目錄
前言
本文主要多方面講解java繼承,旨在讓初學者通俗易懂,至於“我爸是李剛”,反正樓主也不知道誰爸是李剛。
@
1、繼承的概述
1.1、繼承的由來
至於由來簡單一句話:多個類中存在相同屬性和行為時,將這些內容抽取到單獨一個類中,那麼多個類無需再定義這些屬性和行為。
繼承描述的是事物之間的所屬關係,這種關係是 is-a 的關係。
1.2、繼承的定義
繼承:就是子類繼承父類的屬性和行為,使得子類對象具有與父類相同的屬性、相同的行為。子類可以直接訪問父類中的非私有的屬性和行為。
這裏再聲明一點,父類又稱為超類或者基類。而子類又稱為派生類這點很基礎!
1.3、繼承的優點
- 提高代碼的復用性。
- 類與類之間產生關係,為多態做了完美的鋪墊(不理解沒關係,之後我會再寫一篇多態的文章)
雖然繼承的優點很多但是Java只支持單繼承,不支持多繼承。
1.4、繼承的格式
通過 extends 關鍵字,可以聲明一個子類繼承另外一個父類,定義格式如下:
class 父類 {
...
}
class 子類 extends 父類 {
...
} 2、關於繼承之後的成員變量
當類之間產生了關係后,其中各類中的成員變量,產生了哪些影響呢? 關於繼承之後的成員變量要從兩方面下手,一是成員變量不重名方面,二是成員變量重名方面。
2.1、成員變量不重名
如果子類父類中出現不重名的成員變量,這時的訪問是沒有影響的。代碼如下:
class liGang {
// 父類中的成員變量。
String name ="李剛";//------------------------------父類成員變量是name
}
class LiXiaoGang extends liGang {
// 子類中的成員變量
String name2 ="李小剛";//--------------------------子類成員變量是name2
// 子類中的成員方法
public void show() {
// 訪問父類中的name,
System.out.println("我爸是"+name);
// 繼承而來,所以直接訪問。
// 訪問子類中的name2
System.out.println("我是"+name2);
}
}
public class Demo {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang z = new LiXiaoGang();
// 調用子類中的show方法
z.show();
}
}
//演示結果: 我爸是李剛 我是李小剛2.2、 成員變量重名
如果子類父類中出現重名的成員變量,這時的訪問是有影響的。代碼如下:
class liGang {
// 父類中的成員變量。
String name ="李剛";//------------------------------父類成員變量是name
}
class LiXiaoGang extends liGang {
// 子類中的成員變量
String name ="李小剛";//---------------------------子類成員變量也是name
// 子類中的成員方法
public void show() {
// 訪問父類中的name,
System.out.println("我爸是"+name);
// 繼承而來,所以直接訪問。
// 訪問子類中的name2
System.out.println("我是"+name);
}
}
public class Demo {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang z = new LiXiaoGang();
// 調用子類中的show方法
z.show();
}
}
//演示結果: 我爸是李小剛 我是李小剛
子父類中出現了同名的成員變量時,在子類中需要訪問父類中非私有成員變量時,需要使用 super 關鍵字,至於修飾父類成員變量,類似於之前學過的 this 。 使用格式 super.父類成員變量名
this表示當前對象,super則表示父類對象,用法類似!
