Spring Boot 中的數據持久化方案前面給大夥介紹了兩種了,一個是 JdbcTemplate,還有一個 MyBatis,JdbcTemplate 配置簡單,使用也簡單,但是功能也非常有限,MyBatis 則比較靈活,功能也很強大,據我所知,公司採用 MyBatis 做數據持久化的相當多,但是 MyBatis 並不是唯一的解決方案,除了 MyBatis 之外,還有另外一個東西,那就是 Jpa,松哥也有一些朋友在公司里使用 Jpa 來做數據持久化,本文就和大夥來說說 Jpa 如何實現數據持久化。
Jpa 介紹
首先需要向大夥介紹一下 Jpa,Jpa(Java Persistence API)Java 持久化 API,它是一套 ORM 規範,而不是具體的實現,Jpa 的江湖地位類似於 JDBC,只提供規範,所有的數據庫廠商提供實現(即具體的數據庫驅動),Java 領域,小夥伴們熟知的 ORM 框架可能主要是 Hibernate,實際上,除了 Hibernate 之外,還有很多其他的 ORM 框架,例如:
- Batoo JPA
- DataNucleus (formerly JPOX)
- EclipseLink (formerly Oracle TopLink)
- IBM, for WebSphere Application Server
- JBoss with Hibernate
- Kundera
- ObjectDB
- OpenJPA
- OrientDB from Orient Technologies
- Versant Corporation JPA (not relational, object database)
Hibernate 只是 ORM 框架的一種,上面列出來的 ORM 框架都是支持 JPA2.0 規範的 ORM 框架。既然它是一個規範,不是具體的實現,那麼必然就不能直接使用(類似於 JDBC 不能直接使用,必須要加了驅動才能用),我們使用的是具體的實現,在這裏我們採用的實現實際上還是 Hibernate。
Spring Boot 中使用的 Jpa 實際上是 Spring Data Jpa,Spring Data 是 Spring 家族的一個子項目,用於簡化 SQL、NoSQL 的訪問,在 Spring Data 中,只要你的方法名稱符合規範,它就知道你想幹嘛,不需要自己再去寫 SQL。
關於 Spring Data Jpa 的具體情況,大家可以參考
工程創建
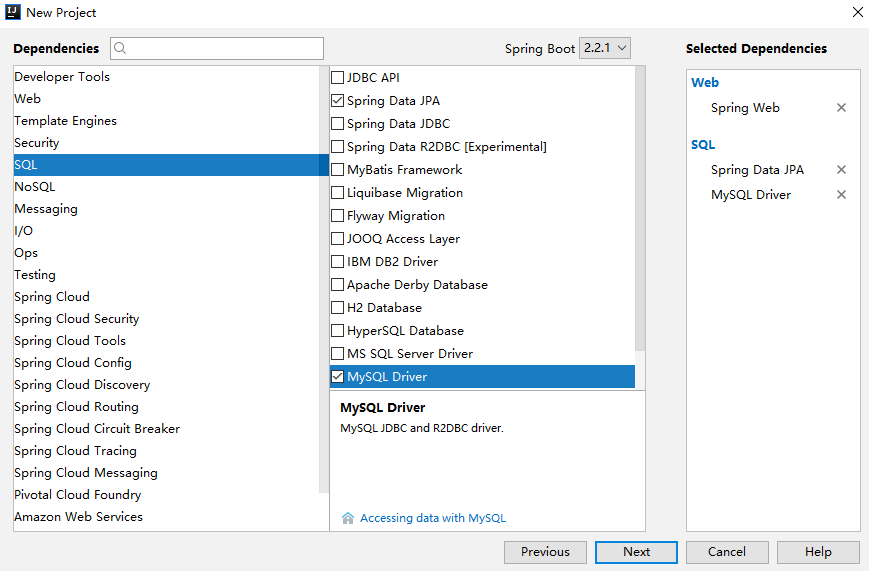
創建 Spring Boot 工程,添加 Web、Jpa 以及 MySQL 驅動依賴,如下:
工程創建好之後,添加 Druid 依賴,完整的依賴如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.28</version>
<scope>runtime</scope>
</dependency>
如此,工程就算創建成功了。
基本配置
工程創建完成后,只需要在 application.properties 中進行數據庫基本信息配置以及 Jpa 基本配置,如下:
# 數據庫的基本配置
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.url=jdbc:mysql:///test01?useUnicode=true&characterEncoding=UTF-8
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
# JPA配置
spring.jpa.database=mysql
# 在控制台打印SQL
spring.jpa.show-sql=true
# 數據庫平台
spring.jpa.database-platform=mysql
# 每次啟動項目時,數據庫初始化策略
spring.jpa.hibernate.ddl-auto=update
# 指定默認的存儲引擎為InnoDB
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
注意這裏和 JdbcTemplate 以及 MyBatis 比起來,多了 Jpa 配置,Jpa 配置含義我都註釋在代碼中了,這裏不再贅述,需要強調的是,最後一行配置,默認情況下,自動創建表的時候會使用 MyISAM 做表的引擎,如果配置了數據庫方言為 MySQL57Dialect,則使用 InnoDB 做表的引擎。
好了,配置完成后,我們的 Jpa 差不多就可以開始用了。
基本用法
ORM(Object Relational Mapping) 框架表示對象關係映射,使用 ORM 框架我們不必再去創建表,框架會自動根據當前項目中的實體類創建相應的數據表。因此,我這裏首先創建一個 User 對象,如下:
@Entity(name = "t_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "name")
private String username;
private String address;
//省略getter/setter
}
