一 前期準備
1.1 基礎知識
Heketi提供了一個RESTful管理界面,可以用來管理GlusterFS卷的生命周期。Heketi會動態在集群內選擇bricks構建所需的volumes,從而確保數據的副本會分散到集群不同的故障域內。同時Heketi還支持任意數量的ClusterFS集群。
提示:本實驗基於glusterfs和Kubernetes分開部署,heketi管理glusterfs,Kubernetes使用heketi提供的API,從而實現glusterfs的永久存儲,,而非Kubernetes部署glusterfs。
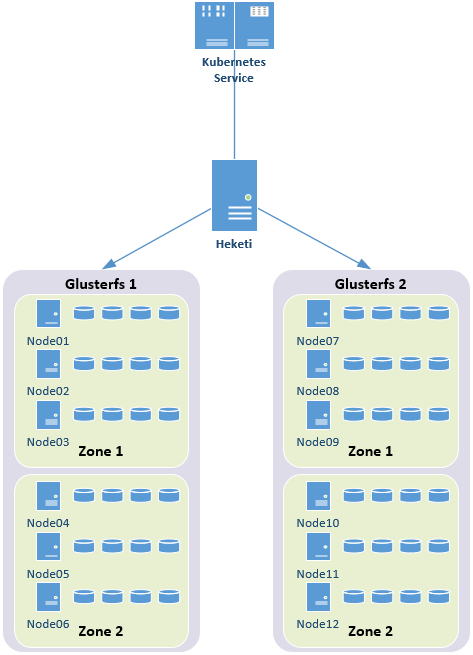
1.2 架構示意
提示:本實驗Heketi僅管理單zone的glusterfs集群。
1.3 相關規劃
| 主機 |
IP |
磁盤 |
備註 |
| servera |
172.24.8.41 |
sdb |
glusterfs節點 |
| serverb |
172.24.8.42 |
sdb |
glusterfs節點 |
| serverc |
172.24.8.43 |
sdb |
glusterfs節點 |
| heketi |
172.24.8.44 |
|
Heketi主機 |
|
servera |
serverb |
serverc |
| PV |
sdb1 |
sdb1 |
sdb1 |
| VG |
vg0 |
vg0 |
vg0 |
| LV |
datalv |
datalv |
datalv |
| bricks目錄 |
/bricks/data |
/bricks/data |
/bricks/data |
1.4 其他準備
所有節點NTP配置;
所有節點添加相應主機名解析:
172.24.8.41 servera
172.24.8.42 serverb
172.24.8.43 serverc
172.24.8.44 heketi
注意:若非必要,建議關閉防火牆和SELinux。
二 規劃相應存儲卷
2.1 劃分LVM
1 [root@servera ~]# fdisk /dev/sdb #創建lvm的sdb1,過程略
2 [root@servera ~]# pvcreate /dev/sdb1 #使用/dev/vdb1創建PV
3 [root@servera ~]# vgcreate vg0 /dev/sdb1 #創建vg
4 [root@servera ~]# lvcreate -L 15G -T vg0/thinpool #創建支持thin的lv池
5 [root@servera ~]# lvcreate -V 10G -T vg0/thinpool -n datalv #創建相應brick的lv
6 [root@servera ~]# vgdisplay #驗證確認vg信息
7 [root@servera ~]# pvdisplay #驗證確認pv信息
8 [root@servera ~]# lvdisplay #驗證確認lv信息
提示:serverb、serverc類似操作,根據規劃需求創建完所有基於LVM的brick。
三 安裝glusterfs
3.1 安裝相應RPM源
1 [root@servera ~]# yum -y install centos-release-gluster
提示:serverb、serverc、client類似操作,安裝相應glusterfs源;
安裝相應源之後,會在/etc/yum.repos.d/目錄多出文件CentOS-Storage-common.repo,內容如下:
1 # CentOS-Storage.repo
2 #
3 # Please see http://wiki.centos.org/SpecialInterestGroup/Storage for more
4 # information
5
6 [centos-storage-debuginfo]
7 name=CentOS-$releasever - Storage SIG - debuginfo
8 baseurl=http://debuginfo.centos.org/$contentdir/$releasever/storage/$basearch/
9 gpgcheck=1
10 enabled=0
11 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-SIG-Storage
3.2 安裝glusterfs
1 [root@servera ~]# yum -y install glusterfs-server
提示:serverb、serverc類似操作,安裝glusterfs服務端。
3.3 啟動glusterfs
1 [root@servera ~]# systemctl start glusterd
2 [root@servera ~]# systemctl enable glusterd
提示:serverb、serverc類似操作,所有節點啟動glusterfs服務端;
安裝完glusterfs之後建議exit退出終端重新登錄,從而可以補全glusterfs相關命令。
3.4 添加信任池
1 [root@servera ~]# gluster peer probe serverb
2 peer probe: success.
