Why 紅黑樹
為什麼大家都這麼推崇紅黑樹呢? 這就是數據結構的魅力!!! 下面我簡述一下常用數據結構的優缺點
大家對數組很熟悉, 都知道對數組來說,它底層的存儲空間是連續的,因此如果我們根據index去獲取元素,速度是相當快, 但是對於數組來說有時候查詢也不見得就一定塊, 比如我們查詢數組中名字叫張三的人, 也不得不從開始遍歷這個數組
如果我們想往數組中插入一個元素, 也不見得一定就慢, 比如我們往數組中最後的位置插入就很快, 但是要是往開始的位置插入的話, 肯定會很慢, 需要將現有數組中所有的元素往後移動一位, 才能空出開始的位置,給新元素用
一說鏈式存儲, 大家也都知道, 這種數據結構僅僅是邏輯連續, 物理存儲不連續, 因此我們有可以通過玩指針或者引用很快的完成元素的刪除和添加
對鏈表的查詢來說, 一定是慢的, 無論查詢誰, 查哪個, 都得從第一個節點開始遍歷
AVL樹, 就是二叉平衡樹, 這種有序的樹形結果就將鏈式存儲添加刪除塊, 順序存儲的查找快兩大有點進行了一次中和, 在絕大部分情況下, AVL樹在增刪改查方面的性能都原超過數組和鏈表
紅黑樹是對AVL樹是又一次重大升級, AVL樹,對於樹的平衡要求太嚴格了, 每當添加,刪除節點時,都不得不進行調整
對於AVL樹個紅黑樹來說, 每次添加一個新的節點都是最多進行兩次旋轉(左旋右旋)就能重新使樹變的平衡,
但是當我們刪除一個恭弘=叶 恭弘子節點時, AVL樹重新調整成平衡狀態時最多需要進行旋轉O(logN)次, 而紅黑樹最多旋轉3次就能重新平衡,時間複雜度是O(1)
還有就是紅黑樹並不是完全意義上的AVL樹, 也就是說它其實並不是真的像AVL樹那樣嚴格要求對一個節點來說左右子樹的高度差不能超過1, 而是選擇使用染成紅色和黑色進行維護
簡單來說, 因為紅黑樹並不像AVL樹那樣完全平衡, 可能會導致紅黑樹的讀性能略遜於AVL, 但是紅黑樹的維護成本絕對是遠遠低於AVL, 在空間上的開銷和AVL樹基本持平, 因此紅黑樹被大家極力推崇, 和學習java的同學直接相關的就是jdk8的 hashmap
紅黑樹的特性
紅黑樹主要存在下面的7條性質
- 節點非紅即黑
- 根節點必定是黑色
- 恭弘=叶 恭弘子節點全部是黑色, (這裏說的恭弘=叶 恭弘子節點是我們想象在肉眼看到的節點上再多加一層子節點)
- 紅節點的子節點必定是黑色
- 紅節點的父節點必定是黑色
- 從根節點到任意子節點的路徑上,都要經歷相同數目的黑節點
- 從根節點到任意子節點的路徑上不可能存在兩個連續相同的紅節點
常見的誤區
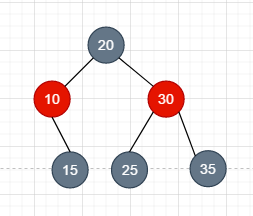
如上圖, 看着挺像紅黑樹, 其實他不是, 看它node10, 並不滿足上面的性質6. 因為我們認為node10的左子節點是黑色的節點, 這樣的話, 從node20到node10的左子節點就經歷了兩個黑節點, 而其他的 node15, node25, node35 經歷的黑色子節點數都是三個
如上圖它也不是紅黑樹, 因為我們認為node30的右節點是黑色的節點, 這樣的話從node60到node30的右節點就經歷了三個黑色的節點, 而其他的所有子節點都經歷了4個, 故, 他不是紅黑樹
紅黑樹與2-3-4樹等價
如上圖中,當我們將一個紅黑樹中的黑色節點和紅色節點融合在一起時,我們會發現, 這個紅黑樹其實就是一顆2-3-4樹, 一顆四階B樹
並且, 紅黑樹中黑色節點的每一個合併完成后的節點中都有一個黑色的節點, 換句話說就是紅黑樹中黑色節點的個數等於2-3-4樹中節點的個數
