我想獨立實現一個全棧產品為什麼這麼難
日常生活中,我們會使用很多軟件產品。在使用這些產品的時候,我們看得見的東西稱為“前端界面”如一個輸入框、一個按鈕,點擊按鈕之後發生的一切看不見的東西稱為“後端服務”。與之對應的創造者分別稱為“前端程序員”、“後端程序員”,然而,一個完整產品的開發不僅僅是只有前端和後端,還有設計師,架構師,運維等。有沒有可能這些所有的事情都一個人干呢?有可能,事實上如今就有很多的“全棧工程師”,他們身兼數職,是多面手。能獨立完成一個產品的方方面面。這種人固然十分了得,他們通常具有多年的經驗,涉獵廣泛,是老手,也是高手,當有一個產品想法的時候,他們可以用自己的全面專業技能,盡情的發揮去實現自己的想法。所以,從某種意義上講“全棧也是一種自由”,你可以自由的實現你的想法,這簡直太美妙了!
然而,很多時候當我們有一個產品想法的時候,我們往往發現,前端寫完了,後端怎麼搞?數據庫怎麼搞?域名怎麼搞?域名還要備案?應用部署怎麼搞?我的買什麼樣的服務器啊?靜態資源 CDN 怎麼搞?文件上傳服務器怎麼搞?萬一訪問用戶多了能撐住嗎?等等……問題很多,導致你的一個個想法,都只是在腦海中曇花一現,從來都無法將她們實現,或者說你激情飽滿的實現了其中自己最擅長的一部分,當碰到其他難題的時候就止步了。於是仰天長嘯:我就想獨立做一個完整的產品為什麼這麼難?年輕人,這一切都不怪你……
破局:小程序雲開發
為什麼使用小程序雲開發來破局?
為啥是用“小程序雲開發”來破局?首先,我們的目的是全棧實現一個產品。全棧可以有多種技術方案,你可用任何你能會的技能來達到全棧的目的。你可以開發安卓,IOS,或者 PC 站,然而小程序是最實際的!為啥?手機上能做的事情為啥要用 PC 版?OK,既然手機版比較好,那能不能再簡單一點?能,就是小程序,不需要開發IOS,安卓兩個版本。可以快速產出,快速試錯。
其次,前面說到了,全棧實現一個產品並不容易,對很多人來說甚至是巨難!選擇了小程序已經是比較划算的方案。而再集成雲開發,全棧立馬就有了。這就是為什麼選擇“小程序雲開發”來破局。
小程序雲開發是什麼?
小程序雲開發是什麼?官方文檔是這麼說的:開發者可以使用雲開發開發微信小程序、小遊戲,無需搭建服務器,即可使用雲端能力。雲開發為開發者提供完整的原生雲端支持和微信服務支持,弱化後端和運維概念,無需搭建服務器,使用平台提供的 API 進行核心業務開發,即可實現快速上線和迭代,同時這一能力,同開發者已經使用的雲服務相互兼容,並不互斥。
看完上面的描述,也許你仍然無法非常清楚的知道什麼是“小程序雲開發”,沒關係,你只需要注意加粗的部分,大概知道它“無需搭建服務器”,從傳統觀念將,這個似乎“毀三觀”咋可能沒服務器啊?是的,可以沒有傳統意義上的服務器,這種模式是 serveless 的。
那麼,小程序雲開發提供了哪些東西來破局呢?且看下面的表格:
| 能 力 | 作 用 | 說 明 |
|---|---|---|
| 雲函數 | 無需自建服務器 | 在雲端運行的代碼,微信私有協議天然鑒權,開發者只需編寫自身業務邏輯代碼 |
| 數據庫 | 無需自建數據庫 | 一個既可在小程序前端操作,也能在雲函數中讀寫的 JSON 數據庫 |
| 存儲 | 無需自建存儲和 CDN | 在小程序前端直接上傳/下載雲端文件,在雲開發控制台可視化管理 |
| 雲調用 | 原生微信服務集成 | 基於雲函數免鑒權使用小程序開放接口的能力,包括服務端調用、獲取開放數據等能力 |
上面的表格中提到了“雲開發”中的一些能力:“雲函數”,“數據庫”,“存儲”,“雲調用”,我們可以將這些詞帶入你曾經開發過的應用,看看它們分別代表了哪些部分。對於程序員來說,如果有疑問的話,沒有什麼是一個 helloword 解決不了的。
實戰:獨立開發一個簡易的零售小程序
哆嗦再多,不如實戰。下面我們就來使用小程序雲開發實現一個簡單的零售小程序。
項目構思
既然是一個零售小程序,那麼我們可以思考一下零售小程序的大致業務流程,以及粗略的梳理一下,其功能點。現根據自己的想法,大致畫一下草圖,如果沒有靈感可以參考一下別的 APP 是如何設計的。