3 [root@servera ~]# gluster peer probe serverc
4 peer probe: success.
5 [root@servera ~]# gluster peer status #查看信任池狀態
6 [root@servera ~]# gluster pool list #查看信任池列表
提示:加信任池的操作,只需要在servera、serverb、serverc所有集群節點主機中的任意一台上面執行添加其他三個節點的操作即可。
提示:若未關閉防火牆,在添加信任池之前必須放通防火牆相應規則,操作如下:
1 [root@servera ~]# firewallcmd permanent addservice=glusterfs
2 [root@servera ~]# firewallcmd permanent addservice=nfs
3 [root@servera ~]# firewallcmd permanent addservice=rpcbind
4 [root@servera ~]# firewallcmd permanent addservice=mountd
5 [root@servera ~]# firewallcmd permanent addport=5666/tcp
6 [root@servera ~]# firewallcmd reload
四 部署Heketi
4.1 安裝heketi服務
1 [root@heketi ~]# yum -y install centos-release-gluster
2 [root@heketi ~]# yum -y install heketi heketi-client
4.2 配置heketi
1 [root@heketi ~]# vi /etc/heketi/heketi.json
2 {
3 "_port_comment": "Heketi Server Port Number",
4 "port": "8080", #默認端口
5
6 "_use_auth": "Enable JWT authorization. Please enable for deployment",
7 "use_auth": true, #基於安全考慮開啟認證
8
9 "_jwt": "Private keys for access",
10 "jwt": {
11 "_admin": "Admin has access to all APIs",
12 "admin": {
13 "key": "admin123" #管理員密碼
14 },
15 "_user": "User only has access to /volumes endpoint",
16 "user": {
17 "key": "xianghy" #普通用戶
18 }
19 },
20
21 "_glusterfs_comment": "GlusterFS Configuration",
22 "glusterfs": {
23 "_executor_comment": [
24 "Execute plugin. Possible choices: mock, ssh",
25 "mock: This setting is used for testing and development.", #用於測試
26 " It will not send commands to any node.",
27 "ssh: This setting will notify Heketi to ssh to the nodes.", #ssh方式
28 " It will need the values in sshexec to be configured.",
29 "kubernetes: Communicate with GlusterFS containers over", #在GlusterFS由kubernetes創建時採用
30 " Kubernetes exec api."