首先 @Entity 註解表示這是一個實體類,那麼在項目啟動時會自動針對該類生成一張表,默認的表名為類名,@Entity 註解的 name 屬性表示自定義生成的表名。@Id 註解表示這個字段是一個 id,@GeneratedValue 註解表示主鍵的自增長策略,對於類中的其他屬性,默認都會根據屬性名在表中生成相應的字段,字段名和屬性名相同,如果開發者想要對字段進行定製,可以使用 @Column 註解,去配置字段的名稱,長度,是否為空等等。
做完這一切之後,啟動 Spring Boot 項目,就會發現數據庫中多了一個名為 t_user 的表了。
針對該表的操作,則需要我們提供一個 Repository,如下:
public interface UserDao extends JpaRepository<User,Integer> {
List<User> getUserByAddressEqualsAndIdLessThanEqual(String address, Integer id);
@Query(value = "select * from t_user where id=(select max(id) from t_user)",nativeQuery = true)
User maxIdUser();
}
這裏,自定義 UserDao 接口繼承自 JpaRepository,JpaRepository 提供了一些基本的數據操作方法,例如保存,更新,刪除,分頁查詢等,開發者也可以在接口中自己聲明相關的方法,只需要方法名稱符合規範即可,在 Spring Data 中,只要按照既定的規範命名方法,Spring Data Jpa 就知道你想幹嘛,這樣就不用寫 SQL 了,那麼規範是什麼呢?參考下圖:
當然,這種方法命名主要是針對查詢,但是一些特殊需求,可能並不能通過這種方式解決,例如想要查詢 id 最大的用戶,這時就需要開發者自定義查詢 SQL 了。
如上代碼所示,自定義查詢 SQL,使用 @Query 註解,在註解中寫自己的 SQL,默認使用的查詢語言不是 SQL,而是 JPQL,這是一種數據庫平台無關的面向對象的查詢語言,有點定位類似於 Hibernate 中的 HQL,在 @Query 註解中設置 nativeQuery 屬性為 true 則表示使用原生查詢,即大夥所熟悉的 SQL。上面代碼中的只是一個很簡單的例子,還有其他一些點,例如如果這個方法中的 SQL 涉及到數據操作,則需要使用 @Modifying 註解。
好了,定義完 Dao 之後,接下來就可以將 UserDao 注入到 Controller 中進行測試了(這裏為了省事,就沒有提供 Service 了,直接將 UserDao 注入到 Controller 中)。
@RestController
public class UserController {
@Autowired
UserDao userDao;
@PostMapping("/")
public void addUser() {
User user = new User();
user.setId(1);
user.setUsername("張三");
user.setAddress("深圳");
userDao.save(user);
}
@DeleteMapping("/")
public void deleteById() {
userDao.deleteById(1);
}
@PutMapping("/")
public void updateUser() {
User user = userDao.getOne(1);
user.setUsername("李四");
userDao.flush();
}
@GetMapping("/test1")
public void test1() {
List<User> all = userDao.findAll();
System.out.println(all);
}
@GetMapping("/test2")
public void test2() {
List<User> list = userDao.getUserByAddressEqualsAndIdLessThanEqual("廣州", 2);
System.out.println(list);
}
@GetMapping("/test3")
public void test3() {
User user = userDao.maxIdUser();
System.out.println(user);
}
}
如此之後,即可查詢到需要的數據。
好了,本文的重點是 Spring Boot 和 Jpa 的整合,這個話題就先說到這裏。
多說兩句
在和 Spring 框架整合時,如果用到 ORM 框架,大部分人可能都是首選 Hibernate,實際上,在和 Spring+SpringMVC 整合時,也可以選擇 Spring Data Jpa 做數據持久化方案,用法和本文所述基本是一樣的,Spring Boot 只是將 Spring Data Jpa 的配置簡化了,因此,很多初學者對 Spring Data Jpa 覺得很神奇,但是又覺得無從下手,其實,此時可以回到 Spring 框架,先去學習 Jpa,再去學習 Spring Data Jpa,這是給初學者的一點建議。
相關案例已經上傳到 GitHub,歡迎小夥伴們們下載:
掃碼關注松哥,公眾號後台回復 2TB,獲取松哥獨家 超2TB 學習資源
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※帶您來看台北網站建置,台北網頁設計,各種案例分享
※小三通物流營運型態?
※快速運回,大陸空運推薦?