的支持,持續開發。由於植物塑膠的製作成本,生化公司了解一開始無法在價格上占有市場優勢,因此預計先每年生產5000公噸,預計將在2023年前,會與飲料公司合作,讓產品上架。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
折騰了好長時間才寫這篇文章,順序消費,看上去挺好理解的,就是消費的時候按照隊列中的順序一個一個消費;而併發消費,則是消費者同時從隊列中取消息,同時消費,沒有先後順序。RocketMQ也有這兩種方式的實現,但是在實踐的過程中,就是不能順序消費,好不容易能夠實現順序消費了,發現採用併發消費的方式,消費的結果也是順序的,頓時就蒙圈了,到底怎麼回事?哪裡出了問題?百思不得其解。
經過多次調試,查看資料,debug跟蹤程序,最後終於搞清楚了,但是又不知道怎麼去寫這篇文章,是按部就班的講原理,講如何配置到最後實現,還是按照我的調試過程去寫呢?我覺得還是按照我的調試過程去寫這篇文章吧,因為我的調成過程應該和大多數人的理解思路是一致的,大家也更容易重視。
我們先來回顧一下前面搭建的RocketMQ的環境,這對於我們理解RocketMQ的順序消費是至關重要的。我們的RocketMQ環境是一個兩主兩從的異步集群,其中有兩個broker,broker-a和broker-b,另外,我們創建了兩個Topic,“cluster-topic”,這個Topic我們在創建的時候指定的是集群,也就是說我們發送消息的時候,如果Topic指定為“cluster-topic”,那麼這個消息應該在broker-a和broker-b之間負載;另外創建的一個Topic是“broker-a-topic”,這個Topic我們在創建的時候指定的是broker-a,當我們發送這個Topic的消息時,這個消息只會在broker-a當中,不會出現在broker-b中。
和大家羅嗦了這麼多,大家只要記住,我們的環境中有兩個broker,“broker-a”和“broker-b”,有兩個Topic,“cluster-topic”和“broker-a-topic”就可以了。
我們發送的消息,如果指定Topic為“cluster-topic”,那麼這種消息將在broker-a和broker-b直接負載,這種情況能夠做到順序消費嗎?我們試驗一下,
消費端的代碼如下:
@Bean(name = "pushConsumerOrderly", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer pushConsumerOrderly() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("pushConsumerOrderly");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("cluster-topic","*");
consumer.registerMessageListener((MessageListenerOrderly) (msgs, context) -> {
Random random = new Random();
try {
Thread.sleep(random.nextInt(5) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeOrderlyStatus.SUCCESS;
});
return consumer;
}
生產端我們採用同步發送的方式,代碼如下:
@Test
public void producerTest() throws Exception {
for (int i = 0;i<5;i++) {
Message message = new Message();
message.setTopic("cluster-topic");
message.setKeys("key-"+i);
message.setBody(("this is simpleMQ,my NO is "+i+"---"+new Date()).getBytes());
SendResult sendResult = defaultMQProducer.send(message);
System.out.println("i=" + i);
System.out.println("BrokerName:" + sendResult.getMessageQueue().getBrokerName());
}
}
和前面一樣,我們發送5個消息,並且打印出i的值和broker的名稱,發送消息的順序是0,1,2,3,4,發送完成后,我們觀察一下消費端的日誌,如果順序也是0,1,2,3,4,那麼就是順序消費。我們運行一下,看看結果吧。
生產者的發送日誌如下:
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-b
發送5個消息,其中4個在broker-a,1個在broker-b。再來看看消費端的日誌:
this is simpleMQ,my NO is 3---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 13:48:57 CST 2020
this is simpleMQ,my NO is 0---Wed Jun 10 13:48:56 CST 2020
順序是亂的?怎麼回事?說明消費者在並不是一個消費完再去消費另一個,而是拉取了一個消息以後,並沒有消費完就去拉取下一個消息了,那這不是併發消費嗎?可是我們程序中設置的是順序消費啊。這裏我們就開始懷疑是broker的問題,難道是因為兩個broker引起的?順序消費只能在一個broker里才能實現嗎?那我們使用broker-a-topic這個試一下吧。
我們把上面的程序稍作修改,只把訂閱的Topic和發送消息時消息的Topic改為broker-a-topic即可。代碼在這裏就不給大家重複寫了,重啟一下程序,發送消息看看日誌吧。
生產者端的日誌如下:
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
我們看到5個消息都發送到了broker-a中,再來看看消費端的日誌,
this is simpleMQ,my NO is 0---Wed Jun 10 14:00:28 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:00:29 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 14:00:29 CST 2020