添加
添加節點其實就是構造紅黑樹的過程, 只要我們嚴格遵循上面的7條限制, 構造出來的樹就是紅黑樹
通過上圖其實我們發現, 紅黑樹真的可以和四階B樹之間進行等價代換, 換句話說就是 4階B樹的性質對於紅黑樹來書其實也是存在的, 主要是如下兩條性質
- 所有新添加進去的節點都被放在了恭弘=叶 恭弘子節點上
- 2-3-4樹中每一個節點中允許承載的元素的個數 [1,3]
經驗推薦: 就是新添加的節點盡量全部是紅色, 如果你畫一畫就會發現, 如果我們新添加的節點是紅色的話,上面所說的7條性質中, 除了第四條(紅節點的子節點必定的黑節點). 其他的限制都可以滿足
於是看一下一顆四階B樹插入節點時有哪些種情況
數一數: 一共 4+3+3+2 = 12種情況, 換句話說, 只要我們處理好了這12種情況, 我們就完成了添加節點的邏輯
- 情況1, 就是假設我們添加進去的是紅色的節點, 並且這個紅色節點的父節點是黑色節點時, 直接添加進行,不需要其他任何變換, 就想下圖這樣, 直接簡單粗暴的添加就行
除去第一種情況外, 還剩下8中情況出現了紅紅節點相鄰, 於是繼續往下看, 我們對他進行一次修復
插入的node57, node64, 什麼情況呢? 就是當前節點是node5556, 首先這個節點中現存兩個元素, 並且是往這個黑色的節點的左側的左側插入, 或者是右側的右側插入一個紅色節點
看上圖出現了兩個紅色節點相鄰,於是我們第一件事就是進行重新染色,
- 將插入節點的父節點染成黑色
- 將插入節點的祖父節點染成紅色
- 將祖父節點進行旋轉, 如果這個新節點被插入在父節點的右側. 左旋轉它的祖父節點
經過上面的變換后, 我們重新得到標準的紅黑樹如下
第三種情況和第二種情況相似, 還是插入 node57和node64. 判斷的條件是 插入節點的叔叔節點(父節點的兄弟節點)不是紅節點,
簡稱 LR , 或者是RL , 需要進行如下的調整
- 染色: 將自己染成黑色,祖節點染成紅色
- LR: 父節點左旋轉, 祖父節點右旋轉
- RL: 祖父點右旋轉, 父節點左旋轉
LR舉例:
經過上面的變化,我們重新得到平衡的紅黑樹
接着往下看剩下的四種情況
- 情況4: 新添加的節點的叔叔節點是紅色, 其實就是需要上溢的情況, 也很好處理
像上圖這樣, 新添加的紅色節點 node15, 它本身的父節點是node20, 父節點的叔叔節點是紅色的node25, 我們比較node15和node20的大小, 發現node15本來是應該放在node20的左邊的, 但是對於一顆2-3-4樹來說, 單個節點最多就有3個元素, 如果再加上node15 就會出現上溢的情況, 怎麼辦呢? 我們上溢調整, 選擇這個節點中間位置的元素向上和父節點合併, 選擇node20, node30其實都是可以的, 為了方便我們選擇node30
好,下面開始修復這個紅黑樹
- 將插入的節點的父節點和它的叔叔節點染成黑色
- 發生了上溢, 將他的父節點的染成紅色, 遞歸插入到根節點上, 這時候根節點可能又會發生上溢
然後上溢
當我們將新插入的節點的父節點node30染成紅色時, 再插入到根節點, 實際上就是重複我們枚舉出來的這12種情況中的一種. 紅黑樹一定會被修復, 當然這時候很可能會出現根節點也容納不了新的元素, 需要根節點也進行上溢, 然後將根節點染黑
還有一種情況是像下面這樣, 同樣是在情況4下的新插入的節點的叔叔節點是紅色
像下面這樣調整:
- 將父節點和叔叔節點染成黑色
- 祖父節點上溢
然後就是這種情況
調整的思路和前面一樣