class liGang {
// 父類中的成員變量。
String name ="李剛";
}
class LiXiaoGang extends liGang {
// 子類中的成員變量
String name ="李小剛";
// 子類中的成員方法
public void show() {
// 訪問父類中的name,
System.out.println("我爸是"+super.name);
// 繼承而來,所以直接訪問。
// 訪問子類中的name2
System.out.println("我是"+this.name); //當然this可省略
}
}
public class Demo {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang z = new LiXiaoGang();
// 調用子類中的show方法
z.show();
}
}
//演示結果: 我爸是李剛 我是李小剛2.3、關於繼承中成員變量值得思考的一個問題
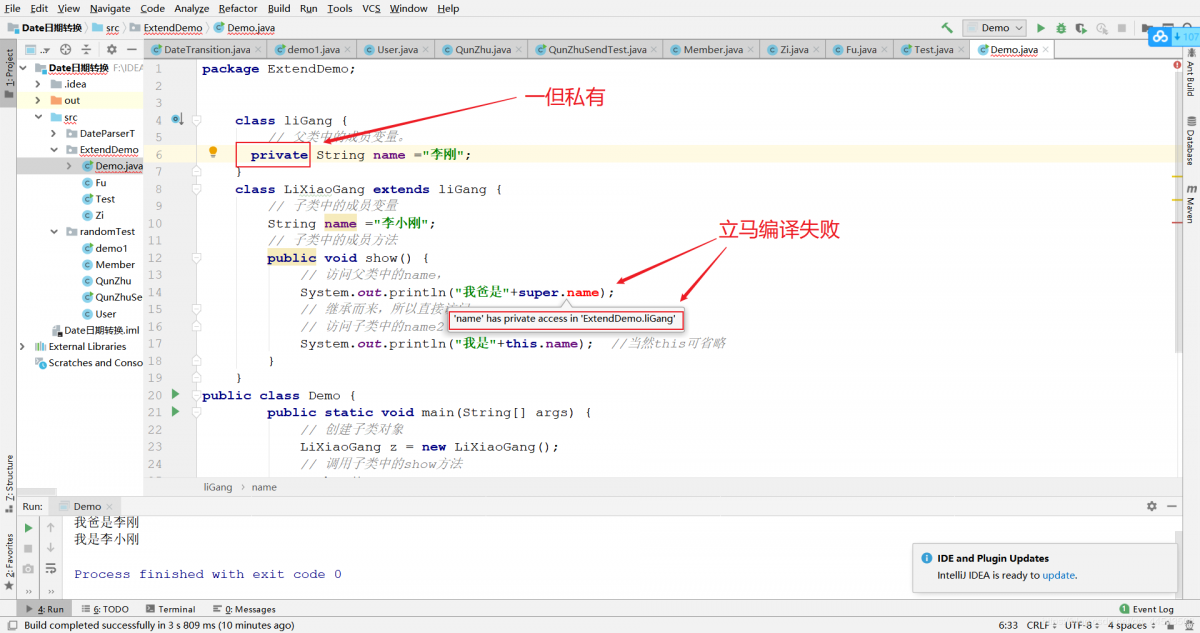
同學你有沒有想過這樣一個問題。如果父類中的成員變量
非私有:子類中可以直接訪問。
私有:子類是不能直接訪問的。如下:
當然,同學你要自己體驗體驗編譯報錯過程,看圖沒體驗感不得勁,~嘔,你這無處安放的魅力,無理的要求,我佛了,行吧~
class liGang2 {
// 父類中的成員變量。
private String name ="李剛";
}
class LiXiaoGang2 extends liGang2 {
// 子類中的成員變量
String name ="李小剛";
// 子類中的成員方法
public void show() {
// 訪問父類中的name,
System.out.println("我爸是"+super.name);//------編譯失敗不能直接訪問父類私有屬性(成員變量)
// 繼承而來,所以直接訪問。
// 訪問子類中的name2
System.out.println("我是"+this.name); //當然this可省略
}
}
public class PrivateVariable {
public static void main(String[] args) {
// 創建子類對象
ExtendDemo.LiXiaoGang z = new ExtendDemo.LiXiaoGang();
// 調用子類中的show方法
z.show();
}
}通常開發中編碼時,我們遵循封裝的原則,使用private修飾成員變量,那麼如何訪問父類的私有成員變量呢?其實這個時候在父類中提供公共的getXxx方法和setXxx方法就可以了。代碼如下:
class liGang {
// 父類中的成員變量。
private String name ="李剛";
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class LiXiaoGang extends liGang {
// 子類中的成員變量
String name ="李小剛";
// 子類中的成員方法
public void show() {
// 訪問父類中的name,
System.out.println("我爸是"+super.getName());
// 繼承而來,所以直接訪問。
// 訪問子類中的name2
System.out.println("我是"+this.name); //當然this可省略
}
}
public class Demo {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang z = new LiXiaoGang();
// 調用子類中的show方法
z.show();
}
}
//演示結果: 我爸是李剛 我是李小剛分析如下:
3、關於繼承之後的成員方法
分析完了成員變量,現在我們一起來分析分析成員方法。
想一想,當類之間產生了關係,其中各類中的成員方法,又產生了哪些影響呢? 同樣我們依舊從兩方面分析。
#### 3.1、成員方法不重名
如果子類父類中出現不重名的成員方法,這時的調用是沒有影響的。對象調用方法時,會先在子類中查找有沒有對 應的方法,若子類中存在就會執行子類中的方法,若子類中不存在就會執行父類中相應的方法。代碼如下:
class liGang3 {
// 父類中的成員方法。
public void zhuangRen1(){//--------------------------父類方法名zhuangRen1
System.out.println("我叫李剛,人不是我撞的,別抓我,我不認識李小剛");
}
}
class LiXiaoGang3 extends liGang3 {