消費的順序還是亂的,這是怎麼回事?消息都在broker-a中了,為什麼消費時順序還是亂的?程序有問題嗎?review了好幾遍沒有發現問題。
問題卡在這個地方,卡了好長時間,最後在官網的示例中發現,它在發送消息時,使用了一個MessageQueueSelector,我們也實現一下試試吧,改造一下發送端的程序,如下:
SendResult sendResult = defaultMQProducer.send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
return mqs.get(0);
}
},i);
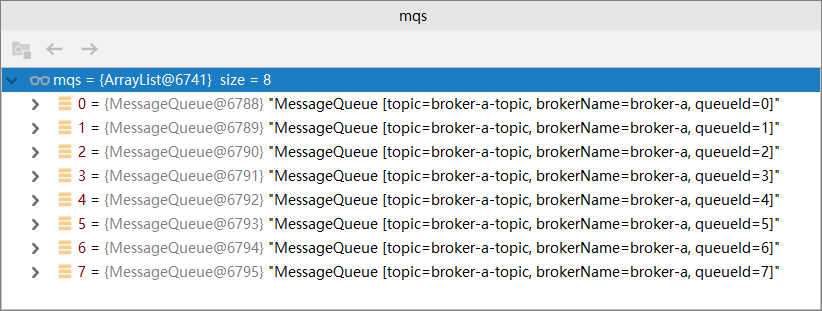
在發送的方法中,我們實現了MessageQueueSelector接口中的select方法,這個方法有3個參數,mq的集合,發送的消息msg,和我們傳入的參數,這個參數就是最後的那個變量i,大家不要漏了。這個select方法需要返回的是MessageQueue,也就是mqs變量中的一個,那麼mqs中有多少個MessageQueue呢?我們猜測是2個,因為我們只有broker-a和broker-b,到底是不是呢?我們打斷點看一下,
MessageQueue有8個,並且brokerName都是broker-a,原來Broker和MessageQueue不是相同的概念,之前我們都理解錯了。我們可以用下面的方式理解,
集群 ——–》 Broker ————》 MessageQueue
一個RocketMQ集群里可以有多個Broker,一個Broker里可以有多個MessageQueue,默認是8個。
那現在對於順序消費,就有了正確的理解了,順序消費是只在一個MessageQueue內,順序消費,我們驗證一下吧,先看看發送端的日誌,
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
5個消息都發送到了broker-a中,通過前面的改造程序,這5個消息應該都是在MessageQueue-0當中,再來看看消費端的日誌,
this is simpleMQ,my NO is 0---Wed Jun 10 14:21:40 CST 2020
this is simpleMQ,my NO is 1---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:21:41 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:21:41 CST 2020
這回是順序消費了,每一個消費者都是等前面的消息消費完以後,才去消費下一個消息,這就完全解釋的通了,我們再把消費端改成併發消費看看,如下:
@Bean(name = "pushConsumerOrderly", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer pushConsumerOrderly() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("pushConsumerOrderly");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("broker-a-topic","*");
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
Random random = new Random();
try {
Thread.sleep(random.nextInt(5) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
return consumer;
}
這回使用的是併發消費,我們再看看結果,
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-a
i=3
BrokerName:broker-a
i=4
BrokerName:broker-a
5個消息都在broker-a中,並且知道它們都在同一個MessageQueue中,再看看消費端,
this is simpleMQ,my NO is 1---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 0---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 3---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 2---Wed Jun 10 14:28:00 CST 2020
this is simpleMQ,my NO is 4---Wed Jun 10 14:28:00 CST 2020
是亂序的,說明消費者是併發的消費這些消息的,即使它們在同一個MessageQueue中。
好了,到這裏終於把順序消費搞明白了,其中的關鍵就是Broker中還有多個MessageQueue,同一個MessageQueue中的消息才能順序消費。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化

本文收錄在個人博客:www.chengxy-nds.top,技術資源共享,一起進步
最近公司貌似融到資了!開始發了瘋似的找渠道推廣,現在終於明白為啥前一段大肆的招人了,原來是在下一盤大棋,對員工總的來看是個好事,或許是時候該跟boss提一提漲工資的話題了。
不過,漲工資還沒下文,隨之而來的卻是一車一車的需求,每天都有新渠道接入,而且每個渠道都要提供個性化支持,開發量陡增。最近都沒什麼時間更文,準點下班都成奢望了!
由於推廣渠道的激增,而每一個下單來源在下單時都做特殊的邏輯處理,可能每两天就會加一個來源,已經把之前的下單邏輯改的面目全。出於長遠的考慮,我決定對現有的邏輯進行重構,畢竟長痛不如短痛。
我們看下邊的偽代碼,大致就是重構前下單邏輯的代碼,由於來源比較少,簡單的做if-else邏輯判斷足以滿足需求。
現在每種訂單來源的處理邏輯都有幾百行代碼,看着已經比較臃腫,可我愣是遲遲沒動手重構,一方面業務方總像催命鬼一樣的讓你趕工期,想快速實現需求,這樣寫是最快;另一方面是不敢動,面對古董級代碼,還是想求個安穩。
但這次來源一下子增加幾十個,再用這種方式做已經無法維護了,想象一下那種臃腫的if-else代碼,別說開發想想都頭大!
