本文源碼:GitHub·點這裏 || GitEE·點這裏
一、異步處理
1、異步概念
異步處理不用阻塞當前線程來等待處理完成,而是允許後續操作,直至其它線程將處理完成,並回調通知此線程。
必須強調一個基礎邏輯,異步是一種設計理念,異步操作不等於多線程,MQ中間件,或者消息廣播,這些是可以實現異步處理的方式。
同步處理和異步處理相對,需要實時處理並響應,一旦超過時間會結束會話,在該過程中調用方一直在等待響應方處理完成並返回。同步類似電話溝通,需要實時對話,異步則類似短信交流,發送消息之後無需保持等待狀態。
2、異步處理優點
雖然異步處理不能實時響應,但是處理複雜業務場景,多數情況都會使用異步處理。
- 異步可以解耦業務間的流程關聯,降低耦合度;
- 降低接口響應時間,例如用戶註冊,異步生成相關信息表;
- 異步可以提高系統性能,提升吞吐量;
- 流量削峰即把請求先承接下來,然後在異步處理;
- 異步用在不同服務間,可以隔離服務,避免雪崩;
異步處理的實現方式有很多種,常見多線程,消息中間件,發布訂閱的廣播模式,其根據邏輯在於先把請求承接下來,放入容器中,在從容器中把請求取出,統一調度處理。
注意:一定要監控任務是否產生積壓過度情況,任務如果積壓到雪崩之勢的地步,你會感覺每一片雪花都想勇闖天涯。
3、異步處理模式
異步流程處理的實現有好多方式,但是實際開發中常用的就那麼幾種,例如:
- 基於接口異步響應,常用在第三方對接流程;
- 基於消息生產和消費模式,解耦複雜流程;
- 基於發布和訂閱的廣播模式,常見系統通知
異步適用的業務場景,對數據強一致性的要求不高,異步處理的數據更多時候追求的是最終一致性。
二、接口響應異步
1、流程描述
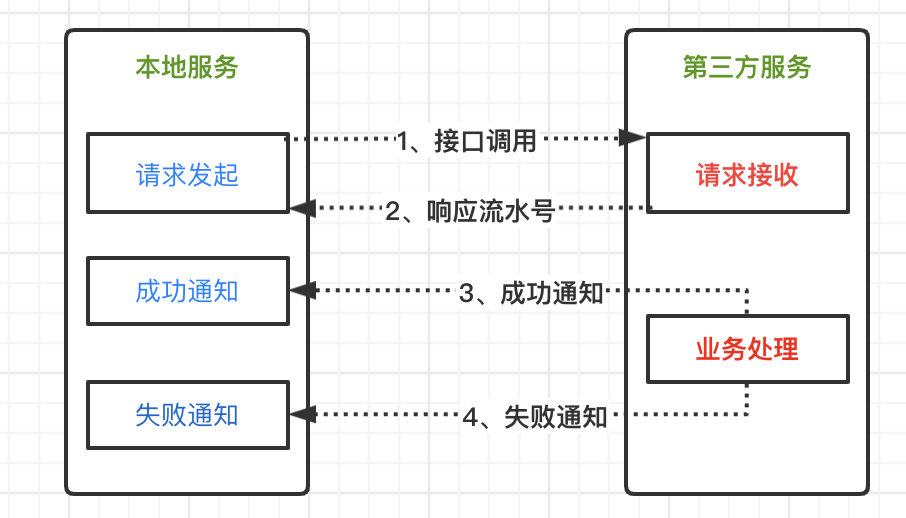
基於接口異步響應的方式,有一個本地業務服務,第三方接口服務,流程如下:
- 本地服務發起請求,調用第三方服務接口;
- 請求包含業務參數,和成功或失敗的回調地址;
- 第三方服務實時響應流水號,作為該調用的標識;
- 之後第三方服務處理請求,得到最終處理結果;
- 如果處理成功,回調本地服務的成功通知接口;
- 如果處理失敗,回調本地服務的失敗通知接口;
- 整個流程基於部分異步和部分實時的模式,完整處理;
注意:如果本地服務多次請求第三方服務,需要根據流水號判斷該請求的狀態,業務的狀態設計也是極其複雜,要根據流水號和狀態追溯整個流程的執行進度,避免錯亂。
2、流程實現案例
模擬基礎接口
@RestController
public class ReqAsyncWeb {
private static final Logger LOGGER = LoggerFactory.getLogger(ReqAsyncWeb.class);
@Resource
private ReqAsyncService reqAsyncService ;
// 本地交易接口
@GetMapping("/tradeBegin")
public String tradeBegin (){
String sign = reqAsyncService.tradeBegin("TradeClient");
return sign ;
}
// 交易成功通知接口
@GetMapping("/tradeSucNotify")
public String tradeSucNotify (@RequestParam("param") String param){
LOGGER.info("tradeSucNotify param={"+ param +"}");
return "success" ;
}
// 交易失敗通知接口
@GetMapping("/tradeFailNotify")
public String tradeFailNotify (@RequestParam("param") String param){
LOGGER.info("tradeFailNotify param={"+ param +"}");
return "success" ;
}
// 第三方交易接口
@GetMapping("/respTrade")
public String respTrade (@RequestParam("param") String param){
LOGGER.info("respTrade param={"+ param +"}");
reqAsyncService.respTrade(param);
return "NO20200520" ;
}
}
模擬第三方處理
@Service
public class ReqAsyncServiceImpl implements ReqAsyncService {
private static final String serverUrl = "http://localhost:8005" ;
@Override
public String tradeBegin(String param) {
String orderNo = HttpUtil.get(serverUrl+"/respTrade?param="+param);
if (StringUtils.isEmpty(orderNo)){
return "Trade..Fail...";
}
return orderNo ;
}
@Override
public void respTrade(String param) {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread thread01 = new Thread(
new RespTask(serverUrl+"/tradeSucNotify?param="+param),"SucNotify");
Thread thread02 = new Thread(
new RespTask(serverUrl+"/tradeFailNotify?param="+param),"FailNotify");
thread01.start();
thread02.start();
}
}
三、生產消費異步
1、流程描述
這裏基於Kafka中間件,演示流程消息生成,消息處理的異步解耦流程,基本步驟:
- 消息生成之後,寫入Kafka隊列 ;
- 消息處理方獲取消息后,進行流程處理;
- 消息在中間件提供的隊列中持久化存儲 ;
- 消息發起方如果掛掉,不影響消息處理 ;
- 消費方如果掛掉,不影響消息生成;
基於這種消息中間件模式,完成業務解耦,提高系統吞吐量,是架構中常用的方式。
