日常開發,運維中,經常會出現誤刪數據的情況。誤刪數據的類型大致可分為以下幾類:
- 使用 delete 誤刪行
- 使用 drop table 或 truncate table 誤刪表
- 使用 drop database 語句誤刪數據庫
- 使用 rm 命令誤刪整個 MySQL 實例。
不同的情況,都會有其優先的解決方案:
- 針對誤刪行,可以通過 Flashback 工具將數據恢復
- 針對誤刪表或庫,一般採用通過 BINLOG 將數據恢復。
- 而對於誤刪 MySQL 實例,則需要我們搭建 HA 的 MySQL 集群,並保證我們的數據跨機房,跨城市保存。
本篇主要討論的內容是誤刪表或者庫,會先介紹有關 BINLOG 的操作命令,然後會對誤刪表的這種情況進行實際的模擬。
BINLOG 常見操作命令
BINLOG 的查詢方式一般分為兩種,一種是進入 MySQL 控制台進行查詢,另一種是通過 MySQL 提供的工具 mysqlbinlog 進行查詢,兩者的不同會在下面介紹。
通過 MySQL Cli 查詢 BINLOG 信息
在 cli 中,常見的命令如下:
# 查詢 BINLOG 格式
show VARIABLES like 'binlog_format';
# 查詢 BINLOG 位置
show VARIABLES like 'datadir';
# 查詢當前數據庫中 BINLOG 名稱及大小
show binary logs;
# 查看 master 正在寫入的 BINLOG 信息
show master status\G;
# 通過 offset 查看 BINLOG 信息
show BINLOG events in 'mysql-bin.000034' limit 9000, 10;
# 通過 position 查看 binlog 信息
show BINLOG events in 'mysql-bin.000034' from 1742635 limit 10;
使用 show BINLOG events 的問題:
- 使用該命令時,如果當前 binlog 文件很大,而且沒有指定
limit,會引發對資源的過度消耗。因為 MySQL 客戶端需要將 binlog 的全部內容處理,返回並显示出來。為了防止這種情況,mysqlbinlog 工具是一個很好的選擇。
通過 mysqlbinlog 查詢 BINLOG 信息
在介紹 mysqlbinlog 工具使用前,先來看下 BINLOG 文件的內容:
# 查詢 BINLOG 的信息
mysqlbinlog --no-defaults mysql-bin.000034 | less
# at 141
#100309 9:28:36 server id 123 end_log_pos 245
Query thread_id=3350 exec_time=11 error_code=0
at 表示 offset 或者說事件開始的起始位置100309 9:28:36 server id 123 表示 server 123 開始執行事件的日期end_log_pos 245 表示事件的結束位置 + 1,或者說是下一個事件的起始位置。exec_time 表示在 master 上花費的時間,在 salve 上,記錄的時間是從 Master 記錄開始,一直到 Slave 結束完成所花費的時間。rror_code=0 表示沒有錯誤發生。
在大致了解 binlog 的內容后,mysqlbinlog 的用途有哪些?:
- mysqlbinlog 可以作為代替 cli 讀取 binlog 的工具。
- mysqlbinlog 可以將執行過的 SQL 語句輸出,用於數據的恢復或備份。
查詢 BINLOG 日誌:
# 查詢規定時候后發生的 BINLOG 日誌
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-datetime "2019-11-22 14:00:00" --database sync_test mysql-bin.000034 | less
導出 BINLOG 日誌,用於分析和排查 sql 語句:
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-datetime "2019-11-22 14:00:00" --database sync_test mysql-bin.000034 > /home/mysql_backup/binlog_raw.sql