public class OrderServiceImpl implements IOrderService {
@Override
public String handle(OrderDTO dto) {
String type = dto.getType();
if ("1".equals(type)) {
return "處理普通訂單";
} else if ("2".equals(type)) {
return "處理團購訂單";
} else if ("3".equals(type)) {
return "處理促銷訂單";
}
return null;
}
}
思來想去基於當前業務場景重構,還是用策略模式比較合適,它是oop中比較著名的設計模式之一,對方法行為的抽象。
策略模式定義了一個擁有共同行為的算法族,每個算法都被封裝起來,可以互相替換,獨立於客戶端而變化。
if-else 或者 switch-case 來選擇具體子類時。這個是用策略模式修改後代碼:
@Component
@OrderHandlerType(16)
public class DispatchModeProcessor extends AbstractHandler{
@Autowired
private OrderStencilledService orderStencilledService;
@Override
public void handle(OrderBO orderBO) {
/**
* 訂單完結廣播通知(1 - 支付完成)
*/
orderStencilledService.dispatchModeFanout(orderBO);
/**
* SCMS 出庫單
*/
orderStencilledService.createScmsDeliveryOrder(orderBO.getPayOrderInfoBO().getLocalOrderNo());
}
}
每個訂單來源都有自己單獨的邏輯實現類,而每次需要添加訂單來源,直接新建實現類,修改@OrderHandlerType(16)的數值即可,再也不用去翻又臭又長的if-lese。
不僅如此在分配任務時,每個人負責開發幾種訂單來源邏輯,都可以做到互不干擾,而且很大程度上減少了合併代碼的衝突。
定義一個標識訂單來源的註解@OrderHandlerType
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface OrderHandlerType {
int value() default 0;
}
向上抽象出來一個具體的業務處理器
public abstract class AbstractHandler {
abstract public void handle(OrderBO orderBO);
}
handler 入口@Component
@SuppressWarnings({"unused","rawtypes"})
public class HandlerProcessor implements BeanFactoryPostProcessor {
private String basePackage = "com.ecej.order.pipeline.processor";
public static final Logger log = LoggerFactory.getLogger(HandlerProcessor.class);
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
Map<Integer,Class> map = new HashMap<Integer,Class>();
ClassScaner.scan(basePackage, OrderHandlerType.class).forEach(x ->{
int type = x.getAnnotation(OrderHandlerType.class).value();
map.put(type,x);
});
beanFactory.registerSingleton(OrderHandlerType.class.getName(), map);
log.info("處理器初始化{}", JSONObject.toJSONString(beanFactory.getBean(OrderHandlerType.class.getName())));
}
}
public class ClassScaner {
private ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
private final List<TypeFilter> includeFilters = new ArrayList<TypeFilter>();
private final List<TypeFilter> excludeFilters = new ArrayList<TypeFilter>();
private MetadataReaderFactory metadataReaderFactory = new CachingMetadataReaderFactory(resourcePatternResolver);
/**
* 添加包含的Fiter
* @param includeFilter
*/
public void addIncludeFilter(TypeFilter includeFilter) {
this.includeFilters.add(includeFilter);
}
/**
* 添加排除的Fiter
* @param includeFilter
*/
public void addExcludeFilter(TypeFilter excludeFilter) {
this.excludeFilters.add(excludeFilter);
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackage 包名
* @param targetTypes 需要指定的目標類型,可以是pojo,可以是註解
* @return Set<Class<?>>
*/
public static Set<Class<?>> scan(String basePackage,
Class<?>... targetTypes) {
ClassScaner cs = new ClassScaner();
for (Class<?> targetType : targetTypes){
if(TypeUtils.isAssignable(Annotation.class, targetType)){
cs.addIncludeFilter(new AnnotationTypeFilter((Class<? extends Annotation>) targetType));
}else{
cs.addIncludeFilter(new AssignableTypeFilter(targetType));
}
}
return cs.doScan(basePackage);
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackages 包名,多個
* @param targetTypes 需要指定的目標類型,可以是pojo,可以是註解
* @return Set<Class<?>>
*/
public static Set<Class<?>> scan(String[] basePackages,
Class<?>... targetTypes) {
ClassScaner cs = new ClassScaner();
for (Class<?> targetType : targetTypes){
if(TypeUtils.isAssignable(Annotation.class, targetType)){
cs.addIncludeFilter(new AnnotationTypeFilter((Class<? extends Annotation>) targetType));
}else{
cs.addIncludeFilter(new AssignableTypeFilter(targetType));
