寫在前面的
最近看了Kafka Summit上的這個分享,覺得名字很霸氣,標題直接沿用了。這個分享源於社區的,大體的意思今後Apache Kafka不再需要ZooKeeper。整個分享大約40幾分鐘。完整看下來感覺乾貨很多,這裏特意總結出來。如果你把這個分享看做是《三國志》的話,那麼姑且就把我的這篇看做是裴松之注吧:)
客戶端演進
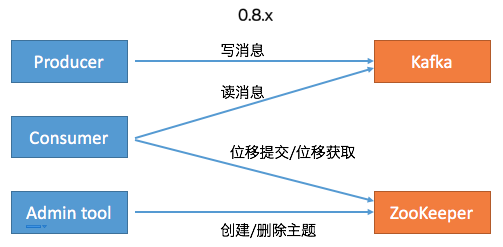
首先,社區committer給出了Kafka Java客戶端移除ZooKeeper依賴的演進過程。下面兩張圖總結了0.8.x版本和0.11.x版本(是否真的是從0.11版本開始的變化並不重要)及以後的功能變遷:在Kafka 0.8時代,Kafka有3個客戶端,分別是Producer、Consumer和Admin Tool。其中Producer負責向Kafka寫消息,Consumer負責從Kafka讀消息,而Admin Tool執行各種運維任務,比如創建或刪除主題等。其中Consumer的位移數據保存在ZooKeeper上,因此Consumer端的位移提交和位移獲取操作都需要訪問ZooKeeper。另外Admin Tool執行運維操作也要訪問ZooKeeper,比如在對應的ZooKeeper znode上創建一個臨時節點,然後由預定義的Watch觸發相應的處理邏輯。
後面隨着Kafka的演進,社區引入了__consumer_offsets位移主題,同時定義了OffsetFetch和OffsetCommit等新的RPC協議,這樣Consumer的位移提交和位移獲取操作全部轉移到與位移主題進行交互,避免了對ZooKeeper的訪問。同時社區引入了新的運維工具AdminClient以及相應的CreateTopics、DeleteTopics、AlterConfigs等RPC協議,替換了原先的Admin Tool,這樣創建和刪除主題這樣的運維操作也完全移動Kafka這一端來做,就像下面右邊這張圖展示的:
至此, Kafka的3個客戶端基本上都不需要和ZooKeeper交互了。應該說移除ZooKeeper的工作完成了大部分,但依然還有一部分工作要在ZooKeeper的幫助下完成,即Consumer的Rebalance操作。在0.8時代,Consumer Group的管理是交由ZooKeeper完成的,包括組成員的管理和訂閱分區的分配。這個設計在新版Consumer中也得到了修正。全部的Group管理操作交由Kafka Broker端新引入的Coordinator組件來完成。要完成這些工作,Broker端新增了很多RPC協議,比如JoinGroup、SyncGroup、Heartbeat、LeaveGroup等。
此時,Kafka的Java客戶端除了AdminClient還有一點要依賴ZooKeeper之外,所有其他的組件全部擺脫了對ZooKeeper的依賴。
之後,社區引入了Kafka安全層,實現了對用戶的認證和授權。這個額外的安全層也是不需要訪問ZooKeeper的,因此之前依賴ZooKeeper的客戶端是無法“享用”這個安全層。一旦啟用,新版Clients都需要首先接入這一層並通過審核之後才能訪問到Broker,如下圖所示:
這麼做的好處在於統一了Clients訪問Broker的模式,即定義RPC協議,比如我們熟知的PRODUCE協議、FETCH協議、METADATA協議、CreateTopics協議等。如果後面需要實現更多的功能,社區只需要定義新的RPC協議即可。同時新引入的安全層負責對這套RPC協議進行安全校驗,統一了訪問模式。另外這些協議都是版本化的(versioned),因此能夠獨立地進行演進,同時也兼顧了兼容性方面的考量。
Broker間交互
說完了Clients端,我們說下Broker端的現狀。目前,應該說Kafka Broker端對ZooKeeper是重度依賴的,主要表現在以下幾個方面:
- Broker註冊管理
- ACL安全層配置管理
- 動態參數管理
- 副本ISR管理
- Controller選舉