31 ],
32 "executor": "ssh",
33
34 "_sshexec_comment": "SSH username and private key file information",
35 "sshexec": {
36 "keyfile": "/etc/heketi/heketi_key",
37 "user": "root",
38 "port": "22",
39 "fstab": "/etc/fstab"
40 },
41 ……
42 ……
43 "loglevel" : "warning"
44 }
45 }
4.3 配置免秘鑰
1 [root@heketi ~]# ssh-keygen -t rsa -q -f /etc/heketi/heketi_key -N ""
2 [root@heketi ~]# chown heketi:heketi /etc/heketi/heketi_key
3 [root@heketi ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@servera
4 [root@heketi ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@serverb
5 [root@heketi ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@serverc
4.4 啟動heketi
1 [root@heketi ~]# systemctl enable heketi.service
2 [root@heketi ~]# systemctl start heketi.service
3 [root@heketi ~]# systemctl status heketi.service
4 [root@heketi ~]# curl http://localhost:8080/hello #測試訪問
5 Hello from Heketi
4.5 配置Heketi拓撲
拓撲信息用於讓Heketi確認可以使用的存儲節點、磁盤和集群,必須自行確定節點的故障域。故障域是賦予一組節點的整數值,這組節點共享相同的交換機、電源或其他任何會導致它們同時失效的組件。必須確認哪些節點構成一個集群,Heketi使用這些信息來確保跨故障域中創建副本,從而提供數據冗餘能力,Heketi支持多個Gluster存儲集群。
配置Heketi拓撲注意以下幾點:
- 可以通過topology.json文件定義組建的GlusterFS集群;
- topology指定了層級關係:clusters –> nodes –> node/devices –> hostnames/zone;
- node/hostnames字段的manage建議填寫主機ip,指管理通道,注意當heketi服務器不能通過hostname訪問GlusterFS節點時不能填寫hostname;
- node/hostnames字段的storage建議填寫主機ip,指存儲數據通道,與manage可以不一樣,生產環境管理網絡和存儲網絡建議分離;
- node/zone字段指定了node所處的故障域,heketi通過跨故障域創建副本,提高數據高可用性質,如可以通過rack的不同區分zone值,創建跨機架的故障域;
- devices字段指定GlusterFS各節點的盤符(可以是多塊盤),必須是未創建文件系統的裸設備。
1 [root@heketi ~]# vi /etc/heketi/topology.json
2 {
3 "clusters": [
4 {
5 "nodes": [
6 {
7 "node": {
8 "hostnames": {
9 "manage": [
10 "172.24.8.41"
11 ],
12 "storage": [
13 "172.24.8.41"
14 ]
15 },
16 "zone": 1
17 },
18 "devices": [
19 "/dev/mapper/vg0-datalv"
20 ]
21 },
22 {
23 "node": {
24 "hostnames": {
25 "manage": [
26 "172.24.8.42"
27 ],
28 "storage": [
29 "172.24.8.42"
30 ]
31 },
32 "zone": 1
33 },
34 "devices": [
35 "/dev/mapper/vg0-datalv"
36 ]
37 },
38 {
39 "node": {
40 "hostnames": {
41 "manage": [
42 "172.24.8.43"
43 ],
44 "storage": [
45 "172.24.8.43"
46 ]
47 },
48 "zone": 1
49 },
50 "devices": [
51 "/dev/mapper/vg0-datalv"
52 ]
53 }
54 ]
55 }
56 ]
57 }
58
59 [root@heketi ~]# echo "export HEKETI_CLI_SERVER=http://heketi:8080" >> /etc/profile.d/heketi.sh
60 [root@heketi ~]# echo "alias heketi-cli='heketi-cli --user admin --secret admin123'" >> .bashrc
61 [root@heketi ~]# source /etc/profile.d/heketi.sh
62 [root@heketi ~]# source .bashrc
63 [root@heketi ~]# echo $HEKETI_CLI_SERVER
64 http://heketi:8080