}
}
Set<Class<?>> classes = new HashSet<Class<?>>();
for (String s : basePackages){
classes.addAll(cs.doScan(s));
}
return classes;
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackages 包名
* @return Set<Class<?>>
*/
public Set<Class<?>> doScan(String [] basePackages) {
Set<Class<?>> classes = new HashSet<Class<?>>();
for (String basePackage :basePackages) {
classes.addAll(doScan(basePackage));
}
return classes;
}
/**
* 掃描指定的包,獲取包下所有的Class
* @param basePackages 包名
* @return Set<Class<?>>
*/
public Set<Class<?>> doScan(String basePackage) {
Set<Class<?>> classes = new HashSet<Class<?>>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX
+ ClassUtils.convertClassNameToResourcePath(
SystemPropertyUtils.resolvePlaceholders(basePackage))+"/**/*.class";
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
for (int i = 0; i < resources.length; i++) {
Resource resource = resources[i];
if (resource.isReadable()) {
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
if ((includeFilters.size() == 0 && excludeFilters.size() == 0)|| matches(metadataReader)) {
try {
classes.add(Class.forName(metadataReader.getClassMetadata().getClassName()));
} catch (ClassNotFoundException ignore) {}
}
}
}
} catch (IOException ex) {
throw new RuntimeException("I/O failure during classpath scanning", ex);
}
return classes;
}
/**
* 處理 excludeFilters和includeFilters
* @param metadataReader
* @return boolean
* @throws IOException
*/
private boolean matches(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return true;
}
}
return false;
}
}
@Component
public class HandlerContext {
@Autowired
private ApplicationContext beanFactory;
public AbstractHandler getInstance(Integer type){
Map<Integer,Class> map = (Map<Integer, Class>) beanFactory.getBean(OrderHandlerType.class.getName());
return (AbstractHandler)beanFactory.getBean(map.get(type));
}
}
我這裡是在接受到MQ消息時,處理多個訂單來源業務,不同訂單來源路由到不同的業務處理類中。
@Component
@RabbitListener(queues = "OrderPipelineQueue")
public class PipelineSubscribe{
private final Logger LOGGER = LoggerFactory.getLogger(PipelineSubscribe.class);
@Autowired
private HandlerContext HandlerContext;
@Autowired
private OrderValidateService orderValidateService;
@RabbitHandler
public void subscribeMessage(MessageBean bean){
OrderBO orderBO = JSONObject.parseObject(bean.getOrderBO(), OrderBO.class);
if(null != orderBO &&CollectionUtils.isNotEmpty(bean.getType()))
{
for(int value:bean.getType())
{
AbstractHandler handler = HandlerContext.getInstance(value);
handler.handle(orderBO);
}
}
}
}
接收實體 MessageBean 類代碼
public class MessageBean implements Serializable {
private static final long serialVersionUID = 5454831432308782668L;
private String cachKey;
private List<Integer> type;
private String orderBO;
public MessageBean(List<Integer> type, String orderBO) {
this.type = type;
this.orderBO = orderBO;
}
}
以上設計模式方式看着略顯複雜,很些小夥伴提出質疑:“你為了個if-else,弄的如此的麻煩,又是自定義註解,又弄這麼多類不麻煩嗎?” 還有一些小夥伴糾結於性能問題,策略模式的性能可能確實不如if-else。
但我覺得吧增加一點複雜度、犧牲一丟丟性能,換代碼的整潔和可維護性還是值得的。不過,一個人一個想法,怎麼選還是看具體業務場景吧!
IOC容器和依賴注入的方式來解決。以下是訂單來源策略類的一部分,不得不說策略類確實比較多。
凡事都有他的兩面性,if-else多層嵌套和也都有其各自的優缺點:
if-else的優點就是簡單,想快速迭代功能,邏輯嵌套少且不會持續增加,if-else更好些,缺點也是顯而易見,代碼臃腫繁瑣不便於維護。
策略模式 將各個場景的邏輯剝離出來維護,同一抽象類有多個子類,需要使用if-else 或者 switch-case 來選擇具體子類時,建議選策略模式,他的缺點就是會產生比較多的策略類文件。
兩種實現方式各有利弊,如何選擇還是要依據具體業務場景,還是那句話設計模式不是為了用而用,一定要用在最合適的位置。
平常和粉絲私下聊天,好多人對於學設計模式的感受:設計模式背了一大堆,可平常開發還不是成天寫if-else業務邏輯,根本就用不到。
學設計模式也不是用不到,只是有時候沒有合適它的場景而已,像我們今天說的這種業務場景,用設計模式就可以完美的解決嘛。
學了N多技術可工作用不到是一種很常見的事情,一個穩定的項目使用一種技術會有諸多考量的,新技術會不會提升系統複雜度?它有哪些性能瓶頸?這些都必須考慮到,畢竟項目穩定才是最重要,誰也不敢輕易冒險嘗試。
而我們學習技術可不僅為了眼下項目中是否會用到,是要做一個技術積累,做長遠打算,人往高處走,沒點能力可不行。
原創不易,燃燒秀髮輸出內容,希望你能有一丟丟收穫!