我們拿一張圖來說明,圖中有4個Broker節點和一個ZooKeeper,左上角的Broker充當Controller的角色。當前,所有的Broker啟動后都必須維持與ZooKeeper的會話。Kafka依賴於這個會話實現Broker端的註冊,而且Kafka集群中的所有配置信息、副本信息、主題信息也都保存在ZooKeeper上。最後Controller與集群中每個Broker都維持了一個TCP長連接用於向這些Broker發送RPC請求。當前的Controller RPC類型主要有3大類:
- LeaderAndIsr:主要用於向集群廣播主題分區Leader和ISR的變更情況,比如對應的Broker應該是特定分區的Leader還是Follower
- StopReplica:向集群廣播執行停止副本的命令
- UpdateMetadata:向集群廣播執行變更元數據信息的命令
圖中還新增了一個AlterISR RPC,這是KIP-497要實現的新RPC協議。現階段Kafka各個主題的ISR信息全部保存在ZooKeeper中。如果後續要捨棄ZooKeeper,必須要將這些信息從ZooKeeper中移出來,放在了Controller一端來做。同時還要在程序層面支持對ISR的管理。因此社區計劃在KIP-497上增加AlterISR協議。對了,還要提一句,當前Controller的選舉也是依靠ZooKeeper完成的。
所以後面Broker端的演進可能和Clients端的路線差不多:首先是把Broker與ZooKeeper的交互全部幹掉,只讓Controller與ZooKeeper進行交互,而其他所有Broker都只與Controller交互,如下圖所示:
看上去這種演進路線社區已經走得輕車熟路了,但實際上還有遺留了一些問題需要解決。
Broker Liveness
首先就是Broker的liveness問題,即Kafka如何判斷一個Broker到底是否存活?在目前的設計中,Broker的生存性監測完全依賴於與ZooKeeper之間的會話。一旦會話超時或斷開Controller自動觸發ZooKeeper端的Watch來移除該Broker,並對其上的分區做善後處理。如果移除了ZooKeeper,Kafka應該採用什麼機制來判斷Broker的生存性是一個問題。
Network Partition
如何防範網絡分區也是一個需要討論的話題。當前可能出現的Network Partition有4種:1、單個Broker完全與集群隔離;2、Broker間無法通訊;3、Broker與ZooKeeper無法通訊;4、Broker與Controller無法通訊。下面4張圖分別展示了這4種情況:
我們分別討論下。首先是第一種情況,單Broker與集群其他Broker隔離,這其實並不算太嚴重的問題。當前的設計已然能夠保證很好地應對此種情況。一旦Broker被隔離,Controller會將其從集群中摘除,雖然可用性降低了,但是整個集群的一致性依然能夠得到保證。第二種情況是Broker間無法通訊,可能的後果是消息的備份機制無法執行,Kafka要收縮ISR,依然是可用性上的降低,但是一致性狀態並沒有被破壞。情況三是Broker無法與ZooKeeper通訊。Broker能正常運轉,它只是無法與ZooKeeper進行通訊。此時我們說該Broker處於殭屍狀態,即所謂的Zoobie狀態。因Zoobie狀態引入的一致性bug社區jira中一直沒有斷過,社區這幾年也一直在修正這方面的問題,主要對抗的機制就是fencing。比如leader epoch等。最後一類情況是Broker無法與Controller通訊,那麼所有的元數據更新通道被堵死,即使這個Broker依然是healthy的,但是它保存的元數據信息可能是非常過期的。這樣連接該Broker的客戶端可能會看到各種非常古怪的問題。之前在知乎上回答過類似的問題:4。目前,社區對這種情況並沒有太好的解決辦法,主要的原因是Broker的liveness完全交由ZooKeeper來做的。一旦Broker與ZooKeeper之間的交互沒有問題,其他原因導致的liveness問題就無法徹底規避。
第四類Network Partition引入了一個經典的場景:元數據不一致。目前每個Broker都緩存了一份集群的元數據信息,這份數據是異步更新的。當第四類Partition發生時,Broker端緩存的元數據信息必然與Controller的不同步,從而造成各種各樣的問題。