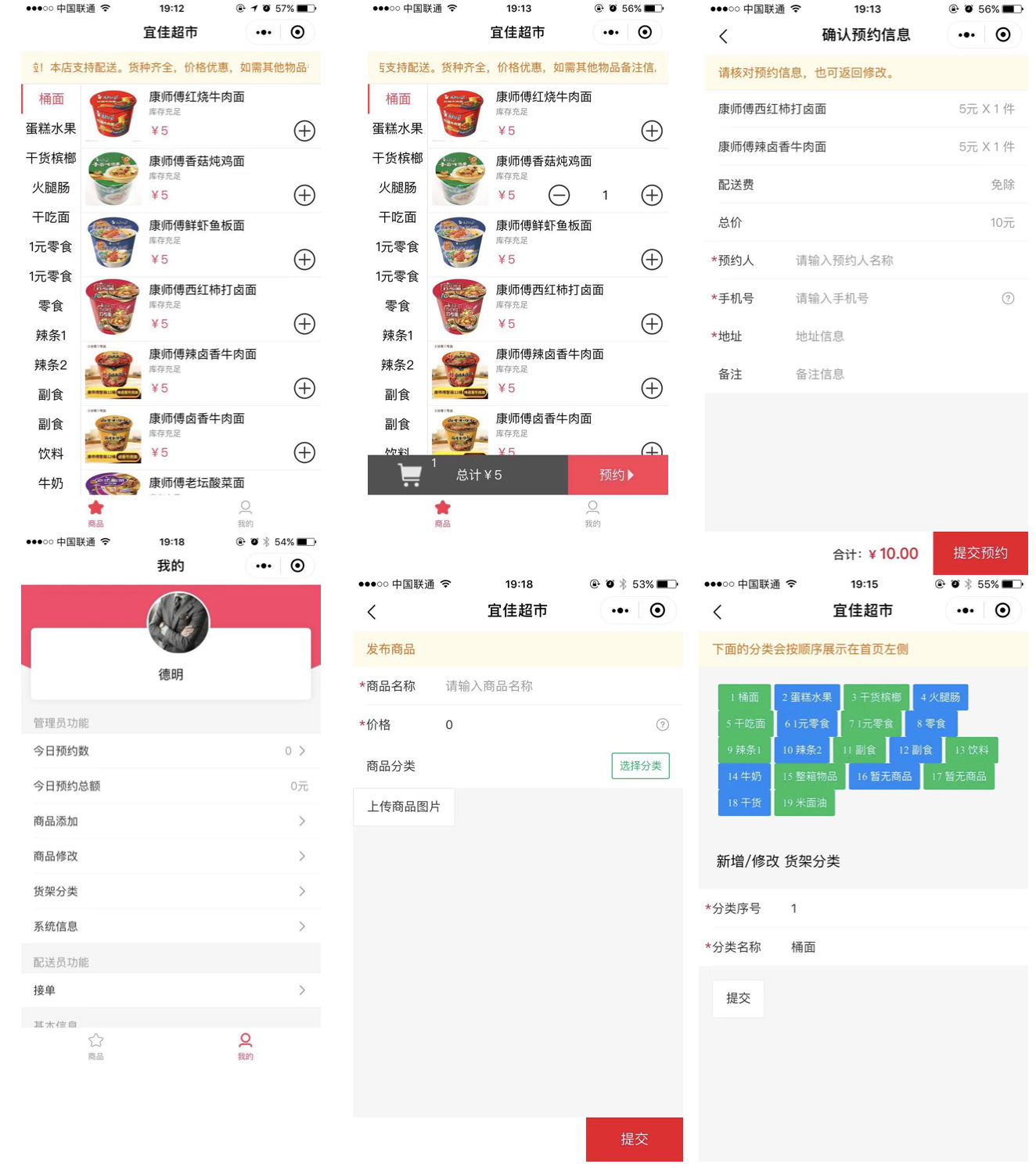
我根據自己的想法設計之後是這樣的:
功能模塊:首頁,商品列表頁,購物車,確認訂單,個人中心,個人訂單,管你模塊(商品添加,分類添加)其中商品需要上傳圖片。
梳理完功能之後,我們對於要實現的東西已經有個初步的概念了。接下來,我們需要大概畫一下頁面設計、及功能流轉。初次設計可能沒有太多經驗,沒關係,開始做就行了,做着做着就會想法越來越多,然後優化的越來越好。。我也是經過了多番修改調整,最終找到了一些思路。我的(拙劣)設計如下,圖片如果看不清楚可複製圖片鏈接在新窗口打開查看:
說明,以上圖片是根據成品(我真的開發了一個雲小程序並上線使用了)截圖的,而實際我再設計的時候也是經過幾番修改才最終定成這樣。
同時,補充說明一下,這裏前端頁面使用的是 vant-weapp控件,非常好用。推薦!如果你和我一樣是一個純後端程序員,建議使用 vant-weapp 來作為 ui,非常方便。否則自己寫頁面樣式的話可能就做不出來了。全棧不是那麼好乾的啊。選擇自己能駕馭的,能實現最終功能,就是一個合格的全棧。
創建小程序雲開發項目
我們先下載微信小程序開發工具,下載地址,安裝好了之後,新建項目,界面如下,APPID 需要你自己去註冊一個。然後注意,選擇“小程序雲開發”,如下圖所示:
創建好了之後,項目目錄如下,先看 1 標註的地方:
如果你曾經有過小程序的開發經驗,那麼miniprogram文件夾下面的結構你肯定熟悉了,miniprogram下面的子目錄分別是小程序對應的組件、圖片、頁面、樣式以及app.js,app.json,sitemap.json,其中components下面的vant-weapp就是上面提到的 ui 組件。
最後一個比較重要的文件夾就是cloudfunctions,這個目錄是用來存放“雲函數的”,雲函數就是我們的後端。每一個雲函數提供一個服務。一個個的雲函數組成了我們整體的後端服務。雲函數可以看做是 FaaS(function as a service)。途中,2 標記的位置的“雲開發”按鈕,我們點進去,就可以看到“雲開發的控制台”,如下圖所示:
如果上圖看不清楚,可以複製鏈接到新的瀏覽器窗口查看,如圖,小程序雲開發默認的免費套餐有一定的額度可供使用。首頁便是使用統計。然後我們能看到,有“數據庫”,“存儲”,“雲函數”。
這裏的“數據庫”其實就是類似於一個 MongoDB,你可以點進去創建一個個的 collection(即:關係型數據庫中的table);這裏的“存儲”其實就是“文件夾”,我們可以通過微信提供的 api把圖片上傳到“存儲”中;這裏的“雲函數”就是我們需要實現的後端業務邏輯,他就是一個個的函數(函數由我們自己寫好後上傳)。一般開發過程中我們在開發者工具中的cloudfunctions目錄下創建雲函數(比方說是:user-add)開發完成之後在雲函數目錄點擊右鍵——上傳即可。然後就可以在小程序的代碼中調用這個user-add雲函數。
雲開發之——3 分鐘實現文件上傳
注意:在開始雲開發之前,我們現在 小程序代碼的 app.js 中加入wx.cloud.init,如下:
App({
onLaunch: function () {
if (!wx.cloud) {
console.error('請使用 2.2.3 或以上的基礎庫以使用雲能力')
} else {
wx.cloud.init({
// env 參數說明:
// env 參數決定接下來小程序發起的雲開發調用(wx.cloud.xxx)會默認請求到哪個雲環境的資源
// 此處請填入環境 ID, 環境 ID 可打開雲控制台查看
// 如不填則使用默認環境(第一個創建的環境)
env: 'your-env-id',
traceUser: true,
})
}
this.globalData = {}
}
})上面的圖中,我們已經看到了“商品添加”頁面的效果,它需要我們輸入商品名稱、價格、並上傳圖片,然後保存。傳統架構中,上傳圖片需要前端頁面擺一個控件,然後後端提供一個 api用來接收前端傳來的文件,通常來說這個後端 api 接收到圖片之後,會將圖片文件保存到自己的文件服務器或者是阿里雲存儲、或者是七牛雲存儲之類的。然後返回給你一個文件鏈接地址。非常麻煩,然而,小程序雲開發上傳文件超級簡單,上代碼:
頁面代碼:
<van-notice-bar
scrollable="false"
text="發布商品"
/>
<van-field
value="{{ productName }}"
required
clearable
label="商品名稱"
placeholder="請輸入商品名稱"
bind:change="inputName"
/>
<van-field
value="{{ productPrice }}"
required
clearable
label="價格"
icon="question-o"
bind:click-icon="onClickPhoneIcon"
placeholder="請輸入價格"
error-message="{{phoneerr}}"
border="{{ false }}"
bind:change="inputPrice"
/>
<van-action-sheet
required
show="{{ showSelect }}"
actions="{{ actions }}"
close-on-click-overlay="true"
bind:close="toggleSelect"
bind:select="onSelect" cancel-text="取消"
/>
<van-field
value="{{ productCategory }}"
center
readonly
label="商品分類"
border="{{ false }}"
use-button-slot
>
<van-button slot="button" size="small" plain type="primary"
bind:click="toggleSelect">選擇分類</van-button>
</van-field>
<van-button class="rightside" type="default" bind:click="uploadImage" >上傳商品圖片</van-button>
<view class="imagePreview">
<image src="{{productImg}}" />
</view>
<van-submit-bar
price="{{ totalShow }}"
button-text="提交"
bind:submit="onSubmit"
tip="{{ false }}"
>
</van-submit-bar>
<van-toast id="van-toast" />
<van-dialog id="van-dialog" />這裡有個控件,綁定了uploadImage方法,其代碼為:
uploadImage:function(){
let that = this;
wx.chooseImage({
count: 1,
sizeType: ['compressed'],
sourceType: ['album', 'camera'],
success(res) {
wx.showLoading({
title: '上傳中...',
})
const tempFilePath = res.tempFilePaths[0]
const name = Math.random() * 1000000;
const cloudPath = name + tempFilePath.match(/\.[^.]+?$/)[0]
wx.cloud.uploadFile({
cloudPath:cloudPath,//雲存儲圖片名字
filePath: tempFilePath,//臨時路徑
success: res => {
let fileID = res.fileID;
that.setData({
productImg: res.fileID,
});
wx.showToast({