整理了幾百本各類技術电子書,送給小夥伴們。關公眾號回復【666】自行領取。和一些小夥伴們建了一個技術交流群,一起探討技術、分享技術資料,旨在共同學習進步,如果感興趣就掃碼加入我們吧!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!

相信絕大部分開發者都接觸過用戶註冊的流程,通常情況下大概的流程如下所示:
偽代碼如下:
public async Task<IActionResult> Reg([FromBody] User user)
{
_logger.LogInformation("持久化數據開始");
await Task.Delay(50);
_logger.LogInformation("持久化結束");
_logger.LogInformation("發送短信開始");
await Task.Delay(100);
_logger.LogInformation("發送短信結束");
_logger.LogInformation("操作日誌開始");
await _logRepository.Insert(new Log { Txt = "註冊日誌" });
_logger.LogInformation("操作日誌結束");
return Ok("註冊成功");
}
在以上的代碼中,我使用Task.Delay方法阻塞主線程,用以模擬實際場景中的執行耗時。以上流程應該是包含了絕大部分註冊流程所需要的操作。對於任何開發者來講,以上業務流程沒任何難度,無非是順序的執行各個流程的代碼即可。
稍微有點開發經驗的應該會將以上的流程進行拆分,但有些人可能就要問了,為什麼要拆分呢?拆分之後的代碼應該怎麼寫呢?下面我們就來簡單聊下如此場景的正確打開方式。
首先,註冊成功的依據應該是是否成功的將用戶信息持久化(至於是先持久化到數據庫,異或是先寫到redis不在本篇文章討論的範疇),至於發送註冊短信(郵件)以及寫日誌的操作應該不能成為影響註冊是否成功的因素,而發送短信/郵件等相關操作通常情況下也是比較耗時的,所以在對此接口做性能優化時,可優先考慮將短信/郵件以及寫日誌等相關操作與主流程(持久化數據)拆分,使其不阻塞主流程的執行,從而達到提高響應速度的目的。
知道了為什麼要拆,但具體如何拆分呢?怎樣才能用最少的改動,達到所需的目的呢?
條條大路通羅馬,所以要達成我們的目的也是有很多方案的,具體選擇哪種方案需要根據具體的業務場景,業務體量等多種因素綜合考慮,下面我將一一介紹分析相關方案。
在正式介紹可用方案前,筆者想先介紹一種很多新手容易錯誤使用的一種方案(因為筆者就曾經天真的使用過這種錯誤的方案)。
提到異步,絕大部分.net開發者應該第一想到的就是Task,async,await等,的確,async,await的語法糖簡化了.net開發者異步編程的門檻,減少了很多代碼量。通常一個返回Task類型的方法,在被調用時,會在方法的前面加上await,表示需要等待此方法的執行結果,再繼續執行後面的代碼。但如果不加await時,則不會等待方法的執行結果,進而也不會阻塞主線程。所以,有些人可能就會將發送短信/郵件以及寫日誌的操作如下方式進行改造。
public async Task<IActionResult> Reg1([FromBody] User user)
{
_logger.LogInformation("持久化數據開始");
await Task.Delay(50);
_logger.LogInformation("持久化結束");
_ = Task.Run(async () =>
{
_logger.LogInformation("發送短信開始");
await Task.Delay(100);
_logger.LogInformation("發送短信結束");
_logger.LogInformation("操作日誌開始");
await _logRepository.Insert(new Log { Txt = "註冊日誌" });
_logger.LogInformation("操作日誌結束");
});
return Ok("註冊成功");
}
然後使用jmeter分別壓測改造前和改造后的接口,結果如下:
有沒有被驚訝到?就這樣一個簡單的改造,吞吐量就提高了三四倍。既然已經提高了三四倍,那為什麼說這是一種錯誤的改造方法嗎?各位看官且往下看。
熟悉.netcore的大佬,應該都知道.netcore的依賴注入的生命周期吧。通常情況下,注入的生命周期包括:Singleton,Scope,Transient。
在以上的流程中,假如寫操作日誌的實例的生命周期是Scope,當在Task中調用Controller獲取到的實例的方法時,因為Task.Run並沒有阻塞主線程,當調用Action return后,當前請求的scope注入的對象會被回收,如果對象被回收之後,Task.Run還未執行完,則會報System.ObjectDisposedException: Cannot access a disposed object. 異常。意思是,不能訪問一個已disposed的對象。正確的做法是使用IServiceScopeFactory創建一個新的作用域,在新的作用域中獲取獲取日誌倉儲服務的實例。這樣就可以避免System.ObjectDisposedException異常了。
改造后的示例代碼如下:
public async Task<IActionResult> Reg1([FromBody] User user)
{
_logger.LogInformation("持久化數據開始");
await Task.Delay(50);
_logger.LogInformation("持久化結束");
_ = Task.Run(async () =>
{
using (var scope = _scopeFactory.CreateScope())
{
var sp = scope.ServiceProvider;
var logRepository = sp.GetService<ILogRepository>();
_logger.LogInformation("發送短信開始");
await Task.Delay(100);
_logger.LogInformation("發送短信結束");
_logger.LogInformation("操作日誌開始");