65 [root@heketi ~]# heketi-cli --server $HEKETI_CLI_SERVER --user admin --secret admin123 topology load --json=/etc/heketi/topology.json
4.6 集群管理
1 [root@heketi ~]# heketi-cli cluster list #集群列表
2 [root@heketi ~]# heketi-cli cluster info aa83b0045fafa362bfc7a8bfee0c24ad #集群詳細信息
3 Cluster id: aa83b0045fafa362bfc7a8bfee0c24ad
4 Nodes:
5 189ee41572ebf0bf1e297de2302cfb39
6 46429de5666fc4c6cc570da4b100465d
7 be0209387384299db34aaf8377c3964c
8 Volumes:
9
10 Block: true
11
12 File: true
13 [root@heketi ~]# heketi-cli topology info aa83b0045fafa362bfc7a8bfee0c24ad #查看拓撲信息
1 [root@heketi ~]# heketi-cli node list #卷信息
2 Id:189ee41572ebf0bf1e297de2302cfb39 Cluster:aa83b0045fafa362bfc7a8bfee0c24ad
3 Id:46429de5666fc4c6cc570da4b100465d Cluster:aa83b0045fafa362bfc7a8bfee0c24ad
4 Id:be0209387384299db34aaf8377c3964c Cluster:aa83b0045fafa362bfc7a8bfee0c24ad
5 [root@heketi ~]# heketi-cli node info 189ee41572ebf0bf1e297de2302cfb39 #節點信息
6 [root@heketi ~]# heketi-cli volume create --size=2 --replica=2 #默認為3副本的replica模式
1 [root@heketi ~]# heketi-cli volume list #卷信息
2 [root@heketi ~]# heketi-cli volume info 7da55685ebeeaaca60708cd797a5e391
3 [root@servera ~]# gluster volume info #通過glusterfs節點查看
4.7 測試驗證
1 [root@heketi ~]# yum -y install centos-release-gluster
2 [root@heketi ~]# yum -y install glusterfs-fuse #安裝glusterfs-fuse
3 [root@heketi ~]# mount -t glusterfs 172.24.8.41:vol_7da55685ebeeaaca60708cd797a5e391 /mnt
1 [root@heketi ~]# umount /mnt
2 [root@heketi ~]# heketi-cli volume delete 7da55685ebeeaaca60708cd797a5e391 #驗證完畢刪除
參考:https://www.jianshu.com/p/1069ddaaea78
https://www.cnblogs.com/panwenbin-logs/p/10231859.html
五 Kubernetes動態掛載glusterfs
5.1 StorageClass動態存儲
kubernetes共享存儲provider模式:
靜態模式(Static):集群管理員手工創建PV,在定義PV時設置後端存儲的特性;
動態模式(Dynamic):集群管理員不需要手工創建PV,而是通過StorageClass的設置對後端存儲進行描述,標記為某種”類型(Class)”;此時要求PVC對存儲的類型進行說明,系統將自動完成PV的創建及與PVC的綁定;PVC可以聲明Class為””,說明PVC禁止使用動態模式。
基於StorageClass的動態存儲供應整體過程如下圖所示:
- 集群管理員預先創建存儲類(StorageClass);
- 用戶創建使用存儲類的持久化存儲聲明(PVC:PersistentVolumeClaim);
- 存儲持久化聲明通知系統,它需要一個持久化存儲(PV: PersistentVolume);
- 系統讀取存儲類的信息;
- 系統基於存儲類的信息,在後台自動創建PVC需要的PV;
- 用戶創建一個使用PVC的Pod;
- Pod中的應用通過PVC進行數據的持久化;
- 而PVC使用PV進行數據的最終持久化處理。
提示:關於Kubernetes的部署參考《附003.Kubeadm部署Kubernetes》。
5.2 定義StorageClass
關鍵字說明:
- provisioner:表示存儲分配器,需要根據後端存儲的不同而變更;
- reclaimPolicy: 默認即”Delete”,刪除pvc后,相應的pv及後端的volume,brick(lvm)等一起刪除;設置為”Retain”時則保留數據,若需刪除則需要手工處理;
- resturl:heketi API服務提供的url;
- restauthenabled:可選參數,默認值為”false”,heketi服務開啟認證時必須設置為”true”;
- restuser:可選參數,開啟認證時設置相應用戶名;
- secretNamespace:可選參數,開啟認證時可以設置為使用持久化存儲的namespace;
- secretName:可選參數,開啟認證時,需要將heketi服務的認證密碼保存在secret資源中;