// 子類中的成員方法
public void zhuangRen() {//--------------------------子類方法名zhuangRen
System.out.println("有本事你們告去,我爸是李剛");
}
}
public class MemberMethod {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang3 liXiaoGang = new LiXiaoGang3();
// 調用子類中的show方法
liXiaoGang.zhuangRen();
liXiaoGang.zhuangRen1();
}
}
打印結果:有本事你們告去,我爸是李剛
我叫李剛,人不是我撞的,別抓我,我不認識李小剛
#### 3.2、成員方法重名 【方法重寫】
成員方法重名大體也可以分兩種情況:
1、方法名相同返回值類型、參數列表卻不相同(優先在子類查找,沒找到就去父類)
2、方法名、返回值類型、參數列表都相同,沒錯這就是重寫(Override)
這裏主要講方法重寫 :子類中出現與父類一模一樣的方法時(返回值類型,方法名和參數列表都相同),會出現覆蓋效果,也稱為重寫或者複寫。聲明不變,重新實現。 代碼如下:
class liGang3 {
// 父類中的成員方法。
public void zhuangRen(int a){
System.out.println("我叫李剛,人不是我撞的,別抓我");
}
}
class LiXiaoGang3 extends liGang3 {
// 子類中的成員方法
public void zhuangRen(int a) {
System.out.println("有本事你們告去,我爸是李剛");
}
}
public class MemberMethod {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang3 liXiaoGang = new LiXiaoGang3();
// 調用子類中的zhuangRen方法
liXiaoGang.zhuangRen(1);
}
}
結果打印:有本事你們告去,我爸是李剛#### 3.3、繼承中重寫方法的意義
子類可以根據需要,定義特定於自己的行為。既沿襲了父類的功能名稱,又根據子類的需要重新實現父類方法,從而進行擴展增強。比如李剛會開車,李小剛就牛了,在父類中進行擴展增強還會開車撞人,代碼如下:
class liGang3 {
// 父類中的成員方法。
public void kaiChe(){
System.out.println("我會開車");
}
}
class LiXiaoGang3 extends liGang3 {
// 子類中的成員方法
public void kaiChe(){
super.kaiChe();
System.out.println("我還會撞人");
System.out.println("我還能一撞撞倆婆娘");
}
}
public class MemberMethod {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang3 liXiaoGang = new LiXiaoGang3();
// 調用子類中的zhuangRen方法
liXiaoGang.kaiChe();
打印結果: 我會開車
我還會撞人
我還能一撞撞倆婆娘
}
}
不知道同學們發現了沒有,以上代碼中在子類中使用了 super.kaiChe();super.父類成員方法,表示調用父類的成員方法。
最後重寫必須注意這幾點:
1、方法重寫時, 方法名與形參列表必須一致。
2、子類方法覆蓋父類方法時,必須要保證子類權限>=父類權限。
3、方法重寫時,子類的返回值類型必須要<=父類的返回值類型。
4、方法重寫時,子類拋出的異常類型要<=父類拋出的異常類型。
粗心的同學看黑板,look 這裏【注意:只有訪問權限是
>=,返回值、異常類型都是<=】
下面以修飾權限為例,如下:
4、關於繼承之後的構造方法
為了讓你更好的體會,首先我先編寫一個程序
class liGang4 {
// 父類的無參構造方法。
public liGang4(){
System.out.println("父類構造方法執行了。。。");
}
}
class LiXiaoGang4 extends liGang4 {
// 子類的無參構造方法。
public LiXiaoGang4(){
System.out.println("子類構造方法執行了====");
}
}
public class ConstructionDemo {
public static void main(String[] args) {