title: '圖片上傳成功',
})
},
fail: e =>{
wx.showToast({
title: '上傳失敗',
})
},
complete:()=>{
wx.hideLoading();
}
});
}
})
}這裏,wx.chooseImage用於調起手機選擇圖片(相冊/相機拍照),然後wx.cloud.uploadFile用於上傳圖片到上面說到的雲開發能力之一的“存儲”中。上傳圖片成功之後返回一個文件 ID,類似:
cloud://release-0kj63.7265-release-0kj63-1300431985/100477.13363146288.jpg 這個鏈接可以直接在小程序頁面展示:
<image src="cloud://release-0kj63.7265-release-0kj63-1300431985/100477.13363146288.jpg " />也可以通過微信 api,裝換成 http 形式的圖片鏈接。
雲開發之——操作數據庫,1 分鐘寫完保存商品到數據庫的代碼
上面我們實現了商品圖片上傳,但是,商品圖片並沒有保存到數據庫。正常錄入商品的時候,我們會填好商品名稱,價格等,然後上傳圖片,最終點擊“保存”按鈕,將商品保存到數據庫。傳統模式下,前端仍然是需要調用一個後端接口,通過 post 提交數據,最終由後端服務(比如 java 服務)將數據保存到數據庫。小程序雲開發使得操作數據庫十分簡單,首先我們在雲開發控制台創建“商品表”,即一個 collection,取名為:products。然後我們就可以保存數據到數據庫了,代碼如下:
onSubmit:function(){
// 校驗代碼,略
let product = {};
product.imgId = this.data.productImg;
product.name= this.data.productName;
product.categoryId = this.data.productCategoryId;
product.price = this.data.productPrice;
// 其他賦值,略
const db = wx.cloud.database();
db.collection('products').add({
data: product,
success(res) {
wx.showToast({
title: '保存成功',
})
}
});
}以上就實現了數據入庫,就這點代碼,超簡單,1 分鐘寫完,誠不欺我。其中這裏的products就是我們的“商品表”,之前說過,類似 MongoDB 數據庫,這裏操作的是db.collection,這和 MongoDB 的語法差不多。
雲開發之——使用雲函數完成後端業務邏輯,訂單創建
小程序雲開發提供了幾大能力:“數據庫”,“存儲”,“雲函數”,前兩項我們已經有所體會了。下面我們能創建一個雲函數來實現訂單創建。這裏說明,雲函數其實就是 一段JavaScript 代碼,上傳至雲服務器之後,最終也是運行在 nodejs 環境的,只是這一切,我們不需要關心。我們只需要關心我們這個雲函數提供的功能是什麼就可以了。
創建雲函數很簡單,直接在開發工具中右鍵“新建Node.js 雲函數”。然後以創建訂單為例,假設我們創建一個雲函數名為c-order-add,創建好了之後,目錄是這樣:
雲函數的主要代碼在 index.js 中,其完整代碼是這樣:
// 雲函數入口文件
const cloud = require('wx-server-sdk')
cloud.init({
env: 'release-xxx'// your-env-id
})
const db = cloud.database()
// 雲函數入口函數
exports.main = async (event, context) => {
const wxContext = cloud.getWXContext();
console.log("雲函數 c-order-add : ")
// 這裡是一些邏輯處理...