下面簡要介紹一下元數據更新的過程。主要的流程就是Controller啟動時會同步地從ZooKeeper上拉取集群全量的元數據信息,之後再以異步的方式同步給其他Broker。其他Broker與Controller之間的同步往往有一個時間差,也就是說可能Clients訪問的元數據並不是最新的。我個人認為現在社區很多flaky test failure都是因為這個原因導致的。 事實上,實際使用過程中有很多場景是Broker端的元數據與Controller端永遠不同步。通常情況下如果我們不重啟Broker的話,那麼這個Broker上的元數據將永遠“錯誤”下去。好在社區還給出了一個最後的“大招”: 登錄到ZooKeeper SHELL,手動執行rmr /controller,強迫Controller重選舉,然後重新加載元數據,並給所有Broker重刷一份。不過在實際生產環境,我懷疑是否有人真的要這麼干,畢竟代價不小,而且最關鍵的是這麼做依然可能存在兩個問題:1. 我們如何確保Controller和Broker的數據是一致的?2. 加載元數據的過程通常很慢。
這裏詳細說說第二點,即加載元數據的性能問題。總體來說,加載元數據是一個O(N)時間複雜度的過程,這裏的N就是你集群中總的分區數。考慮到Controller從ZooKeeper加載之後還要推給其他的Broker,那麼做這件事的總的時間複雜度就是O(N * M),其中M是集群中Broker的數量。可以想見,當M和N都很大時,在集群中廣播元數據不是一個很快的過程。
Metadata as an Event Log
Okay,鑒於以上所提到的所有問題,當Kafka拋棄了ZooKeeper之後,社區應該如何解決它們呢?總體的思路就是Metadata as an Event Log + Controller quorum。我們先說metadata as an event log。如果你讀過Jay Kreps的《I ️Logs》,你應該有感觸,整個Kafka的架構其實都是構建在Log上的。每個topic的分區本質上就是一個Commit Log,但元數據信息的保存卻不是Log形式。在現有的架構設計中你基本上可以認為元數據的數據結構是KV形式的。這一次,社區採用了與消息相同的數據保存方式,即將元數據作為Log的方式保存起來,如下錶所示:
這樣做的好處在於每次元數據的變更都被當做是一條消息保存在Log中,而這個Log可以被視作是一個普通的Kafka主題被備份到多台Broker上。Log的一個好處在於它有清晰的前後順序關係,即每個事件發生的時間是可以排序的,配合以恰當的處理邏輯,我們就能保證對元數據變更的處理是按照變更發生時間順序處理,不出現亂序的情形。另外Log機制還有一個好處是,在Broker間同步元數據時,我們可以選擇同步增量數據(delta),而非全量狀態。現在Kafka Broker間同步元數據都是全量狀態同步的。前面說過了,當集群分區數很大時,這個開銷是很可觀的。如果我們能夠只同步增量狀態,勢必能極大地降低同步成本。最後一個好處是,我們可以很容易地量化元數據同步的進度,因為對Log的消費有位移數據,因此通過監控Log Lag就能算出當前同步的進度或是落後的進度。
採用Log機制后,其他Broker像是一個普通的Consumer,從Controller拉取元數據變更消息或事件。由於每個Broker都是一個Consumer,所以它們會維護自己的消費位移,就像下面這張圖一樣:
這種設計下,Controller所在的Broker必須要承擔起所有元數據topic的管理工作,包括創建topic、管理topic分區的leader以及為每個元數據變更創建相應的事件等。既然社區選擇和__consumer_offsets類似的處理方式,一個很自然的問題在於這個元數據topic的管理是否能夠復用Kafka現有的副本機制?答案是:不可行。理由是現有的副本機制依賴於Controller,因此Kafka沒法依靠現有的副本機制來實現Controller——按照我們的俗語來說,這有點雞生蛋、蛋生雞的問題,屬於典型的循環依賴。為了實現這個,Kafka需要一套leader選舉協議,而這套協議或算法是不依賴於Controller的,即它是一個自管理的集群quorum(抱歉,在分佈式領域內,特別是分佈式共識算法領域中,針對quorum的恰當翻譯我目前還未找到,因此直接使用quorum原詞了)。最終社區決定採用Raft來實現這組quorum。這就是上面我們提到的第二個解決思路:Controller quorum。