// 創建子類對象
LiXiaoGang4 z = new LiXiaoGang4();
}
}用一分鐘猜想一下結果是什麼,猜好了再看下面結果:
父類構造方法執行了。。。
子類構造方法執行了====好了,看了結果之後,你可能有疑惑。父類構造器方法怎麼執行了?我們先來分析分析,首先在main方法中實例化了子類對象,接着會去執行子類的默認構造器初始化,這個時候在構造方法中默認會在第一句代碼中添加super();沒錯,他就是開掛般的存在,不寫也存在的!有的調~讀四聲“跳”~皮的同學就會說,你說存在就存在啊,無憑無據 ~呀,你這個該死的靚仔~ 如下:
構造方法的名字是與類名一致的,所以子類是無法繼承父類構造方法的。 構造方法的作用是初始化成員變量的。所以子類的初始化過程中,必須先執行父類的初始化動作。子類的構造方法中默認會在第一句代碼中添加super(),表示調用父類的構造方法,父類成員變量初始化后,才可以給子類使用。
當然我已經強調很多遍了 super() 不寫也默認存在,而且只能是在第一句代碼中,不在第一句代碼中行不行,答案是當然不行,這樣會編譯失敗,如下:
5、關於繼承的多態性支持的例子
直接上代碼了喔
class A{
public String show(C obj) {
return ("A and C");
}
public String show(A obj) {
return ("A and A");
}
}
class B extends A{
public String show(B obj) {
return ("B and B");
}
}
class C extends B{
public String show(A obj) {
return ("A and B");
}
}
public class Demo1 {
public static void main(String[] args) {
A a=new A();
B b=new B();
C c=new C();
System.out.println("第一題 " + a.show(a));
System.out.println("第二題 " + a.show(b));
System.out.println("第三題 " + a.show(c));
}
}
運行結果:
第一題 A and A
第二題 A and A
第三題 A and C其實吧,第一題和第三題都好理解,第二題就有點意思了,會發現A類中沒有B類型這個參數,這個時候,你就應該知道子類繼承就是父類,換句話說就是子類天然就是父類,比如中國人肯定是人,但是人不一定是中國人(可能是火星人也可能是非洲人),所以父類做為參數類型,直接傳子類的參數進去是可以的,反過來,子類做為參數類型,傳父類的參數進去,就需要強制類型轉換。
6、super與this的用法
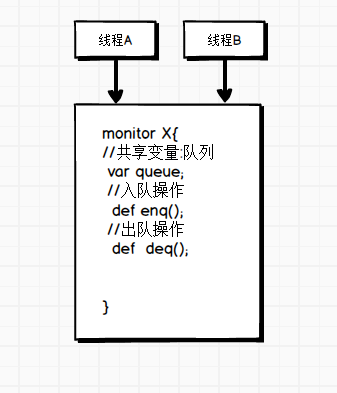
了解他們的用法之前必須明確一點的是父類空間優先於子類對象產生
在每次創建子類對象時,先初始化父類空間,再創建其子類對象本身。目的在於子類對象中包含了其對應的父類空間,便可以包含其父類的成員,如果父類成員非private修飾,則子類可以隨意使用父類成員。代碼體現在子類的構 造方法調用時,一定先調用父類的構造方法。理解圖解如下:
#### 5.1、 super和this的含義:
super:代表父類的存儲空間標識(可以理解為父親的引用)。
this:代表當前對象的引用(誰調用就代表誰)。
#### 5.2、 super和this訪問成員
this.成員變量 ‐‐ 本類的
super.成員變量 ‐‐ 父類的
this.成員方法名() ‐‐ 本類的
super.成員方法名() ‐‐ 父類的
#### 5.3、super和this訪問構造方法
this(...)‐‐ 本類的構造方法
super(...)‐‐ 父類的構造方法#### 5.4、super()和this()能不能同時使用?
不能同時使用,this和super不能同時出現在一個構造函數裏面,因為this必然會調用其它的構造函數,其它的構造函數必然也會有super語句的存在,所以在同一個構造函數裏面有相同的語句,就失去了語句的意義,編譯器也不會通過。
#### 5.5、總結一下super與this
子類的每個構造方法中均有默認的
super(),調用父類的空參構造。手動調用父類構造會覆蓋默認的super()。super()和this()都必須是在構造方法的第一行,所以不能同時出現。
到這裏,java繼承你get到了咩,get到了請咩一聲,隨便隨手~點個讚唄~
推薦閱讀本專欄的下一篇java文章
歡迎各位關注我的公眾號,一起探討技術,嚮往技術,追求技術…
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!