await logRepository.Insert(new Log { Txt = "註冊日誌" });
_logger.LogInformation("操作日誌結束");
}
});
return Ok("註冊成功");
}
雖然得到了正解,但上述的代碼着實有點多,如果一個項目有多個相似的業務場景,就要考慮對CreateScope相關的操作進行封裝。
下面就來一一介紹下筆者覺得實現此業務場景的幾種方案。
1.消息隊列
2.Quartz任務調度組件
3.Hangfire任務調度組件
4.Weshare.TransferJob(推薦)
首先說下消息隊列的方式。準確的說,消息隊列應該是這種場景的最優解決方案,消息隊列的其中一個比較重要的特性就是解耦,從而提高吞吐量。但並不是所有的應用程序都需要上消息隊列。有些業務場景使用消息隊列時,往往會給人一種”殺雞用牛刀”的感覺。
其次Quartz和Hangfire都是任務調度框架,都提供了可實現以上業務場景的邏輯,但Quartz和Hangfire都需要持久化作業數據。雖然Hangfire提供了內存版本,但經過我的測試,發現Hangfire的內存版本特別消耗內存,所以不太推薦使用任務調度框架來實現類似於這樣的業務邏輯。
最後,也就是本文的重點,筆者結合了消息隊列和任務調度的思想,實現了一個輕量級的轉移作業到後台執行的組件。此組件完美的解決了Scope生命周期實例獲取的問題,一行代碼將不需要等待的操作轉移到後台線程執行。
接入步驟如下:
1.使用nuget安裝Weshare.TransferJob
2.在Stratup中注入服務。
services.AddTransferJob();
3.通過構造函數或其他方法獲取到IBackgroundRunService的實例。
4.調用實例的Transfer方法將作業轉移到後台線程。
_backgroundRunService.Transfer(log=>log.Insert(new Log(){Txt = "註冊日誌"}));
就是這麼簡單的實現了這樣的業務場景,不僅簡化了代碼,而且大大提高了系統的吞吐量。
下面再來一起分析下Weshare.TransferJob的核心代碼(畢竟文章要點題)。各位器宇不凡的看官請繼續往下看。
下面的代碼是AddTransferJob方法的實現:
public static IServiceCollection AddTransferJob(this IServiceCollection services)
{
services.AddSingleton<IBackgroundRunService, BackgroundRunService>();
services.AddHostedService<TransferJobHostedService>();
return services;
}
聰明”絕頂”的各位看官應該已經發現上述代碼的關鍵所在。是的, 你沒有看錯,此組件的就是利用.net core提供的HostedService在後台執行被轉移的作業的。
我們再來一起看看TransferJobHostedService的代碼:
public class TransferJobHostedService:BackgroundService
{
private IBackgroundRunService _runService;
public TransferJobHostedService(IBackgroundRunService runService)
{
_runService = runService;
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
await _runService.Execute(stoppingToken);
}
}
}
這個類的代碼也很簡單,重寫了BackgroundService類的ExecuteAsync,循環調用IBackgroundRunService實例的Execute方法。所以,最最關鍵的代碼是IBackgroundRunService的實現類中。
詳細代碼如下:
public class BackgroundRunService : IBackgroundRunService
{
private readonly SemaphoreSlim _slim;
private readonly ConcurrentQueue<LambdaExpression> queue;
private ILogger<BackgroundRunService> _logger;
private readonly IServiceProvider _serviceProvider;
public BackgroundRunService(ILogger<BackgroundRunService> logger, IServiceProvider serviceProvider)
{
_slim = new SemaphoreSlim(1);
_logger = logger;
_serviceProvider = serviceProvider;
queue = new ConcurrentQueue<LambdaExpression>();
}
public async Task Execute(CancellationToken cancellationToken)
{
try
{
await _slim.WaitAsync(cancellationToken);
if (queue.TryDequeue(out var job))
{
using (var scope = _serviceProvider.GetRequiredService<IServiceScopeFactory>().CreateScope())
{
var action = job.Compile();
var isTask = action.Method.ReturnType == typeof(Task);
var parameters = job.Parameters;
var pars = new List<object>();
if (parameters.Any())
{
var type = parameters[0].Type;
var param = scope.ServiceProvider.GetRequiredService(type);