return await db.collection('uorder').add({
data: {
openid: event.userInfo.openId,
address: event.address,
userName: event.userName,
phone: event.phone,
shoppingInfo: event.shoppingInfo,
totlePrice: event.totlePrice,
shoppingStr: event.shoppingStr,
remark:event.remark,
createTime: now,
// ...
}
});
}這個雲函數寫好之後,需要上傳到服務器,直接在雲函數目錄點擊右鍵,然後點擊“上傳並部署”即可,這就相當於部署好了後端服務。前端小程序頁面調用的寫法是這樣的:
let orderData={};
orderData.userName = this.data.userName;
orderData.phone = this.data.phone;
orderData.address = this.data.address;
// ....
wx.cloud.callFunction({
// 雲函數名稱
name: 'c-order-add',
// 傳給雲函數的參數
data: orderData,
complete: res => {
Dialog.alert({
title: '提交成功',
message: '您的訂單成功,即將配送,請保持手機通暢。'
}).then(() => {
// ....
wx.redirectTo({
url: '../uorder/uorder'
});
});
}
})這裏,向程序前端,通過wx.cloud.callFunction完成了對雲函數的調用,也可以理解為對後端服務的調用。至此我們我們介紹完了,小程序雲開發的功能。雖然,我只貼出了少量的代碼,即保存商品,和提交訂單。由於時間和篇幅有限,我不可能把整個完整的程序代碼貼出來。但是你可以參照這個用法示例,將剩下的業務邏輯補充完整,最終完成“項目構思”一節中展示的成品截圖效果。
小程序審核的一點經驗
我開發的小程序審核在提交審核的時候遭遇了兩次退回,第一次是因為:“小程序具備電商性質,個人小程序號不支持”。所以,我只好申請了一個企業小程序號,使用的是超市的營業執照。服務類目的選擇也被打回了一次,最後選擇了食品還提交了食品經營許可證。第二次打回是因為:“用戶體驗問題”。其實就是“授權索取”的問題,微信不讓打開首頁就“要求授權”,同時不能強制用戶接受授權,得提供拒絕授權也能使用部分功能。
上面兩條解決之後,更新新了好幾版,都沒有出現過被拒的情況。並且,有次我是夜晚 10 左右提價的審核,結果10 點多就提示審核通過,當時沒看具體時間,就是接盆水泡了個腳的時間審核通過了。所以,我推斷小程序審核初次審核會比較嚴,之後如果改動不大應該直接機審就過了。
總結及對比
這裏我們可以對小程序雲開發和傳統模式做一個對比:
| 對比條目 | 傳統模式 | 雲開發 |
|---|---|---|
| 是否需要後端服務 | 需要 (如一個java應用部署在 Tomcat 中) | 不需要 只需要“雲函數” |
| 是否需要域名 | 需要 (還得在微信後台的把域名加入安全域名) | 不需要 |
| 是否需要購買服務器 | 需要 (你得部署後端 Java 應用,還得安裝數據庫) | 不需要 開通雲開發之後免費套餐夠用 不夠的話購買套餐按調用量計費 |
| 是否需要懂運維 | 需要 (你得會折騰服務器,數據庫之類的 還得配置好相關的用戶,端口,啟動服務) |
不需要 |
| 圖片上傳及 CDN | 麻煩 | 簡單 |
| 獲取微信 openID | 麻煩 | 超級簡單,雲函數中直接獲取 |
| ··· |
就對比這麼多吧,總之,我非常喜歡小程序雲開發,小程序真的可以讓你輕鬆干全棧。或者咱們別動不動就提“全棧”,姑且說,小程序雲開發可以讓你更簡單、更快速、更便宜的實現你的產品落地。我自己開發的雲小程序上線之後,使用了一兩個月,沒出現任何問題。我也不用操心服務器什麼的。所以,我已經給身邊很多人安利了小程序雲開發了。這裏我就不貼出我的小程序碼了,因為已經正式給我同學的超市使用了,所以不方便讓別人去產生測試數據。如果你感興趣想看的話,可以聯繫我。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選