導入 BINLOG 日誌
# 通過 BINLOG 進行恢復。
mysqlbinlog --start-position=1038 --stop-position=1164 --database=db_name mysql-bin.000034 | mysql -u cisco -p db_name
# 通過 BINLOG 導出的 sql 進行恢復。
mysql -u cisco -p db_name < binlog_raw.sql.sql
mysqlbinlog 的常用參數:
--database 僅僅列出配置的數據庫信息--no-defaults 讀取沒有選項的文件, 指定的原因是由於 mysqlbinlog 無法識別 BINLOG 中的 default-character-set=utf8 指令--offset 跳過 log 中 N 個條目--verbose 將日誌信息重建為原始的 SQL 陳述。
-v 僅僅解釋行信息-vv 不但解釋行信息,還將 SQL 列類型的註釋信息也解析出來
--start-datetime 显示從指定的時間或之後的時間的事件。
- 接收
DATETIME 或者 TIMESTRAMP 格式。
--base64-output=decode-rows 將 BINLOG 語句中事件以 base-64 的編碼显示,對一些二進制的內容進行屏蔽。
AUTO 默認參數,自動显示 BINLOG 中的必要的語句NEVER 不會显示任何的 BINLOG 語句,如果遇到必須显示的 BINLOG 語言,則會報錯退出。DECODE-ROWS 显示通過 -v 显示出來的 SQL 信息,過濾到一些 BINLOG 二進制數據。
MySQL Cli 和 mysqlbinlog 工具之間的比較
如果想知道當前 MySQL 中正在寫入的 BINLOG 的名稱,大小等基本信息時,可以通過 Cli 相關的命令來查詢。
但想查詢,定位,恢復 BINLOG 中具體的數據時,要通過 mysqlbinlog 工具,因為相較於 Cli 來說,mysqlbinlog 提供了 --start-datetime,--stop-position 等這樣更為豐富的參數供我們選擇。這時 Cli 中 SHOW BINLOG EVENTS 的簡要語法就變得相形見絀了。
使用 BINLOG 恢複數據
恢復的大致流程如下:
- 會創建數據庫和表,並插入數據。
- 誤刪一條數據。
- 繼續插入數據。
- 誤刪表。
- 最後將原來以及之後插入的數據進行恢復。
準備數據
準備數據庫,表及數據:
# 創建臨時數據庫
CREATE DATABASE IF NOT EXISTS test_binlog default charset utf8 COLLATE utf8_general_ci;
# 創建臨時表
CREATE TABLE `sync_test` (`id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 添加數據
insert into sync_test (id, name) values (null, 'xiaoa');
insert into sync_test (id, name) values (null, 'xiaob');
insert into sync_test (id, name) values (null, 'xiaoc');
# 查看添加的數據
select * from sync_test;
刪除表或者數據
誤刪操作:
# 刪除 name=xiaob 的數據
delete from sync_test where id=3
# 插入幾條數據
insert into sync_test (id, name) values (null, 'xiaod');
insert into sync_test (id, name) values (null, 'xiaoe');
insert into sync_test (id, name) values (null, 'xiaof');
# 刪除表
DROP TABLE sync_test;
數據的恢復
在執行數據恢復前,如果操作的是生產環境,會有如下的建議:
- 使用