2、流程實現案例
消息發送
@Service
public class KafkaAsyncServiceImpl implements KafkaAsyncService {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
@Override
public void sendMsg(String msg) {
// 這裏Topic如果不存在,會自動創建
kafkaTemplate.send("kafka-topic", msg);
}
}
消息消費
@Component
public class KafkaConsumer {
private static Logger LOGGER = LoggerFactory.getLogger(KafkaConsumer.class);
@KafkaListener(topics = "kafka-topic")
public void listenMsg (ConsumerRecord<?,String> record) {
String value = record.value();
LOGGER.info("KafkaConsumer01 ==>>"+value);
}
}
注意:這裏就算有多個消息消費方,也只會在一個消費方處理消息,這就是該模式的特點。
四、發布訂閱異步
1、流程描述
這裏基於Redis中間件,說明消息廣播模式流程,基本步驟:
- 提供一個消息傳遞頻道channel;
- 多個訂閱頻道的客戶端client;
- 消息通過PUBLISH命令發送給頻道channel ;
- 客戶端就會收到頻道中傳遞的消息 ;
之所以稱為廣播模式,該模式更注重通知下發,流程交互性不強。實際開發場景:運維總控系統,更新了某類服務配置,通知消息發送之後,相關業務線上的服務在拉取最新配置,更新到服務中。
2、流程實現案例
發送通知消息
@Service
public class RedisAsyncServiceImpl implements RedisAsyncService {
@Resource
private StringRedisTemplate stringRedisTemplate ;
@Override
public void sendMsg(String topic, String msg) {
stringRedisTemplate.convertAndSend(topic,msg);
}
}
客戶端接收
@Service
public class ReceiverServiceImpl implements ReceiverService {
private static final Logger LOGGER = LoggerFactory.getLogger("ReceiverMsg");
@Override
public void receiverMsg(String msg) {
LOGGER.info("Receiver01 收到消息:msg-{}",msg);
}
}
配置廣播模式
@Configuration
public class SubMsgConfig {
@Bean
RedisMessageListenerContainer container(RedisConnectionFactory factory,
MessageListenerAdapter msgListenerAdapter,
MessageListenerAdapter msgListenerAdapter02){
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(factory);
//註冊多個監聽,訂閱一個主題,實現消息廣播
container.addMessageListener(msgListenerAdapter, new PatternTopic("topic:msg"));
container.addMessageListener(msgListenerAdapter02, new PatternTopic("topic:msg"));
return container;
}
@Bean
MessageListenerAdapter msgListenerAdapter(ReceiverService receiverService){
return new MessageListenerAdapter(receiverService, "receiverMsg");
}
@Bean
MessageListenerAdapter msgListenerAdapter02(ReceiverService02 receiverService02){
return new MessageListenerAdapter(receiverService02, "receiverMsg");
}
@Bean
ReceiverService receiverService(){
return new ReceiverServiceImpl();
}
@Bean
ReceiverService02 receiverService02(){
return new ReceiverServiceImpl02();
}
}
這裏配置了多個訂閱的客戶端。
五、任務積壓監控
生成一個消息,就因為有一個處理該消息的任務要執行,這就導致任務可能出現積壓的情況,常見原因大致有如下幾個:
- 任務產生的服務過多,任務處理的服務過少,不均衡;
- 任務處理時間太長,也導致生產過剩;
- 中間件本身容量偏小,需要擴容或集群化管理;
如果任務積壓過多,可能要對任務生成進行流量控制,或者提升任務的處理能力,從而避免雪崩情況。
六、源代碼地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
推薦閱讀:《架構設計系列》,蘿蔔青菜,各有所需
| 序號 | 標題 |
|---|---|
| 01 | 架構設計:單服務.集群.分佈式,基本區別和聯繫 |
| 02 | 架構設計:分佈式業務系統中,全局ID生成策略 |
| 03 | 架構設計:分佈式系統調度,Zookeeper集群化管理 |
| 04 | 架構設計:接口冪等性原則,防重複提交Token管理 |
| 05 | 架構設計:緩存管理模式,監控和內存回收策略 |
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!