- 將父節點和叔叔節點染成黑色
- 將祖父節點上溢
至此紅黑樹的添加的12種情況就全部枚舉完成了
刪除
對於刪除來說總共兩大種四小種情況
- 第一種就是刪除的節點就是紅色節點, 如果真是這樣的話,直接刪除就ok
- 第二種是刪除的節點是黑色節點
- 刪除擁有1個red節點的黑色節點
- 刪除擁有2個red節點的黑色節點,
- 刪除黑色節點
如果一個像下面這樣, 下面的黑色節點有兩個子節點, 這種情況下,黑色節點肯定不會直接被刪除的, 需要進行變換,讓他的恭弘=叶 恭弘子節點去替換他,進而實現刪除的目的
- 情況1: 刪除擁有1個紅節點的黑色節點,像下圖這樣
怎麼判斷這就是我們想刪除的情況呢? 當我們確定用來替代這個被刪除的黑節點是紅色,則符合當前的情況
也就是說我們想刪除 node40 和 node70, 於是我們這樣做
- 讓這個指向被刪除的節點的指針指向這個被刪除的節點的子節點
- 將替代它的節點染成黑色
於是我們接得到下圖這樣的結果
- 情況2: 刪除的節點是黑色的恭弘=叶 恭弘子節點, 並且可向兄弟節點借
首先,如果這個恭弘=叶 恭弘子節點就是根節點的話,直接刪除就ok
看下面的這個圖, 我們就刪除其中node90, 即,刪除黑色恭弘=叶 恭弘子節點
如果想刪除上圖中的node90也是由竅門的,規律和2-3-4樹是擦不多的
假設它就是2-3-4樹, 如果我們將node90刪了, 我們計算一下, 對於2-3-4樹來說, 每一個節點位置上至少有 ⌈ 4/2 ⌉ -1 = 1個元素, 但是把node90刪除了這個位置上的節點中沒有元素, 因此產生了 下溢
出現下溢,我們首先考慮的情況就是看看可不可以向它的兄弟節點借一個,但是和B樹是有取別的, 多了下面的限制
- 被刪除的這個節點的兄弟節點必須是黑色的
- 被刪除的這個節點的兄弟節點一定的有紅色的子節點才ok, 就像上圖那樣, 可以在左邊,右邊,或者都有
- 直接刪除掉指定的node(因為它在恭弘=叶 恭弘子節點的位置上)
- 進行旋轉,旋轉時注意, 兩點:第一點: 比如下面的原來根節點位置上的元素88是紅色的, 經過旋轉上來替換它的節點的顏色必須染成紅色, 如果node88是黑色, 那麼經過旋轉上來替換他的節點的顏色必須染成黑色 ,第二點: 旋轉完成后,新的跟節點的直接左右子節點的顏色轉換為黑色
怎麼進行旋轉呢? 就像下圖這樣
- 情況3: 刪除的節點是黑色的恭弘=叶 恭弘子節點, 並且它的兄弟是黑色,而且它的兄弟節點不能借給他元素
像這種情況:我像刪除node99,但是沒辦法像他的兄弟節點借元素,於是
- 將父節點向下合併,父節點染成黑色
- 將它的兄弟節點染成紅色
也有特殊的情況, 就是它的父節點只有一個,還是黑色
這時候,我們將他的父節點下溢, 原位置的節點捨棄
- 還有最後一種情況就是, 刪除的是黑色的節點, 它的兄弟節點的是紅色的節點
就像上圖那樣,我們想刪除node99, 但是node99的兄弟節點其實是node55, 而不是node77, 我們怎麼樣才能轉換為前面說的那些情況呢?
-
將被刪除節點的父節點染成紅色, 兄弟節點染黑
-
讓被刪除的父節點進行右旋轉(node88右轉)
得到下圖
於是我們就將這種兄弟節點為紅節點的情況轉化成了兄弟節點為黑色節點的樣子, 按照原來的方式進行刪除修整即可
- 讓原父節點下溢
- 原染成黑色
- 兄弟節點,染成紅色
至此本文就結束, 歡迎關注我,後續我更新更多的關於開發相關的筆記
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!