pars.Add(param);
}
if (isTask)
{
await (Task)action.DynamicInvoke(pars.ToArray());
}
else
{
action.DynamicInvoke(pars.ToArray());
}
}
}
}
catch (Exception e)
{
_logger.LogError(e.ToString());
}
}
public void Transfer<T>(Expression<Func<T, Task>> expression)
{
queue.Enqueue(expression);
_slim.Release();
}
public void Transfer(Expression<Action> expression)
{
queue.Enqueue(expression);
_slim.Release();
}
}
納尼?嫌代碼多看不懂?那咱們一起來剖析下吧。
首先,此類有三個較重要的私有變量,對應的類型分別是SemaphoreSlim, ConcurrentQueue ,IServiceProvider。
其中SemaphoreSlim是為了控制後台作業執行的順序的,在構造函數中初始化了此對象的信號量為1,表示在後台服務的ExecuteAsync方法的循環中每次只能有一個作業執行。
ConcurrentQueue 的對象是用來存儲被轉移到後台服務執行的作業的邏輯,所以使用LambdaExpression作為隊列的類型。
IServiceProvider是為了解決依賴注入的生命周期的。
然後在Execute方法中,第一行代碼如下:
await _slim.WaitAsync(cancellationToken);
作用是等待一個信號量,當沒有可用的信號量時,會阻塞線程的執行,這樣在後台服務的ExecuteAsync方法的死循環就不會一直執行下去,只有獲取到信號量才會繼續執行。
當獲取到信號量后,則說明有新的作業等待執行,所以此時則需要從隊列中讀出要執行的LambdaExpression表達式,創建一個新的Scope后,編譯此表達式樹,判斷返回類型,獲取泛型的具體類型,最後獲取到泛型對應的實例,執行對應的方法。
另外,Transfer方法就是暴露給調用者的方法,用於將表達式樹寫到隊列中,同時釋放信號量。
到此為止,Weshare.TransferJob的實現原理已分析完畢,由於此組件的原理只是將任務轉移到後台進行執行,所以並不是適合對事務有要求的場景。正如本文開頭所假設的場景,TransferJob最適合的場景還是那些和主操作關聯性較低的、失敗或成功並不會影響業務的正常運行。
同時,此組件的定位就是小而美,像延遲執行、定時執行的功能在最初的規劃中其實是有的,後來發現這些功能quartz已經有了,所以沒必要重複造這樣的輪子。
後期會根據使用場景,嘗試加入異常重試機制,以及異常通知回調機制。
最後,不知道有沒有較真的看官想計算下代碼量是否超過120行。
為了證明我不是標題黨,現將此組件進行開源,地址是:
https://github.com/fuluteam/WeShare.TransferJob
橋豆麻袋,筆者辛苦敲的代碼,難道各位看官想白嫖嗎? 點個贊再走唄。點完贊還有力氣的話,如果git上能點個star的話,那也是最好不過的。小生這廂先行謝過。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
在多線程併發的情況下,單個節點內的線程安全可以通過synchronized關鍵字和Lock接口來保證。
synchronized和lock的區別
Lock是一個接口,是基於在語言層面實現的鎖,而synchronized是Java中的關鍵字,是基於JVM實現的內置鎖,Java中的每一個對象都可以使用synchronized添加鎖。
synchronized在發生異常時,會自動釋放線程佔有的鎖,因此不會導致死鎖現象發生;而Lock在發生異常時,如果沒有主動通過unLock()去釋放鎖,則很可能造成死鎖現象,因此使用Lock時需要在finally塊中釋放鎖;
Lock可以讓等待鎖的線程響應中斷,而synchronized卻不行,使用synchronized時,等待的線程會一直等待下去,不能夠響應中斷;
Lock可以提高多個線程進行讀操作的效率。(可以通過readwritelock實現讀寫分離,一個用來獲取讀鎖,一個用來獲取寫鎖。)
當開發的應用程序處於一個分佈式的集群環境中,涉及到多節點,多進程共同完成時,如何保證線程的執行順序是正確的。比如在高併發的情況下,很多企業都會使用Nginx反向代理服務器實現負載均衡的目的,這個時候很多請求會被分配到不同的Server上,一旦這些請求涉及到對統一資源進行修改操作時,就會出現問題,這個時候在分佈式系統中就需要一個全局鎖實現多個線程(不同進程中的線程)之間的同步。
常見的處理辦法有三種:數據庫、緩存、分佈式協調系統。數據庫和緩存是比較常用的,但是分佈式協調系統是不常用的。
常用的分佈式鎖的實現包含:
Redis分佈式鎖、Zookeeper分佈式鎖、Memcached
Redis提供的三種方法:
(1)鎖 SETNX:只在鍵 key 不存在的情況下, 將鍵 key 的值設置為 value 。若鍵 key 已經存在, 則 SETNX 命令不做任何動作。SETNX 是『SET if Not eXists』(如果不存在,則 SET)的簡寫。命令在設置成功時返回 1 , 設置失敗時返回 0 。
redis> SETNX job "programmer" # job 設置成功 (integer) 1 redis> SETNX job "code-farmer" # 嘗試覆蓋 job ,失敗
(2)解鎖 DEL:刪除給定的一個或多個 key 。
(3)鎖超時 EXPIRE: 為給定 key 設置生存時間,當 key 過期時(生存時間為 0 ),它會被自動刪除。
每次當一個節點想要去操作臨界資源的時候,我們可以通過redis來的鍵值對來標記一把鎖,每一進程首先通過Redis訪問同一個key,對於每一個進程來說,如果該key不存在,則該線程可以獲取鎖,將該鍵值對寫入redis,如果存在,則說明鎖已經被其他進程所佔用。具體邏輯的偽代碼如下:
try{
if(SETNX(key, 1) == 1){
//do something ......