Controller Quorum
與藉助Controller幫忙選擇Leader不同,Raft是讓自己的節點自行選擇Leader並最終令所有節點達成共識——對選擇Controller而言,這是一個很好的特性。其實Kafka現有的備份機制與Raft已經很接近了,下錶羅列了一下它們的異同:
一眼掃過去,其實Kafka的備份機制和Raft很類似,比如Kafka中的offset其實就是Raft中的index,epoch對應於term。當然Raft中採用的半數機制來確保消息被提交以及Leader選舉,而Kafka設計了ISR機制來實現這兩點。總體來說,社區認為只需要對備份機製做一些小改動就應該可以很容易地切換到Raft-based算法。
下面這張圖展示Controller quorum可能更加直觀:
整個controller quorum類似於一個小的集群。和ZooKeeper類似,這個quorum通常是3台或5台機器,不需要讓Kafka中的每個Broker都自動稱為這個quorum中的一個節點。該quorum裏面有一個Leader負責處理客戶端發來的讀寫請求,這個Leader就是Kafka中的active controller。根據ZooKeeper的Zab協議,leader處理所有的寫請求,而follower是可以處理讀請求的。當寫請求發送給follower后,follower會將該請求轉發給leader處理。不過我猜Kafka應該不會這樣實現,它應該只會讓leader(即active controller)處理所有的讀寫請求,而客戶端(也就是其他Broker)壓根就不會發送讀寫請求給follower。在這一點上,這種設計和現有的Kafka請求處理機制是一致的。
現在還需要解決一個問題,即Leader是怎麼被選出來的?既然是Raft-based,那麼採用的也是Raft算法中的Leader選舉策略。讓Raft選出的Leader稱為active controller。網上有很多關於Raft選主的文章,這裏就不在贅述了,有興趣的可以讀一讀Raft的論文:《In Search of an Understandable Consensus Algorithm(Extended Version)》。
這套Raft quorum的一個好處在於它天然提供了低延時的failover,因此leader的切換會非常的迅速和及時,因為理論上不再有元數據加載的過程了,所有的元數據現在都同步保存follower節點的內存中,它已經有其他Broker需要拉取的所有元數據信息了!更酷的是,它避免了現在機制中一旦Controller切換要全量拉取元數據的低效行為,Broker無需重新拉取之前已經“消費”的元數據變更消息,它只需要從新Leader繼續“消費”即可。
另一個好處在於:採用了這套機制后,Kafka可以做元數據的緩存了(metadata caching):即Broker能夠把元數據保存在磁盤上,同時就像剛才說的,Broker只需讀取它關心的那部分數據即可。還有,和現在snapshot機制類似,如果一個Broker保存的元數據落後Controller太多或者是一個全新的Broker,Kafka甚至可以像Raft那樣直接發送一個snapshot文件,快速令其追上進度。當然大多數情況下,Broker只需要拉取delta增量數據即可。
Post KIP-500 Broker註冊
當前Broker啟動之後會向ZooKeeper註冊自己的信息,比如自己的主機名、端口、監聽協議等數據。移除ZooKeeper之後,Broker的註冊機制也要發生變化:Broker需要向active controller發送心跳來進行註冊。Controller收集心跳中包含的Broker數據構建整個Kafka集群信息,如下圖所示:
同時Controller也會對心跳進行響應,顯式地告知Broker它們是否被允許加入集群——如果不允許,則可能需要被隔離(fenced)。當然controller自己也可以對自己進行隔離。我們針對前面提到的隔離場景討論下KIP-500是怎麼應對的。
Fencing
首先是普通Broker與集群完全隔離的場景,比如該Broker無法與controller和其他Broker進行通信,但它依然可以和客戶端程序交互。此時,fencing機制就很簡單了,直接讓controller令其下線即可。這和現在依靠ZooKeeper會話機制維持Broker判活的機制是一模一樣的,沒有太大改進。
第二種情況是Broker間的通訊中斷。此時消息無法在leader、follower間進行備份。但是對於元數據而言,我們不會看到數據不一致的情形,因為Broker依然可以和controller通訊,因此也不會有什麼問題。
第三種情況是Broker與Controller的隔離。現有機制下這是個問題,但KIP-500之後,Controller僅僅將該Broker“踢出場”即可,不會造成元數據的不一致。
最後一種情況是Broker與ZooKeeper的隔離, 既然ZooKeeper要被移除了,自然這也不是問題了。
部署
終於聊到KIP-500之後的Kafka運維了。下錶總結了KIP-500前後的部署情況對比:
很簡單,現在任何時候部署和運維Kafka都要考慮對ZooKeeper的運維管理。在KIP-500之後我們只需要關心Kafka即可。
Controller quorum共享模式
如前所述,controller改成Raft quorum機制后,可能使用3或5台機器構成一個小的quorum。那麼一個很自然的問題是,這些Broker機器還能否用作他用,是唯一用作controller quorum還是和其他Broker一樣正常處理。社區對此也做了解釋:兩種都支持!
如果你的Kafka集群資源很緊張,你可以使用共享controller模式(Shared Controller Mode),即充當controller quorum的Broker機器也能處理普通的客戶端請求;相反地,如果你的Kafka資源很充足,專屬controller模式(Separate Controller Mode)可能是更適合的,即在controller quorum中的Broker機器排它地用作Controller的選舉之用,不再對客戶端提供讀寫服務。這樣可以實現更好的資源隔離,適用於大集群。
Roadmap
最後說一下KIP-500的計劃。社區計劃分三步走:
第一步是移除客戶端對ZooKeeper的依賴——這一步基本上已經完成了,除了目前AdminClient還有少量的API依賴ZooKeeper之外,其他客戶端應該說都不需要訪問ZooKeeper了;第二步是移除Broker端的ZooKeeper依賴:這主要包括移除Broker端需要訪問ZooKeeper的代碼,以及增加新的Broker端API,如前面所說的AlterISR等,最後是將對ZooKeeper的訪問全部集中在controller端;最後一步就是實現controller quorum,實現Raft-based的quorum負責controller的選舉。
至於Kafka升級,如果從現有的Kafka直接升級到KIP-500之後的Kafka會比較困難,因此社區打算引入一個名為Bridge Release的中間過渡版本,如下圖所示:
這個Bridge版本的特點在於所有對ZooKeeper的訪問都集中到了controller端,Broker訪問ZooKeeper的其他代碼都被移除了。
總結
KIP-500應該說是最近幾年社區提出的最重磅的KIP改進了。它幾乎是顛覆了Kafka已有的使用模式,摒棄了之前重度依賴的Apache ZooKeeper。就我個人而言,我是很期待這個KIP,後續有最新消息我也會在一併同步出來。讓我們靜觀其變吧~~~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※大陸寄台灣空運注意事項
※大陸海運台灣交貨時間多久?
※避免吃悶虧無故遭抬價!台中搬家公司免費估價,有契約讓您安心有保障!