- clusterid:可選參數,指定集群id,也可以是1個clusterid列表,格式為”id1,id2”;
- volumetype:可選參數,設置卷類型及其參數,如果未分配卷類型,則有分配器決定卷類型;如”volumetype: replicate:3”表示3副本的replicate卷,”volumetype: disperse:4:2”表示disperse卷,其中‘4’是數據,’2’是冗餘校驗,”volumetype: none”表示distribute卷
提示:關於glusterfs各種不同類型的卷見《004.RHGS-創建volume》。
1 [root@k8smaster01 ~]# kubectl create ns heketi #創建命名空間
2 [root@k8smaster01 ~]# echo -n "admin123" | base64 #將密碼轉換為64位編碼
3 YWRtaW4xMjM=
4 [root@k8smaster01 ~]# mkdir -p heketi
5 [root@k8smaster01 ~]# cd heketi/
6 [root@k8smaster01 ~]# vi heketi-secret.yaml #創建用於保存密碼的secret
7 apiVersion: v1
8 kind: Secret
9 metadata:
10 name: heketi-secret
11 namespace: heketi
12 data:
13 # base64 encoded password. E.g.: echo -n "mypassword" | base64
14 key: YWRtaW4xMjM=
15 type: kubernetes.io/glusterfs
16 [root@k8smaster01 heketi]# kubectl create -f heketi-secret.yaml #創建heketi
17 [root@k8smaster01 heketi]# kubectl get secrets -n heketi
18 NAME TYPE DATA AGE
19 default-token-5sn5d kubernetes.io/service-account-token 3 43s
20 heketi-secret kubernetes.io/glusterfs 1 5s
21 [root@kubenode1 heketi]# vim gluster-heketi-storageclass.yaml #正式創建StorageClass
22 apiVersion: storage.k8s.io/v1
23 kind: StorageClass
24 metadata:
25 name: gluster-heketi-storageclass
26 parameters:
27 resturl: "http://172.24.8.44:8080"
28 clusterid: "aa83b0045fafa362bfc7a8bfee0c24ad"
29 restauthenabled: "true" #若heketi開啟認證此處也必須開啟auth認證
30 restuser: "admin"
31 secretName: "heketi-secret" #name/namespace與secret資源中定義一致
32 secretNamespace: "heketi"
33 volumetype: "replicate:3"
34 provisioner: kubernetes.io/glusterfs
35 reclaimPolicy: Delete
36 [root@k8smaster01 heketi]# kubectl create -f gluster-heketi-storageclass.yaml
注意:storageclass資源創建后不可變更,如修改只能刪除后重建。
1 [root@k8smaster01 heketi]# kubectl get storageclasses #查看確認
2 NAME PROVISIONER AGE
3 gluster-heketi-storageclass kubernetes.io/glusterfs 85s
4 [root@k8smaster01 heketi]# kubectl describe storageclasses gluster-heketi-storageclass
5.3 定義PVC
1 [root@k8smaster01 heketi]# cat gluster-heketi-pvc.yaml
2 apiVersion: v1
3 metadata:
4 name: gluster-heketi-pvc
5 annotations:
6 volume.beta.kubernetes.io/storage-class: gluster-heketi-storageclass
7 spec:
8 accessModes:
9 - ReadWriteOnce
10 resources:
11 requests:
12 storage: 1Gi
注意:accessModes可有如下簡寫:
- ReadWriteOnce:簡寫RWO,讀寫權限,且只能被單個node掛載;
- ReadOnlyMany:簡寫ROX,只讀權限,允許被多個node掛載;
- ReadWriteMany:簡寫RWX,讀寫權限,允許被多個node掛載。
1 [root@k8smaster01 heketi]# kubectl create -f gluster-heketi-pvc.yaml
2 [root@k8smaster01 heketi]# kubectl get pvc
3 [root@k8smaster01 heketi]# kubectl describe pvc gluster-heketi-pvc