flush logs 命令,替換當前主庫中正在使用的 binlog 文件,好處如下:
- 可將誤刪操作,定位在一個 BINLOG 文件中,便於之后的數據分析和恢復。
- 避免操作正在被使用的 BINLOG 文件,防止發生意外情況。
- 數據的恢復不要在生產庫中執行,先在臨時庫恢復,確認無誤后,再倒回生產庫。防止對數據的二次傷害。
通常來說,恢復主要有兩個步驟:
- 在臨時庫中,恢復定期執行的全量備份數據。
- 然後基於全量備份的數據點,通過 BINLOG 來恢復誤操作和正常的數據。
使用 BINLOG 做數據恢復前:
# 查看正在使用的 Binlog 文件
show master status\G;
# 显示結果是: mysql-bin.000034
# 執行 flush logs 操作,生成新的 BINLOG
flush logs;
# 查看正在使用的 Binlog 文件
show master status\G;
# 結果是:mysql-bin.000035
確定恢複數據的步驟:
這裏主要是有兩條誤刪的操作,數據行的誤刪和表的誤刪。有兩種方式進行恢復。
- 方式一:首先恢復到刪除表操作之前的位置,然後再單獨恢復誤刪的數據行。
- 方式二:首先恢復到誤刪數據行的之前的位置,然後跳過誤刪事件再恢複數據表操作之前的位置。
這裏採用方式一的方案進行演示,由於是演示,就不額外找一個臨時庫進行全量恢復了,直接進行操作。
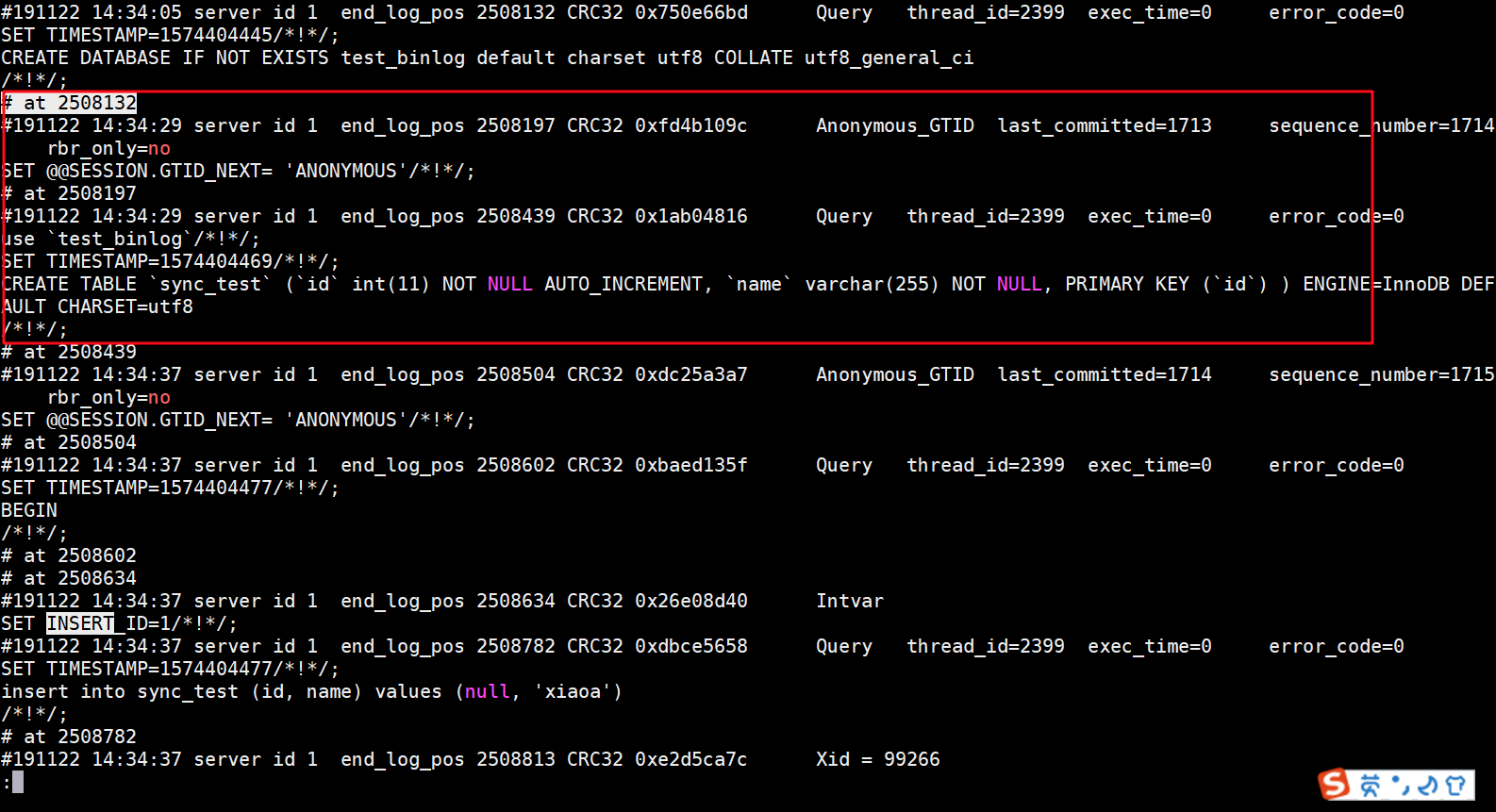
查詢創建表的事件位置和刪除表的事件位置
# 根據時間確定位置信息
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-datetime "2019-11-22 14:00:00" --database test_binlog mysql-bin.000034 | less
創建表的開始位置:
刪除表的結束位置:
插入 name=’xiaob’ 的位置:
# 根據位置導出 SQL 文件
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-position "2508132" --stop-position "2511004" --database test_binlog mysql-bin.000034 > /home/mysql_backup/test_binlog_step1.sql
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-position "2508813" --stop-position "2509187" --database test_binlog mysql-bin.000034 > /home/mysql_backup/test_binlog_step2.sql
# 使用 mysql 進行恢復
mysql -u cisco -p < /home/mysql_backup/test_binlog_step1.sql
mysql -u cisco -p < /home/mysql_backup/test_binlog_step2.sql
MySQL 5.7 中無論是否打開 GTID 的配置,在每次事務開啟時,都首先會出 GTID 的一個事務,用於并行複製。所以在確定導出開始事務位置時,要算上這個事件。
在使用 –stop-position 導出時,會導出在指定位置的前一個事件,所以這裏要推后一個事務。
對於 DML 的語句,主要結束位置要算上 COMMIT 的位置。
總結
在文章開始時,我們熟悉了操作 BINLOG 的兩種方式 CLI 和 mysqlbinlog 工具,接着介紹了其間的區別和使用場景,對於一些大型的 BINLOG 文件,使用 mysqlbinlog 會更加的方便和效率。並對 mysqlbinlog 的一些常見參數進行了介紹。
接着通過使用 mysqlbinlog 實際模擬了數據恢復的過程,並在恢複數據時,提出了一些需要注意的事項,比如 flush logs 等。
最後在恢複數據時,要注意 start-position 和 end-position 的一些小細節,來保證找到合適的位置。
參考
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!