}finally{
DEL(key);
}
但是此時,又會出現問題,因為SETNX和DEL操作並不是原子操作,如果程序在執行完SETNX后,而並沒有執行EXPIRE就已經宕機了,這樣一來,原先的問題依然存在,整個系統都將被阻塞。
幸虧Redis又提供了SET key value timeout NX方法,可以以原子操作的方式完成SETNX和EXPIRE的操作。此時只需如下操作即可。
try{
if(SET(key, 1, 30, timeout, NX) == 1){
//do something ......
}
}finally{
DEL(key);
}
解決了原子操作,仍然還有一點需要注意,例如,A節點的進程獲取到鎖的時候,A進程可能執行的很慢,在do something未完成的情況下,30秒的時間片已經使用完,此時會將該key給深處掉,此時B進程發現這個key不存在,則去訪問,並成功的獲取到鎖,開始執行do something,此時A線程恰好執行到DEL(key),會將B的key刪除掉,此時相當於B線程在訪問沒有加鎖的臨界資源,而其餘進程都有機會同時去操作這個臨界資源,會造成一些錯誤的結果。對於該問題的解決辦法是進程在刪除key之前可以做一個判斷,驗證當前的鎖是不是本進程加的鎖。
String threadId = Thread.currentThread().getId()
try{
if(SET(key, threadId, 30, timeout, NX) == 1){
//do something ......
}
}finally{
if(threadId.equals(redisClient.get(key))){
DEL(key);
}
}
上面的改進雖然解決鎖被不同的進程釋放的危險,但並沒有解決獲取到鎖的進程在指定的時間內未完成do something操作(上面的代碼還有一點小問題,就是判斷操作和釋放鎖是兩個獨立的操作,不具備原子性。假設線程A判斷完確實是自己加的鎖 , 這時還沒del ,這時有效的時間用完了 , 緊接着線程B又馬上搶到了鎖 , 然後線程A才執行del命令 , 就會把B搶到的鎖給誤刪了),使得卡住的進程有可能與後來的進程同時同問臨界資源,而出現問題,因此一旦某個進程無法在超時時間內完成對臨界資源的操作,就需要延長超時的時間。此時可以啟動一個守護進程,監視指定時間內獲取鎖的進程是否完成操作,如果沒有,則添加超時時間,讓程序繼續執行。
String threadId = Thread.currentThread().getId()
try{
if(SET(key, threadId, 30, timeout, NX) == 1){
new Thread(){
@Override
public void run() {
//start Daemon
}
}
//do something ......
}
}finally{
if(threadId.equals(redisClient.get(key))){
DEL(key);
}
}
基於以上的分析,基本上可以通過Redis實現一個分佈式鎖,如果我們想提升該分佈式的性能,我們可以對連接資源進行分段處理,將請求均勻的分佈到這些臨界資源段中,比如一個買票系統,我們可以將100張票分為10 部分,每部分包含10張票放在其他的服務節點上,這些請求可以通過Nginx被均勻的分散到這些處理節點上,可以加快對臨界資源的處理。
併發編程的鎖機制:synchronized和lock
B站視頻上一部分講解
什麼是分佈式鎖?
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
摘錄自2020年7月22日中央社報導
22日發布在科學期刊「自然」(Nature)的一份調查,首度全面了解全球哪裡的礁鯊實際上已滅絕。這份調查為期四年,在近60個國家超過370個暗礁海域進行研究。
加拿大達爾豪希大學(Dalhousie University)副教授麥克尼爾(Aaron MacNeil)表示:「我們原本預期……地球上每個暗礁海域應該都有鯊魚出沒,結果發現我們調查的海域中,有20%沒有任何鯊魚,這令人非常擔心。」
調查顯示,在卡達、印度、越南及肯亞等八個國家的暗礁海域,完全找不到鯊魚。這不代表這些國家的海域沒有鯊魚,但證明當地暗礁海域的鯊魚數量少得可憐。這表示礁鯊在當地生態系統已失去任何角色,也就是牠們已經功能性滅絕。
研究指出,破壞性的捕魚活動最可能是礁鯊數量大減罪魁禍首。「使用流刺網和延繩捕魚,對原本數量相對豐沛的礁鯊帶來最大負面影響。」
生物多樣性
物種保育
土地利用
農林漁牧業
國際新聞
全球
鯊魚
暗礁
滅絕
捕魚
生態系統
流刺網
延繩釣
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案