4 [root@k8smaster01 heketi]# kubectl get pv
5 [root@k8smaster01 heketi]# kubectl describe pv pvc-5f7420ef-082d-11ea-badf-000c29fa7a79
1 [root@k8smaster01 heketi]# kubectl describe endpoints glusterfs-dynamic-5f7420ef-082d-11ea-badf-000c29fa7a79
提示:由上可知:PVC狀態為Bound,Capacity為1G。查看PV詳細信息,除容量,引用storageclass信息,狀態,回收策略等外,同時可知GlusterFS的Endpoint與path。EndpointsName為固定格式:glusterfs-dynamic-PV_NAME,且endpoints資源中指定了掛載存儲時的具體地址。
5.4 確認查看
通過5.3所創建的信息:
- volume與brick已經創建;
- 主掛載點(通信)在172.24.8.41節點,其餘兩個節點備選;
- 三副本的情況下,所有節點都會創建brick。
1 [root@heketi ~]# heketi-cli topology info #heketi主機查看
2 [root@serverb ~]# lsblk #glusterfs節點查看
3 [root@serverb ~]# df -hT #glusterfs節點查看
4 [root@servera ~]# gluster volume list #glusterfs節點查看
5 [root@servera ~]# gluster volume info vol_e4c948687239df9833748d081ddb6fd5
5.5 Pod掛載測試
1 [root@xxx ~]# yum -y install centos-release-gluster
2 [root@xxx ~]# yum -y install glusterfs-fuse #安裝glusterfs-fuse
提示:所有需要使用glusterfs volume的Kubernetes節點都必須安裝glusterfs-fuse以便於正常掛載,同時版本需要和glusterfs節點一致。
1 [root@k8smaster01 heketi]# vi gluster-heketi-pod.yaml
2 kind: Pod
3 apiVersion: v1
4 metadata:
5 name: gluster-heketi-pod
6 spec:
7 containers:
8 - name: gluster-heketi-container
9 image: busybox
10 command:
11 - sleep
12 - "3600"
13 volumeMounts:
14 - name: gluster-heketi-volume #必須和volumes中name一致
15 mountPath: "/pv-data"
16 readOnly: false
17 volumes:
18 - name: gluster-heketi-volume
19 persistentVolumeClaim:
20 claimName: gluster-heketi-pvc #必須和5.3創建的PVC中的name一致
21 [root@k8smaster01 heketi]# kubectl create -f gluster-heketi-pod.yaml -n heketi #創建Pod
5.6 確認驗證
1 [root@k8smaster01 heketi]# kubectl get pod -n heketi | grep gluster
2 gluster-heketi-pod 1/1 Running 0 2m43s
3 [root@k8smaster01 heketi]# kubectl exec -it gluster-heketi-pod /bin/sh #進入Pod寫入測試文件
4 / # cd /pv-data/
5 /pv-data # echo "This is a file!" >> a.txt
6 /pv-data # echo "This is b file!" >> b.txt
7 /pv-data # ls
8 a.txt b.txt
9 [root@servera ~]# df -hT #在glusterfs節點查看Kubernetes節點的測試文件
10 [root@servera ~]# cd /var/lib/heketi/mounts/vg_47c90d90e03de79696f90bd94cfccdde/brick_721243c3e0cf8a2372f05d5085a4338c/brick/
11 [root@servera brick]# ls
12 [root@servera brick]# cat a.txt
13 [root@servera brick]# cat b.txt
5.7 刪除資源
1 [root@k8smaster01 heketi]# kubectl delete -f gluster-heketi-pod.yaml
2 [root@k8smaster01 heketi]# kubectl delete -f gluster-heketi-pvc.yaml
3 [root@k8smaster01 heketi]# kubectl get pvc
4 [root@k8smaster01 heketi]# kubectl get pv
5 [root@servera ~]# gluster volume list
6 No volumes present in cluster
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選